
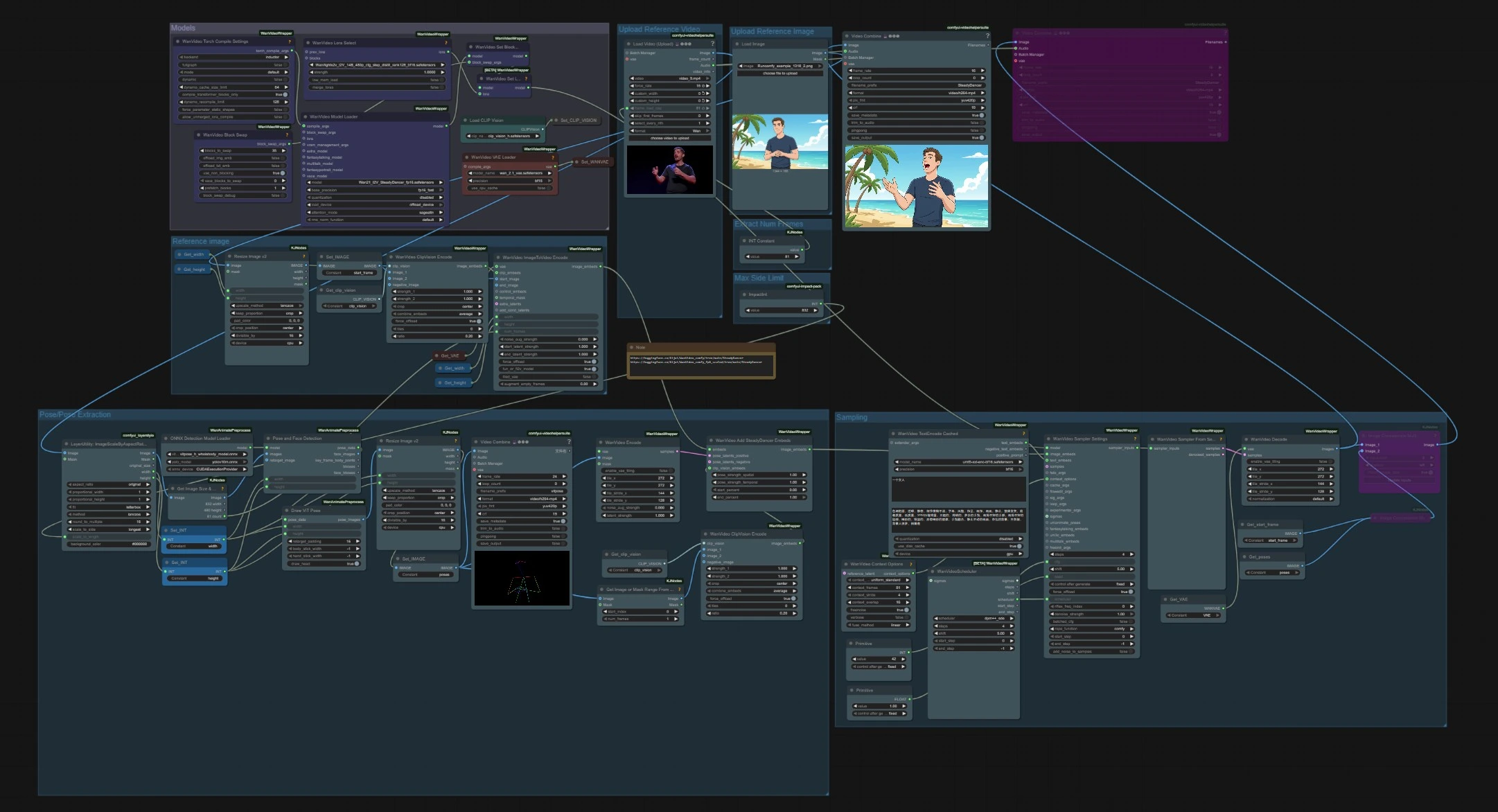
SteadyDancer 图像到视频姿势动画工作流#
此 ComfyUI 工作流将单个参考图像转变为由单独姿势源驱动的连贯视频。它围绕 SteadyDancer 的图像到视频范式构建,因此第一帧保留输入图像的身份和外观,而序列的其余部分则遵循目标运动。该图通过 SteadyDancer 特定的嵌入和姿势管道调和姿势和外观,产生平滑、逼真的全身运动,具有强大的时间一致性。
SteadyDancer 非常适合人体动画、舞蹈生成以及让角色或肖像栩栩如生。提供一张静止图像加上一段运动剪辑,ComfyUI 管道处理姿势提取、嵌入、采样和解码,交付准备分享的视频。
Comfyui SteadyDancer 工作流中的关键模型#
- SteadyDancer。用于保留身份的图像到视频研究模型,具有条件调和机制和协同姿势调制。这里用作核心 I2V 方法。 GitHub
- Wan 2.1 I2V SteadyDancer 权重。端口到 ComfyUI 的检查点在 Wan 2.1 栈上实现 SteadyDancer。Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) 和 Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE。用于管道内潜在编码和解码的视频 VAE。包含在上面的 WanVideo 端口中。Hugging Face
- OpenCLIP CLIP ViT‑H/14。视觉编码器,从参考图像中提取鲁棒的外观嵌入。GitHub
- ViTPose‑H WholeBody (ONNX)。用于身体、手和脸部的高质量关键点模型,用于推导驱动姿势序列。GitHub
- YOLOv10 (ONNX)。在多样化视频上改善姿势估计之前的人物定位检测器。Hugging Face
如何使用 Comfyui SteadyDancer 工作流#
工作流有两个独立的输入,在采样时相遇:用于身份的参考图像和用于运动的驱动视频。模型在前面一次加载,姿势从驱动剪辑中提取,SteadyDancer 嵌入在生成和解码之前融合姿势和外观。
模型#
此组加载贯穿图中的核心权重。WanVideoModelLoader (#22) 选择 Wan 2.1 I2V SteadyDancer 检查点并处理注意力和精度设置。WanVideoVAELoader (#38) 提供视频 VAE,CLIPVisionLoader (#59) 准备 CLIP ViT‑H 视觉骨干。高级用户可以使用 LoRA 选择节点和 BlockSwap 选项来更改内存行为或附加附加权重。
上传参考视频#
使用 VHS_LoadVideo (#75) 导入运动源。节点读取帧和音频,让您设置目标帧率或限制帧数。剪辑可以是任何人类运动,例如舞蹈或运动动作。然后,视频流流向长宽比缩放和姿势提取。
提取帧数#
