
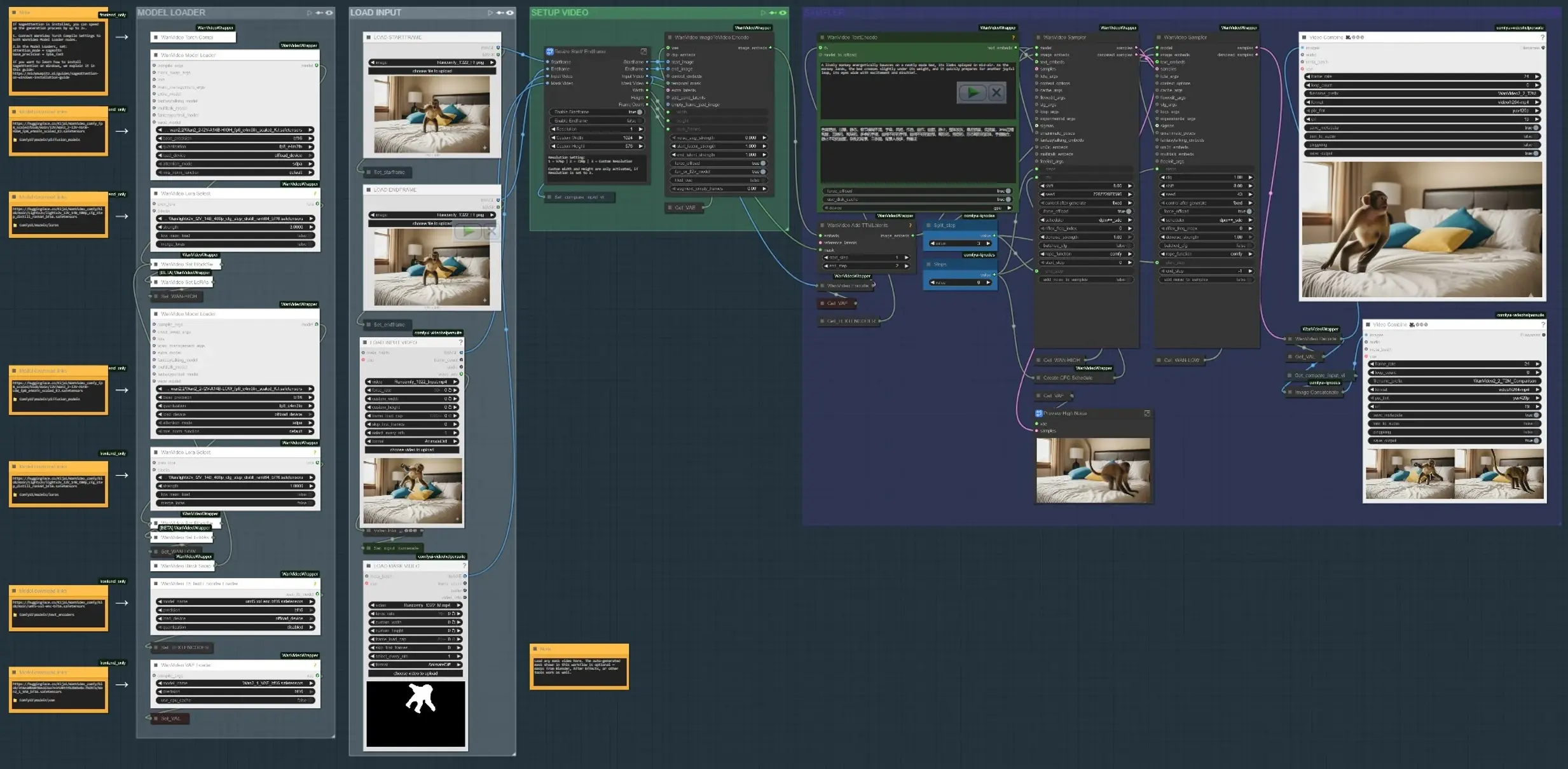
AI影片中的可控動畫:WanVideo + TTM動作控制工作流程於ComfyUI#
由mickmumpitz開發的此工作流程將AI影片中的可控動畫引入ComfyUI,採用無需訓練的動作引導方法。它結合了WanVideo的圖像到影片擴散、Time‑to‑Move (TTM) 潛在引導和區域感知遮罩,使您能在保持主體身份、紋理和場景連續性的情況下指導主體如何移動。
您可以從影片片段或兩個關鍵幀開始,添加區域遮罩以聚焦您想要的運動,並在不進行微調的情況下驅動軌跡。結果是精確、可重複的AI影片中的可控動畫,適用於導向鏡頭、物件運動排序和自定義創意編輯。
Comfyui中AI影片工作流程中的關鍵模型#
- Wan2.2 I2V A14B (HIGH/LOW)。核心圖像到影片擴散模型,從提示和視覺參考中合成運動和時間連貫性。兩個變體平衡不同運動強度的保真度(HIGH)和靈活性(LOW)。模型文件托管在Hugging Face的社區WanVideo收藏中,例如Kijai的WanVideo分發。 連結:Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA。輕量級適配器,在與Wan2.2組合時加強結構和運動一致性。它幫助在更強的運動提示下保留主體幾何形狀。 連結:Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE。用於編碼影片幀至潛在空間並將採樣器的輸出解碼回圖像的影片自動編碼器,且不犧牲細節。 連結:Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- UMT5‑XXL文本編碼器。為提示驅動的控制提供豐富的文本嵌入,與運動提示一起使用。 連結:google/umt5-xxl, Kijai/WanVideo_comfy – encoder weights
- 用於影片遮罩的Segment Anything模型。SAM3和SAM2創建並傳播跨幀的區域遮罩,使區域依賴的指導在重要的地方加強AI影片中的可控動畫。 連結:facebook/sam3, facebook/sam2
- Qwen‑Image‑Edit 2509(可選)。圖像編輯基礎和快速起始/結束幀清理或在動畫前移除物件的閃電LoRA。 連結:QuantStack/Qwen‑Image‑Edit‑2509‑GGUF, lightx2v/Qwen‑Image‑Lightning, Comfy‑Org/Qwen‑Image_ComfyUI
