
Hallo2技術由來自復旦大學和百度公司的Jiahao Cui、Hui Li、Yao Yao、Hao Zhu、Hanlin Shang、Kaihui Cheng、Hang Zhou、Siyu Zhu和Jingdong Wang開發。欲了解更多信息,請訪問Hallo2 GitHub。ComfyUI_Hallo2節點和工作流程由smthemex開發。欲了解更多詳情,請訪問ComfyUI_Hallo2 GitHub。所有貢獻均歸功於他們。
1. 關於Hallo2#
Hallo2是一個前沿模型,用於生成高品質、長時間、4K解析度的音頻驅動肖像動畫視頻。它基於原始Hallo模型進行了多項重要改進:
- 支持生成更長的視頻,長達數十分鐘甚至數小時
- 生成4K解析度的視頻
- 除了音頻外,還可以使用文本提示控制表情和姿勢
Hallo2通過使用先進技術,如數據增強來保持長時間的一致性,對4K解析度的潛在編碼進行矢量量化,並改進了由音頻和文本指導的去噪過程來實現這些目標。
2. Hallo2的技術特點#
Hallo2結合了多個先進的AI模型和技術來創建其高品質的肖像視頻:
- 擴散模型:這是生成視頻幀的核心 "引擎"。它從隨機噪聲開始,逐漸細化以符合所需的輸出,由音頻和文本提示指導。
- 3D U-Net:這是一種神經網絡,在擴散過程中充當 "雕刻家"。它查看當前的噪聲幀、音頻和文本指令,並建議如何更改噪聲以使其更像最終的肖像。
- 音頻編碼器:Hallo2使用名為Wav2Vec2的模型作為其 "耳朵" 來理解音頻,將原始波形轉換為緊湊的表示,捕捉音調、速度和語音內容。
- 人臉檢測器:為了幫助專注於動畫面部,Hallo2使用人臉檢測模型自動定位參考圖像中的肖像面部。然後它知道在哪裡應用唇部和表情運動。
- 圖像壓縮器:為了高效處理高分辨率4K圖像,Hallo2使用一種特殊的自編碼器模型(VQ-VAE)將其壓縮為較小的 "潛在" 表示,然後在最後解碼回4K。這就像JPEG如何縮小圖像文件大小而保持質量。
- 增強技巧:為了在長視頻中保持質量,Hallo2在使用先前生成的幀影響下一幀之前,應用一些巧妙的 "數據增強"。這些包括偶爾擦除隨機塊或添加微妙的噪聲。這有助於防止累積錯誤,否則可能會隨時間推移而損壞一致性。
