
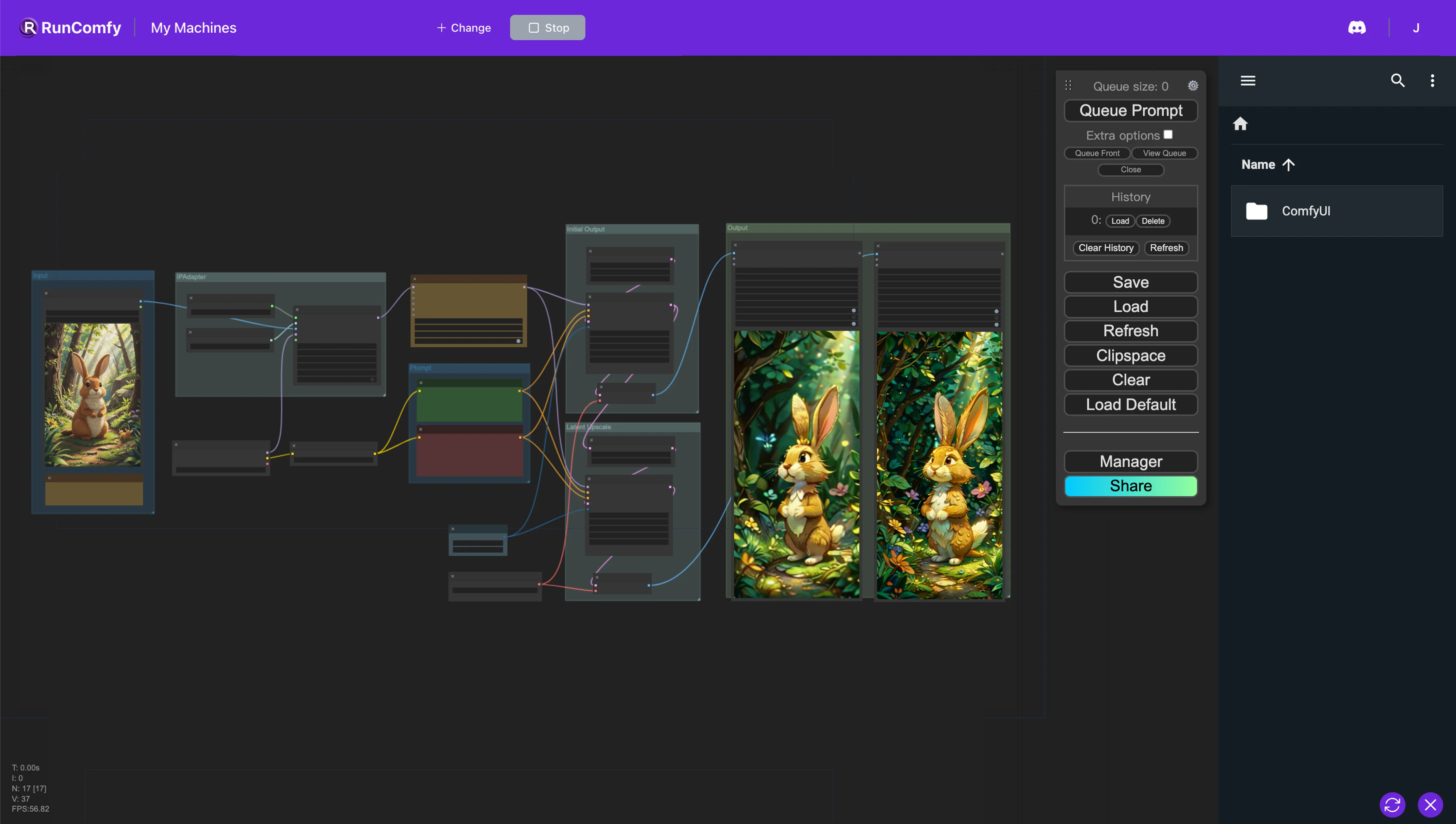
1. ComfyUI 工作流程: AnimateDiff + IPAdapter | 圖像到視頻#
這個 ComfyUI 工作流程旨在通過使用 AnimateDiff 和 IP-Adapter 從參考圖像創建動畫。AnimateDiff 節點集成了模型和上下文選項以調整動畫動態。相反,IP-Adapter 節點促進了圖像作為提示的使用,這樣可以模仿參考圖像的風格、構圖或面部特徵,顯著提高生成動畫或圖像的定制化和質量。
2. AnimateDiff 概述#
請查看 如何在 ComfyUI 中使用 AnimateDiff 的詳細信息
3. IP-Adapter 概述#
3.1. IP-Adapter 介紹#
IP-Adapter 代表 "Image Prompt Adapter",這是一種增強文本到圖像擴散模型的新方法,具有在圖像生成任務中使用圖像提示的能力。IP-Adapter 旨在解決文本提示的不足,文本提示通常需要複雜的提示工程來生成所需的圖像。圖像提示的引入,與文本一起使用,提供了一種更直觀和有效的方式來指導圖像合成過程。
IP-Adapter 的不同模型
IP-Adapter 套件包括各種模型,每種模型都針對特定的用例和圖像合成複雜程度量身定制。以下是不同模型的概述:
3.1.1. v1.5 模型
ip-adapter_sd15: 版本 1.5 的標準模型,利用 IP-Adapter 的力量進行圖像到圖像調整和文本提示增強。ip-adapter_sd15_light: 標準模型的輕量化版本,優化以便在資源較少的應用中使用,同時仍然利用 IP-Adapter 技術。ip-adapter-plus_sd15: 增強型模型,生成的圖像與原始參考更加一致,改善了細節。ip-adapter-plus-face_sd15: 類似於 IP-Adapter Plus,專注於生成圖像中更準確的面部特徵複製。ip-adapter-full-face_sd15: 強調全臉細節的模型,可能提供高保真度的 "面部替換" 效果。ip-adapter_sd15_vit-G: 使用 Vision Transformer (ViT) BigG 圖像編碼器的標準模型變體,用於更詳細的圖像特徵提取。
3.1.2. SDXL 模型
ip-adapter_sdxl: SDXL 的基礎模型,設計用於處理更大和更複雜的圖像提示。ip-adapter_sdxl_vit-h: 與 ViT H 圖像編碼器配對的 SDXL 模型,平衡性能與計算效率。ip-adapter-plus_sdxl_vit-h: SDXL 模型的高級版本,具有增強的圖像提示細節和質量。ip-adapter-plus-face_sdxl_vit-h: 專注於面部細節的 SDXL 變體,適合需要高面部準確度的項目。
