
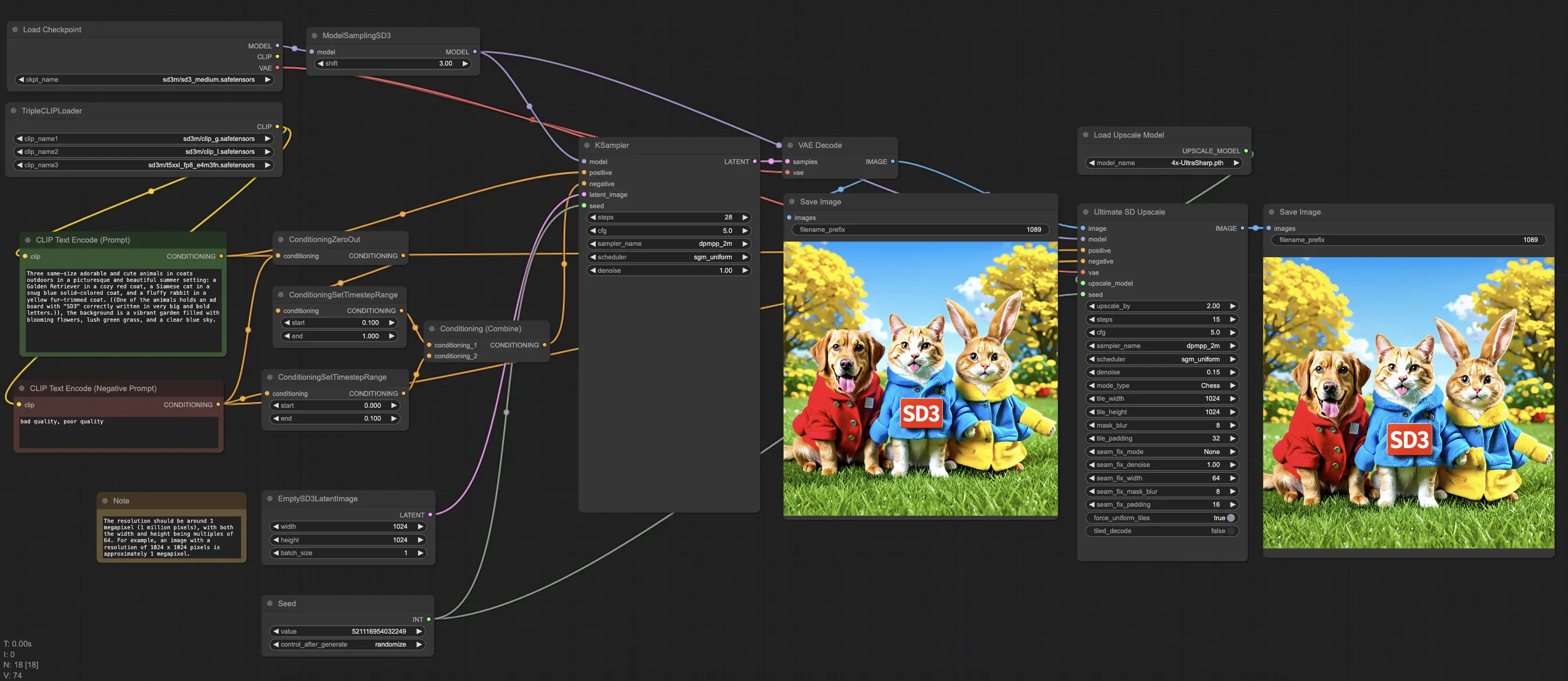



1. 使用 ComfyUI Stable Diffusion 3 提升您的創意流程#
🌟🌟🌟Stable Diffusion 3 中間模型及其相關節點現已預載於 RunComfy 的 ComfyUI Beta 版本(版本 24.06.13.0)中!!!🌟🌟🌟 您可以直接在此 ComfyUI 工作流程中使用 Stable Diffusion 3 中間模型,或將其無縫整合到您現有的 ComfyUI 工作流程中。
ComfyUI Stable Diffusion 3 工作流程包含所有必要的 Stable Diffusion 3 中間模型。只需嘗試不同的提示或參數即可體驗!
