
Janus-Pro 是一個最前沿的自回歸框架,統一了多模態理解和生成,解決了以往方法的關鍵限制。通過將視覺編碼分解為獨立的路徑,同時維持單一的 transformer 架構,Janus-Pro 消除了感知和合成之間的衝突,增強了多模態 AI 的靈活性和性能。使用 Janus-Pro,使用者可以在視覺理解和內容生成之間達到更精細的平衡,使 Janus-Pro 成為下一代 AI 解決方案的最佳選擇。
Janus-Pro 設計的核心是其創新的雙路徑視覺編碼策略,這使得 Janus-Pro 能夠更有效地處理視覺輸入,而不犧牲其生成能力。不同於傳統的統一模型在理解和生成之間的平衡上掙扎,Janus-Pro 通過為它們分配專用的編碼路徑來優化這兩個任務,同時仍然利用單一強大的 transformer 進行處理。這種方法使 Janus-Pro 能夠在從圖像合成到文本引導生成的多樣化多模態任務中無縫適應,加強了 Janus-Pro 超越現有 AI 框架的能力。
統一多模態模型的一個主要挑戰是保持高性能,涵蓋廣泛的任務範圍,而不需要任務專用的架構。Janus-Pro 憑藉其簡化但高度適應性的框架克服了這一挑戰,超越了以往的統一模型,甚至匹配或超越了專用任務解決方案的性能。憑藉其簡單性、靈活性和卓越的效果,Janus-Pro 代表了多模態 AI 的一個重要進步。