3.1.3. FaceID 模型
FaceID: 使用 InsightFace 提取 Face ID 嵌入的模型,提供了一種獨特的面部相關圖像生成方法。FaceID Plus: FaceID 模型的改進版本,結合 InsightFace 用於面部特徵和 CLIP 圖像編碼用於全球面部特徵。FaceID Plus v2: FaceID Plus 的迭代版本,具有改進的模型檢查點和設置 CLIP 圖像嵌入權重的能力。FaceID Portrait: 類似於 FaceID 的模型,但設計用於接受多個裁剪面部的圖像以進行更多樣化的面部調整。
3.1.4. SDXL FaceID 模型
FaceID SDXL: FaceID 的 SDXL 版本,保持與 v1.5 相同的 InsightFace 模型,但擴展用於 SDXL 應用。FaceID Plus v2 SDXL: FaceID Plus v2 的 SDXL 改編,適用於高分辨率圖像生成,具有增強的保真度。
3.2. IP-Adapter 的主要功能#
3.2.1. 文本和圖像提示集成: IP-Adapter 的獨特能力是使用文本和圖像提示,使多模態圖像生成成為可能,提供了一個多功能且強大的工具來控制擴散模型輸出。
3.2.2. 解耦的交叉注意機制: IP-Adapter 採用解耦的交叉注意策略,通過分離文本和圖像特徵來提高模型在處理多樣化模態時的效率。
3.2.3. 輕量級模型: 儘管功能全面,IP-Adapter 的參數數量相對較少(22M),提供的性能與微調的圖像提示模型不相上下甚至更優。
3.2.4. 兼容性和泛化: IP-Adapter 設計為與現有的可控工具廣泛兼容,並可以應用於從相同基礎模型派生的自定義模型,以增強泛化能力。
3.2.5. 結構控制: IP-Adapter 支持詳細的結構控制,使創作者能夠更精確地引導圖像生成過程。
3.2.6. 圖像到圖像和修補功能: 支持圖像指導的圖像到圖像翻譯和修補,IP-Adapter 擴展了可能的應用範圍,提供了創意和實用的使用於多種圖像合成任務中。
3.2.7. 使用不同編碼器的自定義: IP-Adapter 允許使用各種編碼器,如 OpenClip ViT H 14 和 ViT BigG 14,來處理參考圖像。這種靈活性有助於處理不同的圖像分辨率和複雜性,使其成為創作者尋求將圖像生成過程調整到特定需求或期望結果的多功能工具。
IP-Adapter 技術在圖像生成項目的應用,不僅簡化了複雜和詳細圖像的創建,還顯著提高了生成圖像對原始提示的質量和保真度。通過彌合文本提示和圖像提示之間的差距,IP-Adapter 提供了一種強大、直觀且高效的方法來控制圖像合成的細微差別,使其成為數字藝術家、設計師和創作者在 ComfyUI 工作流程中或任何其他需要高質量、自定義圖像生成的上下文中的不可或缺的工具。