
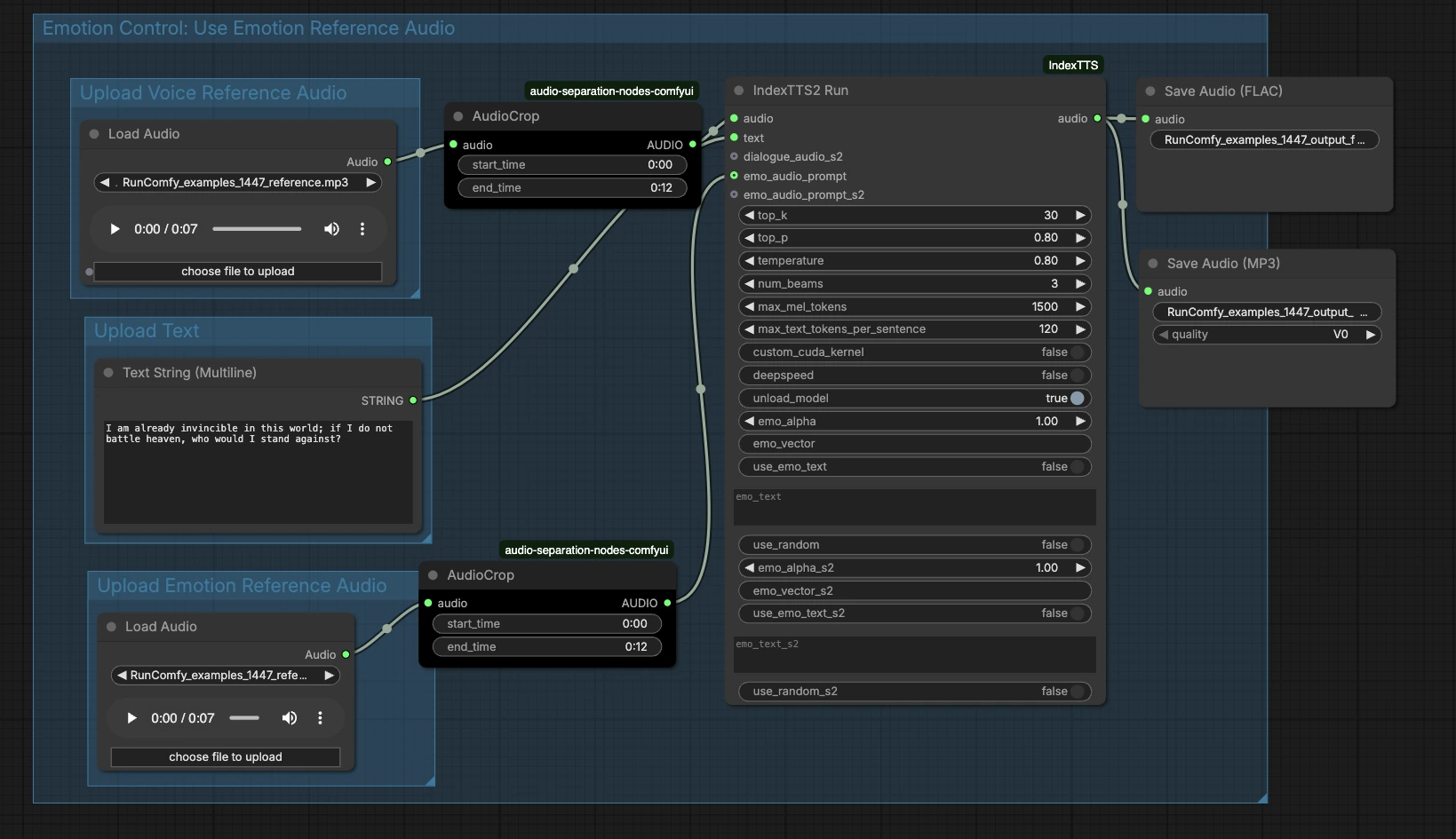
IndexTTS2 ComfyUI 工作流程:使用參考音頻進行情感語音克隆#
這個 IndexTTS2 ComfyUI 工作流程將短音頻片段轉化為自然、富有表情的語音,匹配說話者的音色和風格。您提供乾淨的參考音頻、可選的情感提示和您的腳本;圖表生成高品質的語音克隆,並以 FLAC 格式導出以供存檔使用或以 MP3 格式快速分享。
這個工作流程圍繞 IndexTTS‑2 模型和 ComfyUI IndexTTS 節點構建,非常適合希望快速、可重複情感 TTS 的創作者、角色設計師、教育工作者和 RunComfy 用戶。所有操作都在 ComfyUI 內部進行,因此您可以檢查輸入、調整設置,並快速迭代旁白、對話和配音示例。
Comfyui IndexTTS2 ComfyUI 工作流程中的關鍵模型#
- IndexTTS‑2 由 IndexTeam 開發。一個現代的文本轉語音系統,能夠進行參考條件語音克隆和表達性韻律控制。它基於短的說話者示例和可選的情感提示來從文本生成自然語音。請參閱 Hugging Face 上的模型卡和附帶的論文以獲取架構和訓練細節:IndexTTS‑2,IndexTTS 項目,IndexTTS‑2 論文。
如何使用 Comfyui IndexTTS2 ComfyUI 工作流程#
在高層次上,圖表需要三個輸入——參考音色音頻、文本和可選的情感音頻——然後進行生成並導出結果。以下組展示了添加輸入的位置以及它們如何連接到最終語音。
上傳語音參考音頻#
此組準備說話者的身份。將目標語音的乾淨樣本加載到 LoadAudio (#13),理想情況下是一個清晰說話且沒有音樂或效果的單一說話者。使用 AudioCrop (#37) 隔離一個穩定的片段,以便系統學習一致的音色。具有穩定音高和中性表達的短片段通常會產生最可靠的克隆。裁剪的參考被轉發以調節生成器。
上傳文本#
在 PrimitiveStringMultiline (#14) 中輸入您的腳本。清晰的標點符號有助於模型推斷停頓和重音,因此請按照您希望被說出的方式撰寫文本。如果您計劃進行多句閱讀,請保持每個句子結構完整,避免使用表情符號或不常見的符號。文本直接流入合成節點進行渲染。
上傳情感參考音頻#
提供一個可選的片段,捕捉您想要的情感或表達方式——例如激動、冷靜或憂鬱——通過 LoadAudio (#15)。使用 AudioCrop (#38) 修剪以保留您想要模仿的表達部分。這與音色參考分開,專注於節奏、能量和音調。如果跳過此步驟,IndexTTS2 ComfyUI 工作流程將僅依賴文本進行韻律。
情感控制:使用情感參考音頻#
此區域將您的情感提示連接到生成器。裁剪的情感片段將情感音頻提示饋送到 IndexTTS2Run (#12) 的輸入,指導節奏和強度,同時保持目標語音。如果您沒有情感音頻示例,還可以使用節點的情感文本控件來微調風格。實踐中,情感音頻往往提供更強、更一致的表達性,而情感文本則提供較輕的引導。當您想要具體示例和文本提示時將它們結合使用。
生成和導出#
IndexTTS2Run (#12) 使用您的文本、音色參考和任何情感指導合成語音。輸出路由到 SaveAudio (#17) 以獲取無損 FLAC,並路由到 SaveAudioMP3 (#39) 以獲取小型、適合網絡的預覽。使用保存節點上的文件名字段在迭代過程中保持錄音井然有序。此設計使得在保持相同說話者身份的同時輕鬆 A/B 測試不同的文本或情感。
