
1. 關於 CogVideoX-5B#
CogVideoX-5B 是由清華大學的 Zhipu AI 開發的尖端文本到視頻擴散模型。作為 CogVideoX 系列的一部分,該模型使用先進的 AI 技術,如 3D 變分自動編碼器 (VAE) 和 Expert Transformer,直接從文本提示創建視頻。CogVideoX-5B 生成高質量、時間一致的結果,捕捉複雜的運動和詳細的語義。
使用 CogVideoX-5B,您將獲得卓越的清晰度和流暢度。該模型確保流暢的流動,以非凡的準確性捕捉複雜的細節和動態元素。利用 CogVideoX-5B 減少不一致性和瑕疵,帶來精緻和引人入勝的呈現。CogVideoX-5B 的高保真輸出促進了從文本提示創建豐富詳細和一致的場景,使其成為高端質量和視覺效果的必備工具。
2. CogVideoX-5B 的技術#
2.1 CogVideoX-5B 的 3D 因果變分自動編碼器 (VAE)#
3D 因果 VAE 是 CogVideoX-5B 的關鍵組成部分,通過在空間和時間上壓縮視頻數據實現高效視頻生成。與傳統模型使用 2D VAE 單獨處理每幀(通常導致幀之間的閃爍)不同,CogVideoX-5B 使用 3D 卷積一次捕捉空間和時間信息。這種方法確保幀之間的平滑和一致過渡。
3D 因果 VAE 的架構包括編碼器、解碼器和潛在空間正則化器。編碼器將視頻數據壓縮為潛在表示,然後解碼器使用該表示重建視頻。Kullback-Leibler (KL) 正則化器約束潛在空間,確保編碼的視頻保持在高斯分佈內。在重建過程中,這有助於保持高視頻質量。
3D 因果 VAE 的關鍵特徵
- 空間和時間壓縮:VAE 在時間維度上壓縮視頻數據的比率為 4x,在空間維度上壓縮的比率為 8x8,總壓縮比為 4x8x8。這減少了計算需求,允許模型使用更少的資源處理更長的視頻。
- 因果卷積:為了保持視頻中幀的順序,模型使用時間上因果卷積。這確保未來幀不會影響當前或過去幀的預測,從而在生成過程中維持序列的完整性。
- 上下文並行性:為了管理處理長視頻的高計算負擔,模型在時間維度上使用上下文並行性,將工作負載分佈在多個設備上。這優化了訓練過程並減少了內存使用。
2.2 CogVideoX-5B 的 Expert Transformer 架構#
CogVideoX-5B 的 Expert Transformer 架構旨在有效處理文本和視頻數據之間的複雜交互。它使用自適應 LayerNorm 技術來處理文本和視頻的不同特徵空間。