- Time‑to‑Move (TTM) 引導。工作流程整合TTM潛在空間以無需訓練的方式注入軌跡控制,實現AI影片中的可控動畫。 連結:time‑to‑move/TTM
如何使用Comfyui中AI影片工作流程中的可控動畫#
此工作流程分為四個主要階段:加載輸入、定義運動應發生的位置、編碼文本和運動提示,然後合成並預覽結果。下列每組對應於圖中的標記部分。
- 加載輸入 使用“加載輸入影片”組來引入一個片段或參考剪輯,或加載開始和結束關鍵幀,如果您正在構建兩個狀態之間的運動。“調整大小開始/結束幀”子圖將尺寸標準化並可選擇啟用開始幀和結束幀門控。並排比較器生成一個輸出,顯示輸入與結果的快速審核(
VHS_VideoCombine(#613))。 - 模型加載器 “模型加載器”組設置Wan2.2 I2V (HIGH/LOW)並應用Lightx2v LoRA。塊交換路徑混合變體以在採樣前取得良好的保真度-運動權衡。Wan VAE加載一次並在編碼/解碼中共享。文本編碼使用UMT5‑XXL以在AI影片中的可控動畫中實現強大的提示條件。
- SAM3/SAM2遮罩主體 在“遮罩主體 SAM3”或“遮罩主體 SAM2”中,點擊參考幀,添加正負點,並在剪輯中傳播遮罩。這產生時間一致的遮罩,限制運動編輯至您選擇的主體或區域,使區域依賴的指導成為可能。您也可以繞過並加載自己的遮罩影片;從Blender/After Effects生成的遮罩在需要藝術家繪製的控制時工作良好。
- 開始幀/結束幀準備(可選) “開始幀 – QWEN移除”和“結束幀 – QWEN移除”組提供特定幀的可選清理通過,使用Qwen‑Image‑Edit。使用它們移除支架、棍子或會污染運動提示的片段工件。修補裁剪並將編輯縫合回全幀以獲得乾淨的基礎。
- 文本+運動編碼 提示在
WanVideoTextEncode(#605)中使用UMT5‑XXL進行編碼。開始幀/結束幀圖像在WanVideoImageToVideoEncode(#89)中轉換為影片潛在空間。TTM運動潛在空間和可選的時間遮罩通過WanVideoAddTTMLatents(#104)合併,以便採樣器接收語義(文本)和軌跡提示,這是AI影片中的可控動畫的核心。 - 採樣器和預覽 Wan採樣器(
WanVideoSampler(#27)和WanVideoSampler(#90))使用雙時鐘設置對潛在空間去噪:一個路徑管理全局動態,而另一個保留局部外觀。步驟和可配置的CFG計劃形塑運動強度與保真度。結果解碼為幀並保存為影片;比較輸出有助於判斷您的AI影片中的可控動畫是否符合簡介。