一个简单的常量控制从驱动视频中加载多少帧。这限制了姿势提取和生成的 SteadyDancer 输出的长度。增加它以获得更长的序列,或减少它以更快地迭代。
最大边限制#
LayerUtility: ImageScaleByAspectRatio V2 (#146) 在保持宽高比的同时缩放帧,以适应模型的步幅和内存预算。设置适合您的 GPU 和所需细节级别的长边限制。缩放后的帧由下游检测节点使用,并作为输出尺寸的参考。
姿势/姿势提取#
人物检测和姿势估计在缩放的帧上运行。PoseAndFaceDetection (#89) 使用 YOLOv10 和 ViTPose‑H 稳健地找到人物和关键点。DrawViTPose (#88) 渲染运动的干净的线条图表示,ImageResizeKJv2 (#77) 将生成帆布匹配的姿势图像大小。WanVideoEncode (#72) 将姿势图像转换为潜在变量,以便 SteadyDancer 可以在不与外观信号冲突的情况下调制运动。
上传参考图像#
加载您希望 SteadyDancer 动画化的身份图像。图像应清晰显示您打算移动的主体。使用与驱动视频大致匹配的姿势和相机角度,以实现最忠实的传输。该帧被转发到参考图像组进行嵌入。
参考图像#
静态图像使用 ImageResizeKJv2 (#68) 调整大小,并通过 Set_IMAGE (#96) 注册为起始帧。WanVideoClipVisionEncode (#65) 提取保留身份、服装和粗略布局的 CLIP ViT‑H 嵌入。WanVideoImageToVideoEncode (#63) 打包宽度、高度和帧数与起始帧,以准备 SteadyDancer 的 I2V 调节。
采样#
这是外观和运动结合生成视频的地方。WanVideoAddSteadyDancerEmbeds (#71) 从 WanVideoImageToVideoEncode 接收图像调节,并通过姿势潜在变量加上 CLIP 视觉参考进行增强,使 SteadyDancer 的条件调和成为可能。在 WanVideoContextOptions (#87) 中设置上下文窗口和重叠以实现时间一致性。可选地,WanVideoTextEncodeCached (#92) 添加 umT5 文本指导以进行风格调整。WanVideoSamplerSettings (#119) 和 WanVideoSamplerFromSettings (#129) 在 Wan 2.1 模型上运行实际的去噪步骤,然后 WanVideoDecode (#28) 将潜在变量转换回 RGB 帧。最终视频通过 VHS_VideoCombine (#141, #83) 保存。
Comfyui SteadyDancer 工作流中的关键节点#
WanVideoAddSteadyDancerEmbeds (#71)#
此节点是图的 SteadyDancer 核心。它将图像调节与姿势潜在变量和 CLIP 视觉提示融合,使第一帧锁定身份,同时运动自然展开。调整 pose_strength_spatial 以控制肢体如何紧密跟随检测到的骨架,并调整 pose_strength_temporal 以调节随时间的运动平滑度。使用 start_percent 和 end_percent 限制序列中姿势控制应用的位置,以获得更自然的开场和结尾。