Janus-Pro 正在為下一代統一模型設立新的基準,證明 Janus-Pro 是多模態 AI 技術的未來。
1.1 如何使用 Janus-Pro 工作流程?#
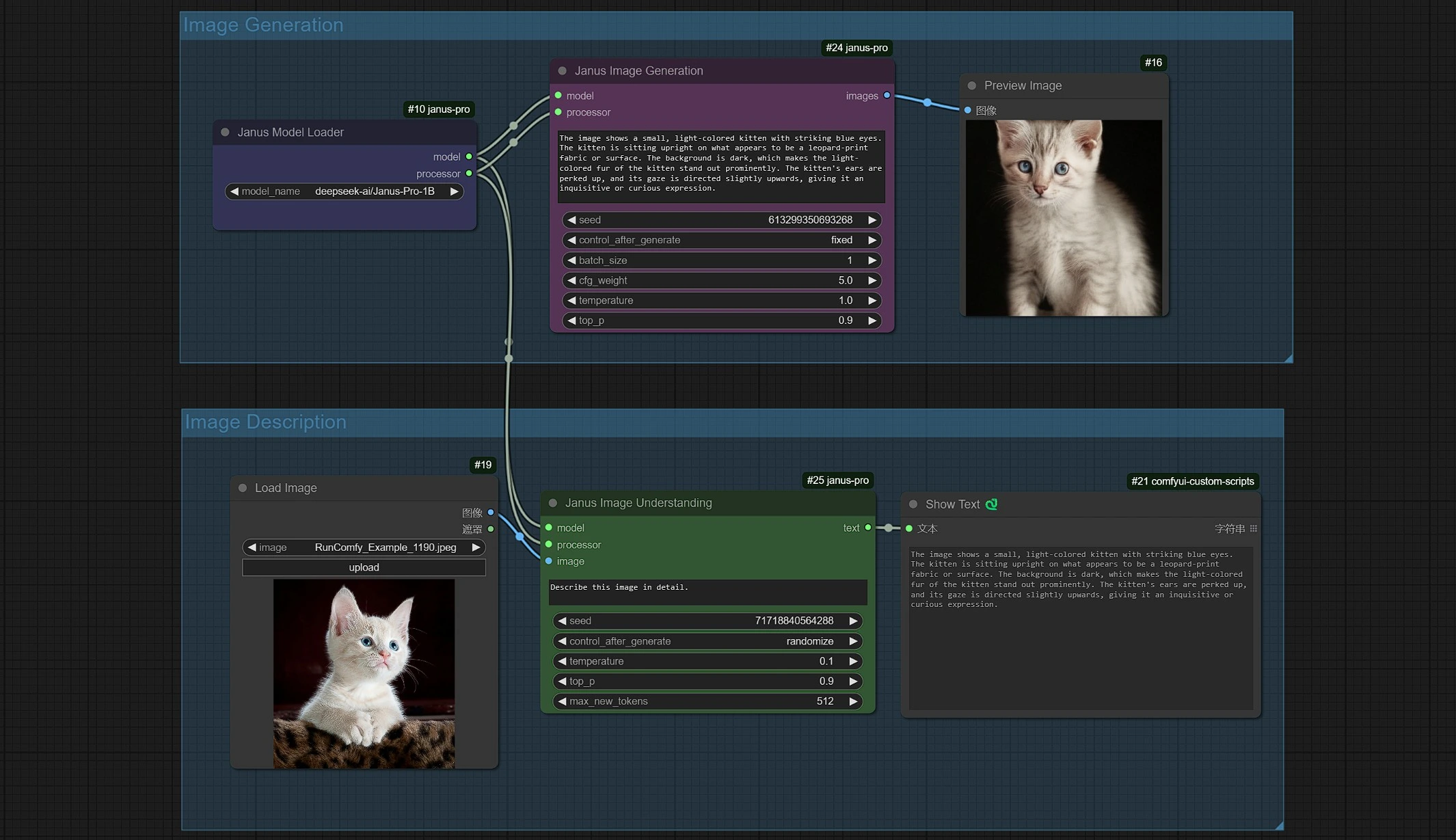
您可以以兩種方式使用 Janus-Pro 工作流程
- Janus-Pro 圖像生成
- Janus-Pro 圖像描述 (OCR, Captions, Describe...etc)
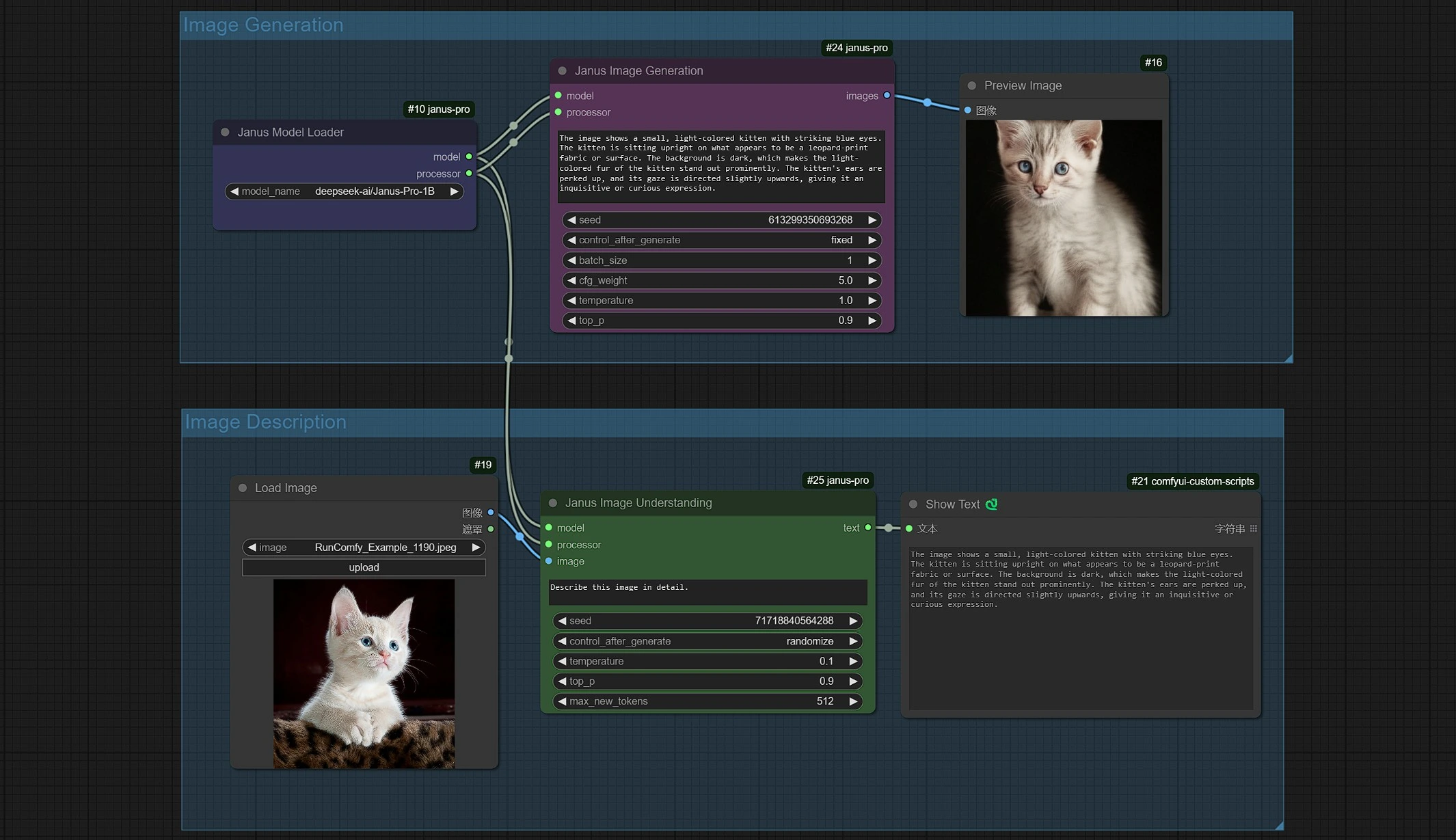
1.2 Janus-Pro 圖像生成#
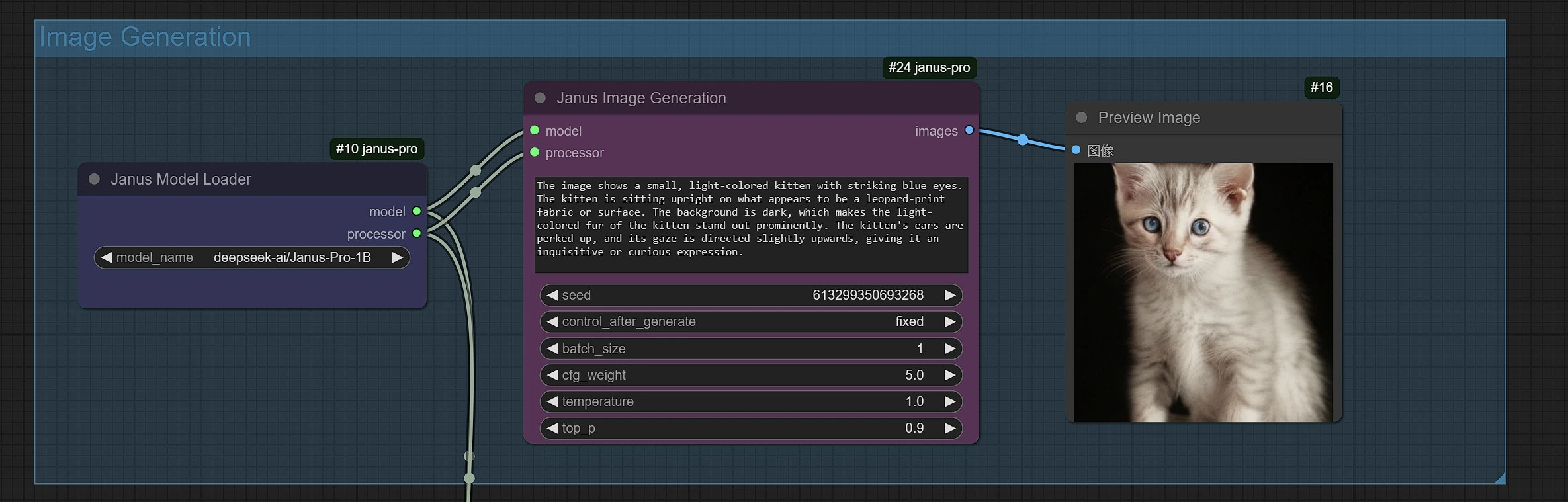