Comfyui中AI影片工作流程中的關鍵節點#
WanVideoImageToVideoEncode(#89) 將開始幀/結束幀圖像編碼為啟動運動合成的影片潛在空間。僅在更改基礎分辨率或幀數時進行調整;保持這些與您的輸入對齊以避免拉伸。如果使用遮罩影片,請確保其尺寸與編碼的潛在尺寸匹配。WanVideoAddTTMLatents(#104) 將TTM運動潛在空間和時間遮罩融合到控制流中。切換遮罩輸入以將運動限制在您的主體上;留空則會將運動應用於全局。當您想要不影響背景的軌跡特定AI影片中的可控動畫時,使用此功能。SAM3VideoSegmentation(#687) 收集一些正負點,選擇一個軌跡幀,然後在剪輯中傳播。使用可視化輸出驗證遮罩漂移在採樣之前。對於隱私敏感或離線工作流程,切換到不需要模型門控的SAM2組。WanVideoSampler(#27) 平衡運動和身份的去噪器。將“步驟”與CFG調度列表配對以推動或放鬆運動強度;過強會壓倒外觀,而過弱則無法提供運動。當遮罩啟動時,採樣器將更新集中在區域內,改善AI影片中的可控動畫的穩定性。
可選額外功能#
- 為快速迭代,從低Wan2.2模型開始,使用TTM調整運動,然後在最後一次通過中切換到高以恢復紋理。
- 使用藝術家繪製的遮罩影片來處理複雜的輪廓;加載器接受外部遮罩並會重新調整它們以匹配。
- “開始幀/結束幀”開關讓您可視化鎖定第一或最後一幀,這對於更長的編輯中的無縫交接很有用。
- 如果在您的環境中可用,啟用優化的注意力(例如,SageAttention)可以顯著加速採樣。
- 在組合節點中將輸出幀速率與源匹配,以避免AI影片中的可控動畫中的感知時間差異。
此工作流程通過結合文本提示、TTM潛在空間和強大的分割,提供無需訓練的區域感知運動控制。只需少量目標輸入,您就可以在保持主體模型和場景連貫的同時,指導細緻、製作就緒的AI影片中的可控動畫。
致謝#
此工作流程實施並建立在以下作品和資源之上。我們感謝Mickmumpitz創建AI影片中的可控動畫教程/文章,以及time-to-move團隊對TTM的貢獻和維護。欲了解權威詳情,請參考下列原始文檔和存儲庫。
資源#
- Patreon/AI影片中的可控動畫
- 文檔 / 發佈說明:Mickmumpitz Patreon文章
- time-to-move/TTM
- GitHub: time-to-move/TTM
注意:引用的模型、數據集和代碼的使用受其作者和維護者提供的各自許可和條款約束。