PoseAndFaceDetection (#89)#
在驱动视频上运行 YOLOv10 检测和 ViTPose‑H 关键点估计。如果姿势错过小肢体或脸部,请增加上游输入分辨率或选择遮挡较少且光线更清晰的镜头。当有多个人物时,请保持目标主体在画面中最大,以便检测器和姿势头保持稳定。
VHS_LoadVideo (#75)#
控制您使用的运动源的部分。增加帧上限以获得更长的输出,或降低它以快速原型。force_rate 输入将姿势间距与生成率对齐,并可以帮助减少原始剪辑的 FPS 不寻常时的卡顿。
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
在保持宽高比的同时将帧保持在选定的长边限制内,并将其划分为可整除的尺寸。将此处的比例与生成画布匹配,以便 SteadyDancer 不需要过度上采样或裁剪。如果看到软结果或边缘伪影,请将长边更接近模型的原生训练比例,以获得更干净的解码。
WanVideoSamplerSettings (#119)#
定义 Wan 2.1 采样器的去噪计划。scheduler 和 steps 设置总体质量与速度,而 cfg 平衡图像加提示的遵从性与多样性。seed 锁定可重复性,denoise_strength 可以降低,当您想要更接近参考图像的外观时。
WanVideoModelLoader (#22)#
加载 Wan 2.1 I2V SteadyDancer 检查点并处理精度、注意力实现和设备放置。保持这些配置以确保稳定性。高级用户可以附加一个 I2V LoRA 来改变运动行为或在实验时减轻计算成本。
可选额外功能#
- 选择清晰、光线充足的参考图像。正面或略微倾斜的视图类似于驱动视频的相机,使 SteadyDancer 更可靠地保留身份。
- 优选具有单一突出主体和最小遮挡的运动剪辑。繁忙的背景或快速剪辑会降低姿势稳定性。
- 如果手和脚抖动,稍微增加
WanVideoAddSteadyDancerEmbeds中的姿势时间强度,或提高视频 FPS 以增加姿势密度。 - 对于较长的场景,分段处理,具有重叠的上下文并拼接输出。这使内存使用合理,并保持时间连续性。
- 使用内置的预览马赛克比较生成的帧与起始帧和姿势序列,同时调整设置。
此 SteadyDancer 工作流为您提供了一条实用的、从单一静止图像到忠实、姿势驱动的视频的完整路径,第一帧就保留了身份。
致谢#
此工作流实施并建立在以下工作和资源之上。我们诚挚地感谢 MCG-NJU 为 SteadyDancer 的贡献和维护。有关权威详情,请参阅下列的原始文档和存储库。
资源#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
注意:引用的模型、数据集和代码的使用受其作者和维护者提供的相关许可证和条款的约束。