- Janus 圖像生成取樣器讓您輸入提示。
- 您可以使用 Janus-Pro-1B 或 Janus-Pro-7B 模型。
- Janus-Pro 圖像生成目前限制為 1:1 方形(384*384 px)比例。
Janus-Pro 模型將在您首次運行時自動下載到您的雲端 runcomfy 機器上。首次排隊時可能需要 2-5 分鐘。 模型連結 -
- Janus-Pro-1B - https://huggingface.co/deepseek-ai/Janus-Pro-1B
- Janus-Pro-7B - https://huggingface.co/deepseek-ai/Janus-Pro-7B
模型將下載到:Comfyui/models/Janus-Pro
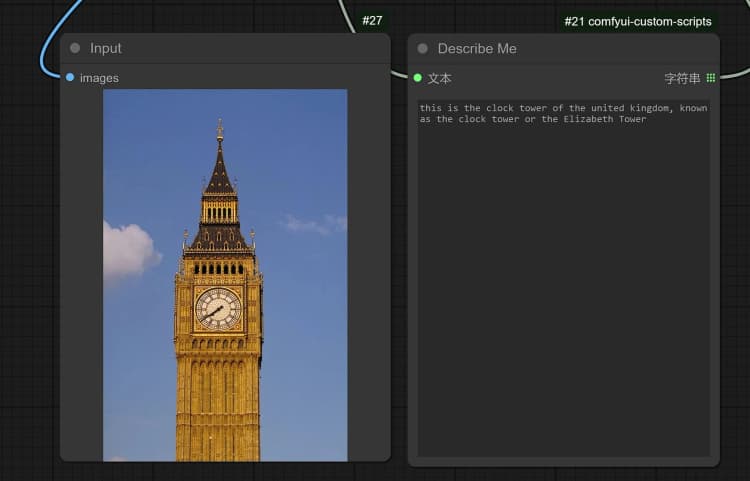
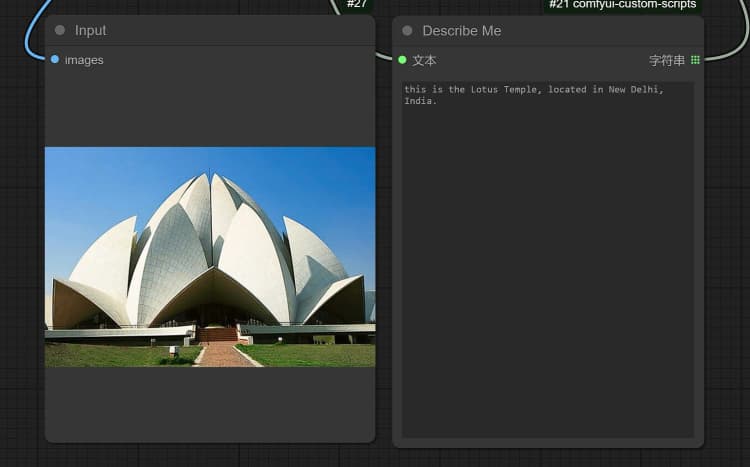
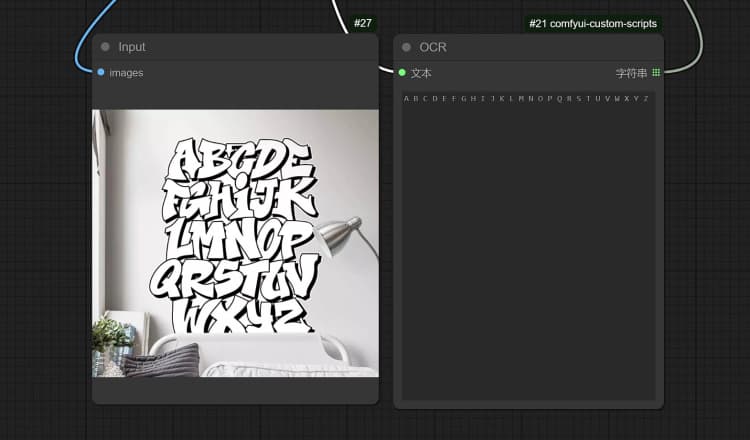
1.3 Janus-Pro 圖像描述#
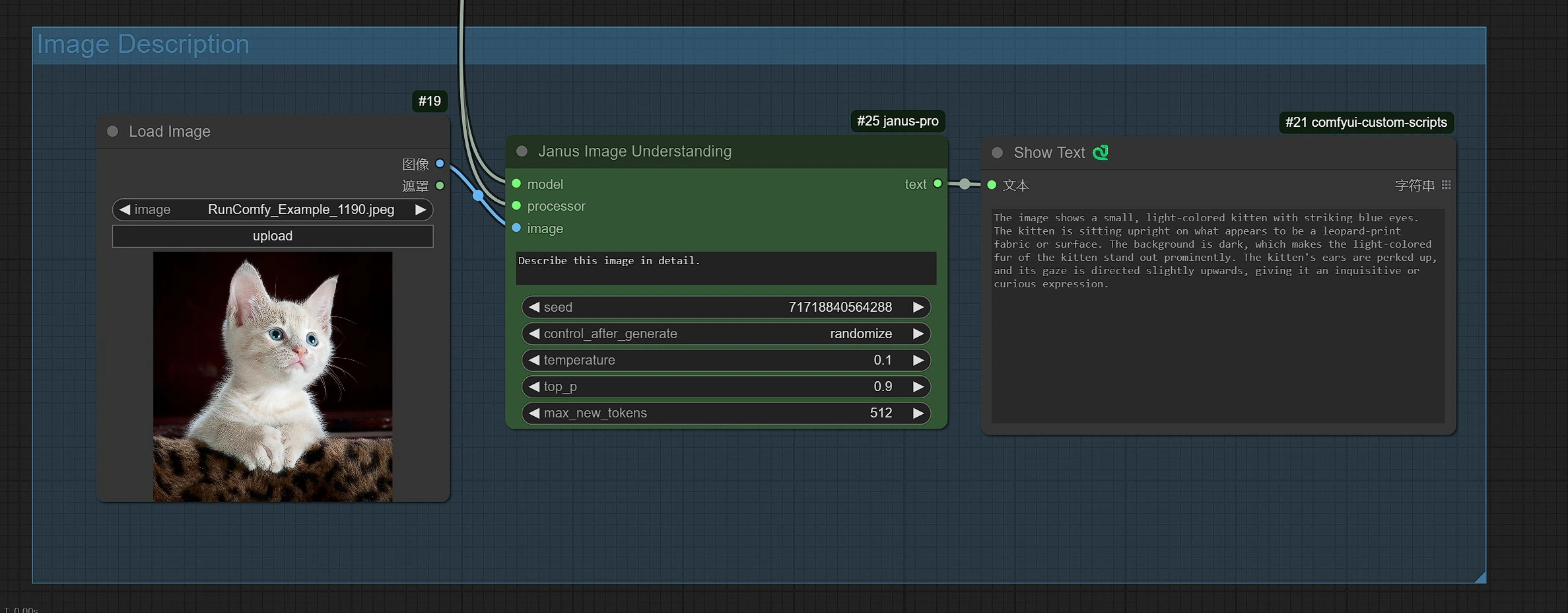
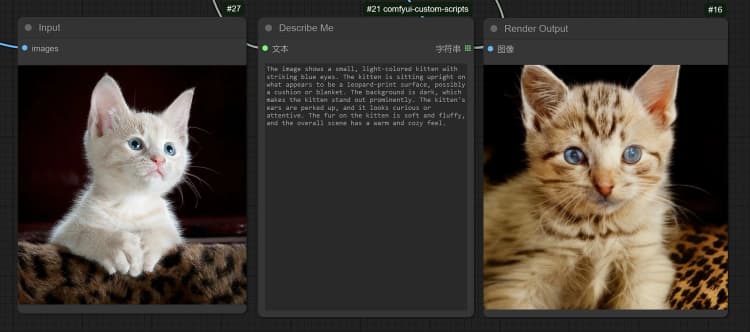
