
ComfyUI MOSS TTS:文本轉語音、語音克隆、音效和對話於一個工作流程#
這個 ComfyUI MOSS TTS 工作流程使用 OpenMOSS MOSS-TTS 系列將文本轉換為生動的 24 kHz 語音。它涵蓋了快速單一說話者合成、從短參考片段進行零樣本語音克隆、描述性語音設計、程序音效以及多說話者對話,並可選擇每個說話者的參考。
基於官方 MOSS-TTS 節點堆疊和模型系列,平衡速度與質量。Local 1.7B 路徑在單一 GPU 上是實用的快速通道,而較大的 Delay 8B 模型則以速度換取更廣泛的能力和表達力。如果您需要可重用的提示、克隆語音或在 ComfyUI 中的對話,這個 ComfyUI MOSS TTS 工作流程是為您設計的。
ComfyUI MOSS TTS 工作流程中的關鍵模型#
- OpenMOSS MOSS-TTS Local 1.7B。單 GPU 友好的文本轉語音轉換器,為日常生產工作提供快速、自然的 24 kHz 語音。模型卡:MOSS-TTS-Local-Transformer。
- OpenMOSS MOSS-TTS Delay 8B。較大的模型系列,強調質量、說話者相似性和韻律,代價是速度和記憶體。模型卡:MOSS-TTS。
- MOSS 音頻標記器。為 MOSS-TTS 模型架橋波形和離散標記的學習編解碼器,實現高保真解碼。模型卡:MOSS-Audio-Tokenizer。
有關實施細節和更新,請參閱官方存儲庫:OpenMOSS/MOSS-TTS 和推動此工作流程的節點堆疊 richservo/comfyui-moss-tts。
如何使用 ComfyUI MOSS TTS 工作流程#
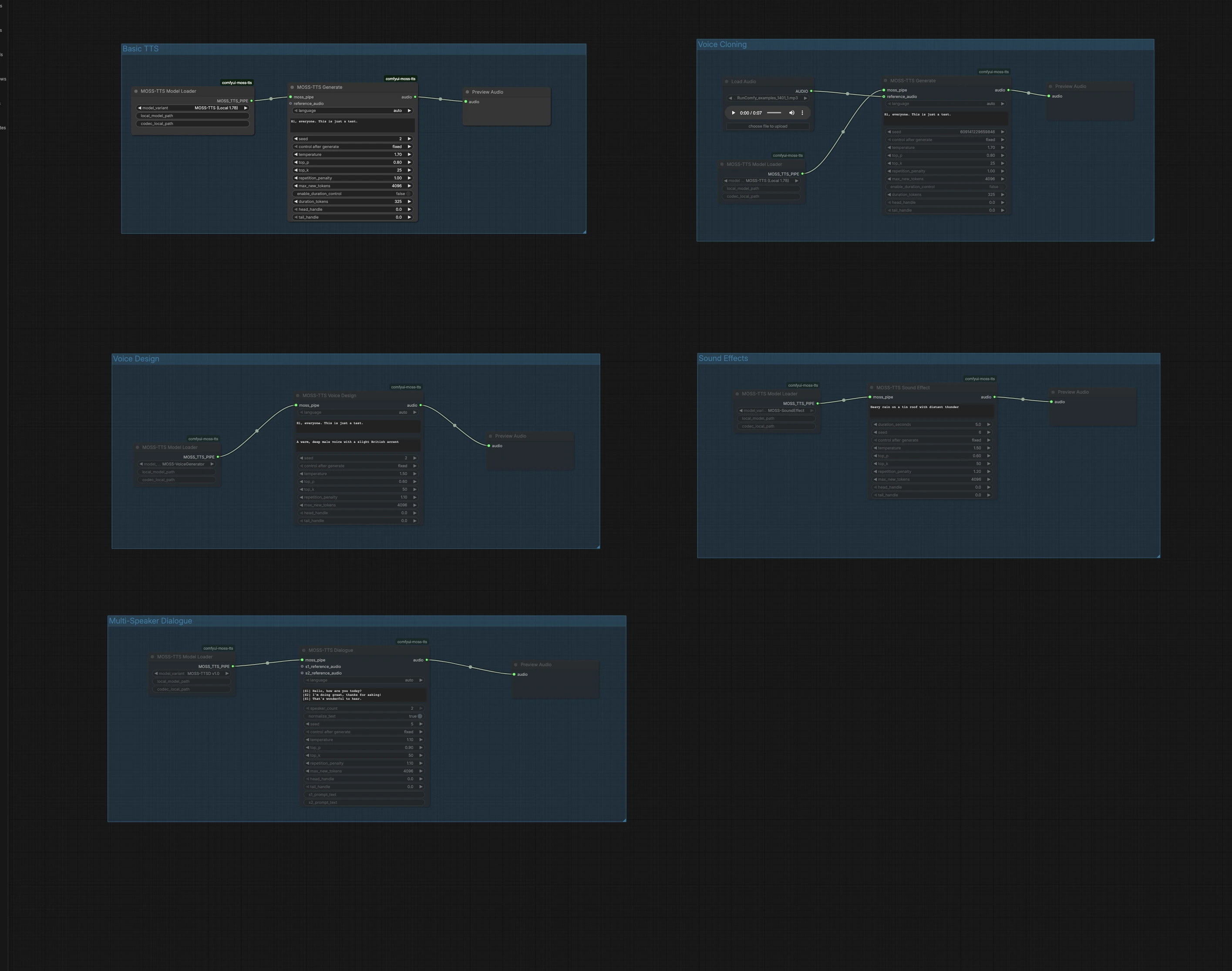
此圖表分為五個獨立組。選擇符合您目標的組,運行它,然後在畫布中直接預覽音頻。您可以同時運行多個組以試聽不同的方法。
基本 TTS#
基本 TTS 組使用 Local 1.7B 快速路徑將純文本轉換為語音。在 MossTTSModelLoader (#1) 中加載模型,將文本提供給 MossTTSGenerate (#2),然後在 PreviewAudio (#3) 中收聽。生成器根據您的提示來塑造發音和韻律,因此請使用標點符號自然書寫以控制節奏。當您希望重複獲取時,保持種子固定,或在探索交付變體時隨機化它。
語音克隆#
語音克隆組從短參考音頻片段進行零樣本語音克隆。使用 LoadAudio (#4) 導入乾淨的語音樣本,將其連接到 MossTTSGenerate (#6),由 MossTTSModelLoader (#5) 驅動,並提供目標文本。模型從參考中提取說話者的音色和風格,並以該語音呈現您的新腳本。使用中性內容和最小背景噪音的參考以提高相似性,並保持適中長度以獲得最快的周轉。
語音設計#
語音設計從自然語言描述而不是示例片段創建新語音。MossTTSVoiceDesign (#9) 使用類似於 "溫暖、深沉的男性聲音,帶有輕微的英國口音" 的文本描述,結合您的腳本,合成 24 kHz 語音。該節點由通過 MossTTSModelLoader (#8) 加載的專用語音生成路徑驅動。這在您希望獲得一致、可重複的角色而不需尋找真實錄音時非常理想。使用年齡、音色、口音和能量等特徵來微調描述以引導聲音。
音效#
音效從文本提示生成非語音音頻,適用於床軌、過渡或環境層。使用 MossTTSSoundEffect (#12) 及其模型管道從 MossTTSModelLoader (#11),像 "鐵皮屋頂上的大雨伴隨遠處雷聲" 的提示產生豐富、可循環的紋理。使用簡潔的名詞和動作來定義場景,然後添加一些形容詞來確定強度或距離。在 PreviewAudio (#13) 中預覽並快速迭代以適合您的混音。