Expert Transformer 的關鍵特徵
- 塊化:3D 因果 VAE 編碼視頻數據後,視頻在空間維度上被分割為更小的塊。這一過程稱為塊化,將視頻轉換為更小段的序列,使得 Transformer 更易於處理並與對應的文本數據對齊。
- 3D 旋轉位置嵌入 (RoPE):為了捕捉視頻中的空間和時間關係,CogVideoX-5B 將傳統的 2D RoPE 擴展到 3D。該嵌入技術將位置編碼應用於視頻的 x、y 和 t 維度,幫助 Transformer 有效建模長視頻序列並保持幀間的一致性。
- Expert 自適應 LayerNorm (AdaLN):Transformer 使用 Expert 自適應 LayerNorm 分別處理文本和視頻嵌入。這允許模型對齊文本和視頻的不同特徵空間,實現這兩種模態的平滑融合。
2.3 CogVideoX-5B 的漸進訓練技術#
CogVideoX-5B 使用多種漸進訓練技術來提高其性能和生成視頻過程中的穩定性。
關鍵漸進訓練策略
- 混合時長訓練:模型在同一批次中訓練不同長度的視頻。這種技術增強了模型的泛化能力,使其能夠生成不同時長的視頻,同時保持一致的質量。
- 分辨率漸進訓練:模型先在低分辨率視頻上訓練,然後逐步在高分辨率視頻上進行微調。這種方法允許模型在提高分辨率之前學習視頻的基本結構和內容。
- 顯式均勻抽樣:為了穩定訓練過程,CogVideoX-5B 使用顯式均勻抽樣,為每個數據並行排名設置不同的時間步抽樣間隔。這種方法加速了收斂,並確保模型在整個視頻序列中有效學習。
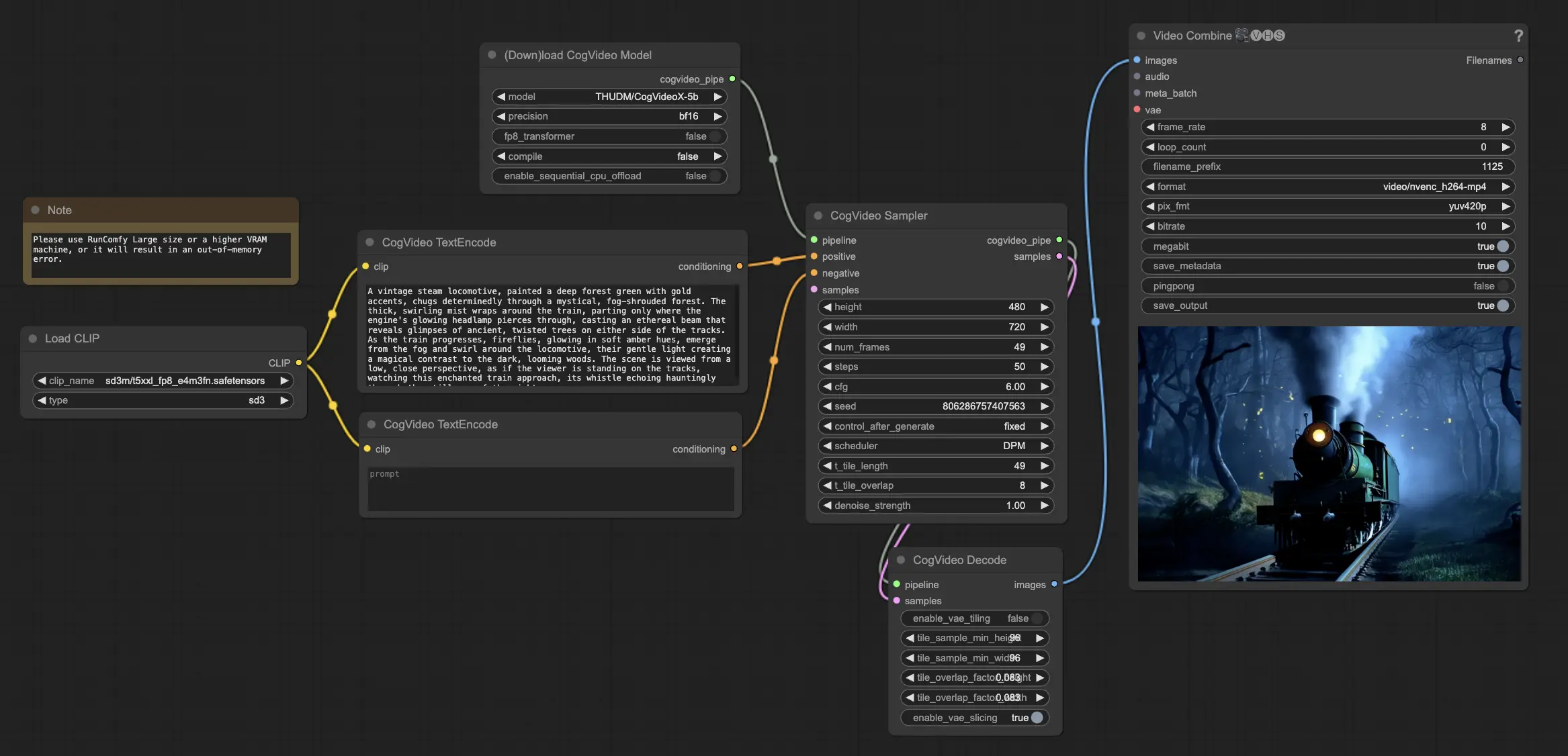
3. 如何使用 ComfyUI CogVideoX-5B 工作流程#
步驟 1:加載 CogVideoX-5B 模型#
首先將 CogVideoX-5B 模型加載到 ComfyUI 工作流程中。CogVideoX-5B 模型已在 RunComfy 平台上預加載。
步驟 2:輸入您的文本提示#
在指定的節點中輸入您想要的文本提示,以指導 CogVideoX-5B 的視頻生成過程。CogVideoX-5B 擅長解釋和轉換文本提示為動態視頻內容。
4. 許可協議#
CogVideoX 模型的代碼根據 Apache 2.0 許可證 發布。
CogVideoX-2B 模型(包括其對應的 Transformers 模塊和 VAE 模塊)根據 Apache 2.0 許可證 發布。
CogVideoX-5B 模型(Transformers 模塊)根據 CogVideoX 許可證 發布。