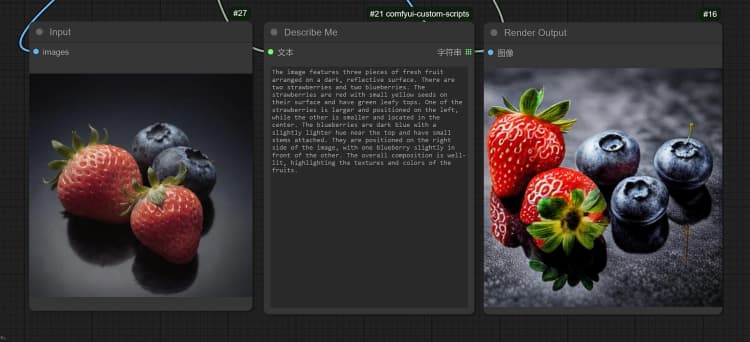
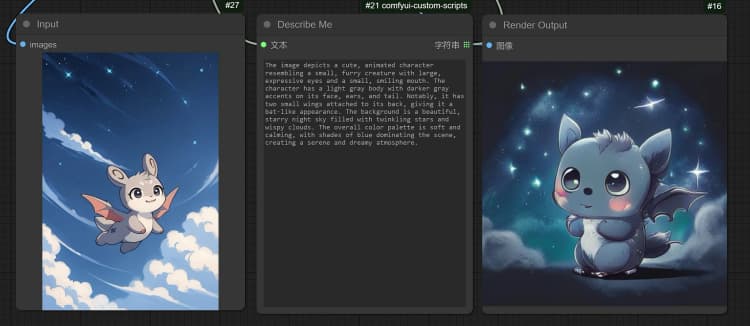
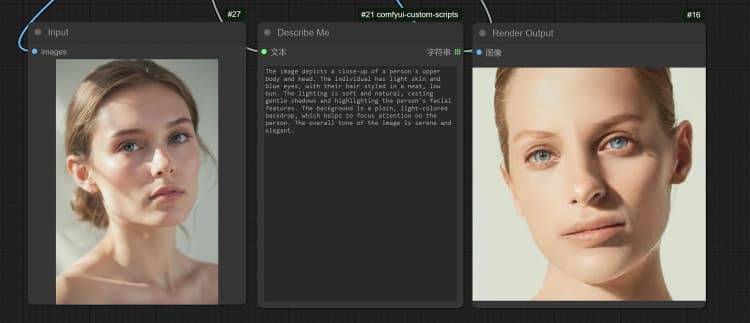
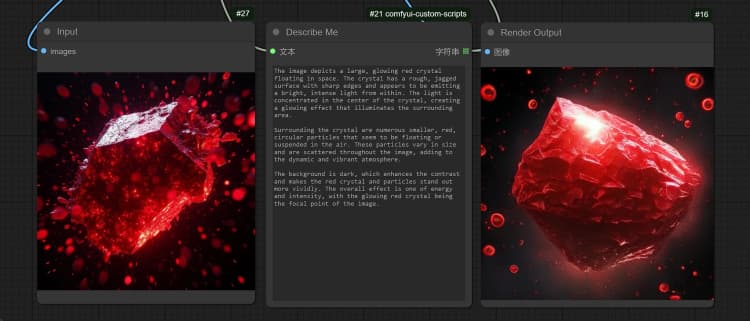
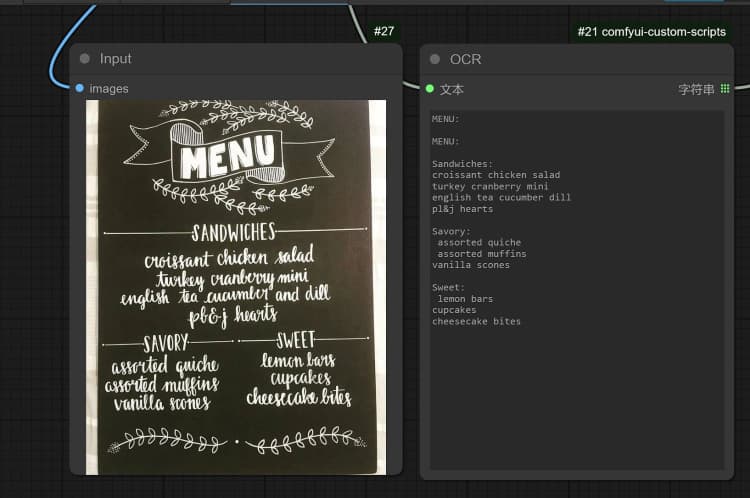
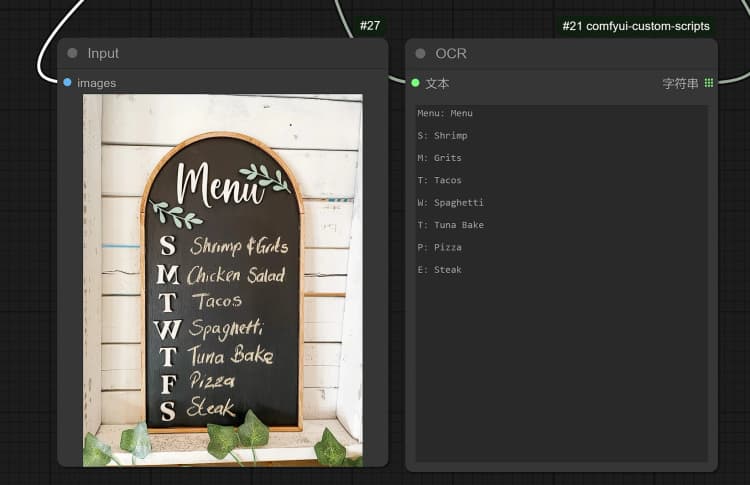
- 單擊並上傳圖像到加載圖像節點以進行 Janus-Pro 處理。
- 您可以使用 Janus-Pro 圖像理解節點執行:OCR, Captions, Detailed Description。只需在節點提供的類型框中輸入您的請求。
示例問題: “詳細描述這張圖像,這是在哪裡,裡面寫了什麼……等。”
Janus-Pro 通過將理解和生成無縫整合在統一框架內,為多模態 AI 設立了新標準。Janus-Pro 創新的雙路徑編碼增強了靈活性,解決了傳統模型的衝突。通過超越以前的統一架構並與任務專用解決方案競爭,Janus-Pro 為更高效和多功能的 AI 系統鋪平了道路。作為一個強大且適應性強的框架,Janus-Pro 處於下一代多模態智能的前沿,證明 Janus-Pro 是多模態 AI 的未來。