多說話者對話#
多說話者對話組呈現有腳本的對話,具有可選的每個說話者參考片段。使用方括號標記的說話者標籤編寫腳本,例如 [S1] 你好。 和 [S2] 嗨!,然後將其傳遞給 MossTTSDialogue (#15),在 MossTTSModelLoader (#14) 的模型管道下。您可以為 S1 和 S2 附加參考音頻輸入,以便為每個角色克隆特定語音,或者讓模型從文本上下文中選擇不同的說話者。此路徑非常適合問答、帶角色台詞的敘述或語音 UI 模擬。
ComfyUI MOSS TTS 工作流程中的關鍵節點#
MossTTSModelLoader (#1)#
加載所選的 OpenMOSS 模型系列並組裝內部 TTS 管道。選擇 Local 1.7B 變體以在單一 GPU 上快速迭代,或在優先考慮表達和相似性時切換到較大的 Delay 8B 模型。為每個任務系列保持一個加載器,以便每個下游分支保持自包含。
MossTTSGenerate (#2)#
主要的單一說話者合成器,消耗您的文本提示和可選的參考音頻以生成 24 kHz 語音。提供乾淨、標點明確的文本以獲得更清晰的節奏,並在需要零樣本克隆時連接短語音片段。在固定和隨機間切換種子以平衡可重現性和探索。
MossTTSVoiceDesign (#9)#
從描述性提示生成新語音以及要講的文本。專注於音色、年齡、口音和能量的描述來引導身份,同時保持簡潔。當授權或尋找真實語音不切實際時,這是強有力的選擇。
MossTTSSoundEffect (#12)#
從短文本描述合成非語音音頻。撰寫緊湊的提示,錨定來源、動作和空間,然後迭代以匹配場景。非常適合您在同一 ComfyUI MOSS TTS 圖中用於對話的環境和單次音效。
MossTTSDialogue (#15)#
解析帶方括號的說話者標籤,並將多輪對話呈現為單一音頻輸出。使用 [S1]、[S2] 等標記每行,並可選擇連接每個說話者的參考片段以在各回合中保持身份。保持行簡潔以獲得最可靠的說話者交接。
可選擴展#
- 以 Local 1.7B 模型開始進行快速草稿,然後在需要更強的相似性或更豐富的韻律時切換到 Delay 8B 檢查點。
- 對於零樣本克隆,使用帶最小混響和噪音的乾淨 5–15 秒語音片段以改善音色轉移。
- 在對話中,保持說話者標籤一致且不含標點如
[S1]以避免解析錯誤。 - 使用 3–6 個特徵如音色、年齡、口音、風格和能量創建聲音設計提示以獲得可預測的結果。
- 在文本中使用標點和換行控制 ComfyUI MOSS TTS 輸出的停頓與節奏。
- 如果您想要自動文件導出以進行批量渲染,請在任何預覽後添加
SaveAudio節點。
參考資料:OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
致謝#
此工作流程實現並基於以下作品和資源。我們對 richservo 的 ComfyUI MOSS-TTS 自定義節點、OpenMOSS 的 MOSS-TTS 存儲庫以及 OpenMOSS-Team 的 MOSS-TTS 模型(Delay 8B 和 Local 1.7B)和 MOSS 音頻標記器的貢獻和維護表示感謝。有關權威詳情,請參閱以下鏈接的原始文檔和存儲庫。
資源#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
注意:使用參考的模型、數據集和代碼須遵循其作者和維護者提供的各自許可和條款。