總之,Hallo2接收音頻和肖像圖像,通過AI "代理" 雕刻視頻幀,使其與它們匹配,同時保持原始肖像的真實性,並採用一些額外的技巧來保持一切同步和一致,即使在長視頻中。所有這些部分在多步驟管道中共同工作以產生令人印象深刻的結果。
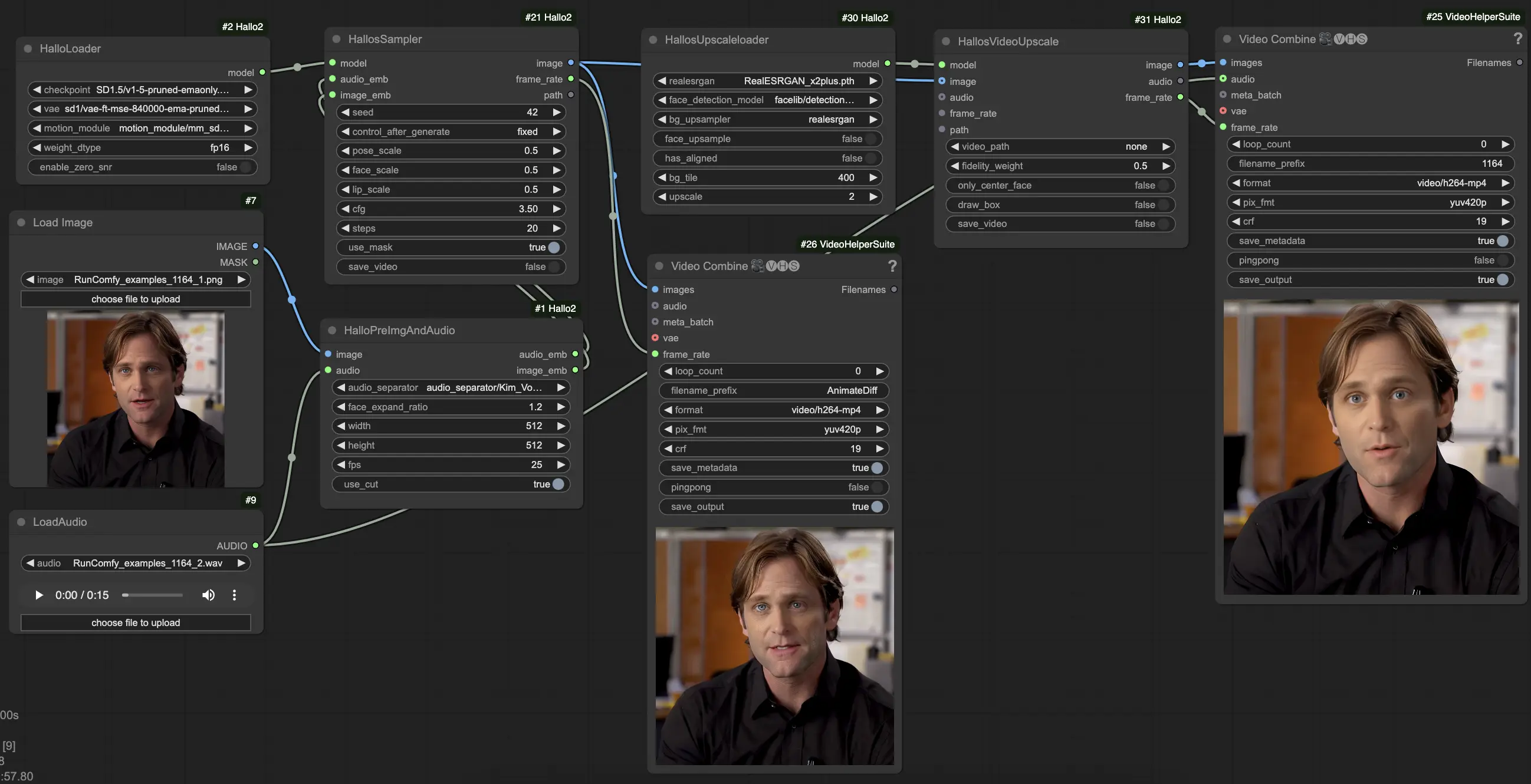
3. 如何使用ComfyUI Hallo2工作流程#
Hallo2已通過自定義工作流程和多個專用節點集成到ComfyUI中。以下是使用方法:
- 使用
LoadImage節點加載您的參考肖像圖像。這應該是一個清晰的正面肖像。(提示:參考肖像框架和光線越好,效果越好。避免側面輪廓、遮擋、繁忙的背景等。) - 使用
LoadAudio節點加載您的驅動音頻。它應匹配您希望肖像表達的情緒。 - 將圖像和音頻連接到
HalloPreImgAndAudio節點。這會將圖像和音頻預處理為嵌入。關鍵參數:audio_separator:用於將語音與背景噪聲分離的模型。通常保持默認。face_expand_ratio:面部檢測區域的擴展比例。較高的值包括更多的頭髮/背景。width/height:生成解析度。較高的值較慢但更詳細。512-1024平方是個不錯的平衡。fps:目標視頻FPS。25是一個不錯的默認值。
- 使用
HalloLoader節點加載核心Hallo2模型。指向您的Hallo2檢查點、VAE和運動模塊文件。 - 將預處理的圖像和音頻嵌入以及加載的模型連接到
HalloSampler節點。這執行實際的視頻生成。關鍵參數:seed:隨機種子,決定細節。若不喜歡第一個結果,請更改。pose_scale/face_scale/lip_scale:控制姿勢、面部表情和唇部運動的強度。1.0 = 完全強度,0.0 = 靜止。cfg:無分類指導比例。較高 = 更緊密地遵循條件,但多樣性較低。steps:去噪步驟數。步驟越多,質量越好,但速度較慢。
- 此時,您可以查看生成的視頻。要進一步提高質量,可以在鏈的末尾添加
HallosUpscaleloader和HallosVideoUpscale節點。縮放加載程序讀取預訓練的升級模型,而升級節點實際執行升級到4K。