1.1. ComfyUI 中預載的 Stable Diffusion 3 中間模型#
sd3_medium.safetensors:包括 MMDiT 和 VAE 權重,但不包括任何文本編碼器。sd3_medium_incl_clips_t5xxlfp16.safetensors:包含所有必要的權重,包括 T5XXL 文本編碼器的 fp16 版本。sd3_medium_incl_clips_t5xxlfp8.safetensors:包含所有必要的權重,包括 T5XXL 文本編碼器的 fp8 版本,在質量和資源需求之間達到平衡。sd3_medium_incl_clips.safetensors:包括所有必要的權重,但不包括 T5XXL 文本編碼器。此版本需要的資源最少,但在沒有 T5XXL 文本編碼器的情況下,模型的性能會有所不同。text_encoders文件夾包含三個文本編碼器及其原始模型卡鏈接,方便用戶使用。此文件夾內的所有組件(及其嵌入其他包中的等效物)均受其各自原始許可的約束。
1.2 Stable Diffusion 3 中間模型的整體質量和寫實性#
Stable Diffusion 3 中間模型為 AI 藝術社群設立了新的圖像質量標準。此模型提供的圖像細節豐富,顏色準確,光照逼真。以下是您可以期待的效果:
- 細節與解析度:增強的能力可以呈現精緻的細節,非常適合特寫鏡頭和複雜的構圖。
- 顏色與光照:改進的算法確保顏色鮮豔且真實,動態光效增添了圖像的深度和寫實性。
- 人臉和手部的寫實性:常見的變形問題如手部和面部的扭曲顯著減少,這要歸功於如 16 通道變分自編碼器(VAE)等創新技術。
1.3 Stable Diffusion 3 中間模型的提示理解#
SD3 中間模型的一大亮點是其複雜提示的理解能力。此模型能夠解釋涉及空間推理、構圖元素、動作和風格的長篇提示。以下是一些重點:
- 文本編碼器:使用三個文本編碼器以平衡性能和效率。這使得對詳細提示的理解和執行更加細膩。
- 構圖意識:能夠保持空間關係,準確描繪所描述的場景,非常適合通過視覺講述故事。
1.4 Stable Diffusion 3 中間模型的排版能力#
排版一直是文字生成圖像中的一大挑戰。SD3 中間模型在這方面取得了非凡的成功:
- 文字質量:在拼寫、字距調整、字母形成和間距方面達到前所未有的準確性。
- 擴散變壓器架構:這一先進的架構使圖像內文字的呈現更加精確,減少錯誤並提高視覺一致性。
1.5 Stable Diffusion 3 中間模型的資源效率#
儘管具備先進功能,SD3 中間模型設計上注重資源效率:
- 低 VRAM 佔用:可以在普通消費者 GPU 上運行而不影響性能,使高品質 AI 藝術更加普及。
- 效率優化:在計算需求和輸出質量之間保持平衡,確保即使在較不強大的硬件上也能順利運行。
1.6 Stable Diffusion 3 中間模型的微調能力#
定制化是 AI 藝術家的一個關鍵方面,SD3 中間模型在這方面表現出色:
- 吸收細微細節:能夠用小數據集進行微調,允許藝術家印上其獨特風格或滿足特定項目需求。
- 多功能性:無論您是在處理特定主題、風格或細節,SD3 中間模型都提供了個性化藝術品所需的靈活性。
2. 什麼是 Stable Diffusion 3#
Stable Diffusion 3 是一款尖端的 AI 模型,專為從提示生成圖像而設計。它是 Stable Diffusion 系列的第三代,旨在提供更高的準確性,更好地遵循提示的細微差別,以及比早期版本和其他模型如 DALL·E 3、Midjourney v6 和 Ideogram v1 更優越的視覺美學。
3. Stable Diffusion 3 模型#
Stable Diffusion 3 提供三種不同的模型,每種模型都是為滿足不同需求和計算能力而設計的:
3.1. Stable Diffusion 3 中間模型#
🌟🌟🌟 直接整合到此工作流程中 🌟🌟🌟
- 參數:20 億
- 主要特點:
- 高品質寫實圖像
- 複雜提示的高級理解
- 優越的排版能力
- 資源效率高,適合消費者 GPU
- 適合小數據集的微調
3.2. Stable Diffusion 3 大型模型#
可通過 Stability AI Developer Platform API
- 參數:80 億
- 主要特點:
- 提升的圖像質量和細節
- 更強的處理複雜提示和風格的能力
- 理想的專業級項目,需高解析度和保真度
3.3. Stable Diffusion 3 大型 Turbo#
可通過 Stability AI Developer Platform API
- 參數:80 億(優化推理時間)
- 主要特點:
- 與 SD3 大型模型相同的高性能
- 推理速度更快,適合即時應用和快速原型設計
4. Stable Diffusion 3 的技術架構#
Stable Diffusion 3 的核心是多模態擴散變壓器(MMDiT)架構。這一創新框架增強了模型處理和整合文本與視覺信息的能力。與其前身使用單一神經網絡權重集處理圖像和文本不同,Stable Diffusion 3 為每種模態使用單獨的權重集。這種分離允許更專門地處理文本和圖像數據,從而改善生成圖像中的文本理解和拼寫。
4.1. MMDiT 架構的組成部分#
- 文本嵌入器:Stable Diffusion 3 使用三個文本嵌入模型的組合,包括兩個 CLIP 模型和 T5,將文本轉換為 AI 能夠理解和處理的格式。
- 圖像編碼器:使用增強的自編碼模型將圖像轉換為適合 AI 操作並生成新視覺內容的形式。
- 雙變壓器方法:該架構設有兩個獨立的文本和圖像變壓器,這些變壓器獨立運行但在注意操作中相互連接。這種設置允許兩種模態相互直接影響,增強文本輸入和圖像輸出之間的一致性。
5. Stable Diffusion 3 的新特性和改進#
- 遵循提示:SD3 在緊密遵循用戶提示的具體要求方面表現出色,特別是在涉及複雜場景或多主題的情況下。這種對詳細提示的理解和呈現的精確性使其超越其他領先模型,如 DALL·E 3、Midjourney v6 和 Ideogram v1,使其在需要嚴格遵循指示的項目中高度可靠。
- 圖像中的文字:憑藉其先進的多模態擴散變壓器(MMDiT)架構,SD3 大大提高了圖像內文字的清晰度和可讀性。通過使用單獨的權重集處理圖像和語言數據,該模型實現了卓越的文本理解和拼寫準確性。這比早期版本的 Stable Diffusion 有了顯著改進,解決了文字生成圖像 AI 應用中的常見挑戰。
- 視覺質量:SD3 不僅匹配了其競爭對手生成的圖像質量,而且在許多情況下超越了它們。生成的圖像不僅美觀,而且能夠高度忠實於提示,這要歸功於模型對文本描述的解釋和視覺化能力的精細化。這使得 SD3 成為尋求卓越視覺美學效果的用戶的首選。

如需了解有關此模型的詳細資訊,請訪問 Stable Diffusion 3 的研究論文,Github