Comfyui IndexTTS2 ComfyUI 工作流程中的關鍵節點#
IndexTTS2Run (#12)#
這是包裝 IndexTTS‑2 的核心生成器,並公開了採樣、束搜索和情感調節的控制。調整 top_p、top_k 和 temperature 以平衡穩定性和多樣性——較低的值提供更一致的閱讀,較高的值增加自發性。使用 num_beams 當您希望節點搜索更多候選讀數時,交換速度以獲取質量。對於長腳本,max_mel_tokens 和 max_text_tokens_per_sentence 通過限制音頻和文本塊大小來幫助防止超出。情感可以通過 emo_audio_prompt、emo_alpha 來引導混合強度,或者使用 use_emo_text 和 emo_text 當您更喜歡文本提示時。根據您的硬件,提供了 deepspeed、custom_cuda_kernel 和 unload_model 等性能幫助器。節點實現由 ComfyUI IndexTTS 自訂節點提供:ComfyUI_IndexTTS,基礎模型在此記錄:IndexTTS‑2,IndexTTS 項目。
AudioCrop (#37) — 參考音色#
使用此節點從您的說話者樣本中隔離乾淨、穩定的摘錄。避免背景噪音、笑聲或極端情感,因為這些細節可能滲入克隆的語音中。裁剪到一致的音調可改善身份鎖定並減少不需要的工件。
AudioCrop (#38) — 情感提示#
此裁剪選擇控制交付的表達提示。選擇具有您想要的準確節奏或強度的部分,保持簡潔以避免稀釋信號。為了獲得最佳的一致性,盡可能使用與音色參考相同的說話者的情感提示。
可選附加功能#
- 保持參考音頻乾燥和單聲道;去除混響、背景音樂和重壓縮以獲得更乾淨的克隆。
- 有意標點。逗號、句號和問號幫助模型放置停頓和重音以匹配您的意圖。
- 為了可重複的錄音,在節點中禁用隨機性或保留關於文本和音頻選擇的筆記,以便您可以稍後重新生成相同的輸出。
- 如果 VRAM 緊張,啟用運行之間的模型卸載;它可能會增加少量時間成本但釋放其他圖表的內存。
- 尊重語音權利。僅使用您有權克隆的參考錄音,並在需要時披露合成語音。
致謝#
此工作流程實施並建立在以下工作和資源之上。我們對 RunningHub 提供的工作流程參考,RunComfy 提供的 Cloud Save 工作流程,Index Team 提供的 IndexTTS 和 IndexTTS-2,IndexTTS2 論文的作者,以及 billwuhao 提供的 ComfyUI IndexTTS 自訂節點的貢獻和維護表示感謝。欲了解權威詳情,請參考以下鏈接的原始文檔和存儲庫。
資源#
- RunningHub/Workflow Reference
- 文件/發佈說明:RunningHub post
- RunComfy/Cloud Save Workflow
- 文件/發佈說明:RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/Paper
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
注意:所引用的模型、數據集和代碼的使用受制於其作者和維護者提供的各自許可和條款。