
Stable Audio Open 1.0 文本到音乐工作流#
此工作流使用 Stable Audio Open 1.0 将普通文本转化为原创音乐和音景。它专为作曲家、声音设计师和创作者设计,能够在不离开 ComfyUI 的情况下快速、可控地生成音频。您只需编写提示,设置目标时长,图表就会渲染一个反映您风格、情绪、节奏和配器的 MP3。
在后台,工作流使用基于 T5 的文本编码器对您的文本进行编码,在潜在音频空间中运行 Stable Audio 的扩散过程,然后解码为波形并保存结果。通过清晰的提示指导和简单的长度控制,Stable Audio 生成变得可预测且可重复,适用于电影、环境或实验性曲目。
Comfyui Stable Audio 工作流中的关键模型#
- Stable Audio Open 1.0。由 Stability AI 开发的开放权重潜在扩散模型,用于文本到音乐和声音设计。它将文本意图映射到音频潜在变量,并支持多样的音乐风格和结构。Repository • Weights
- T5-Base Text Encoder。通用文本模型,用于嵌入提示以调节 Stable Audio 生成。清晰、描述性的输入会导致更一致的音乐。Model card
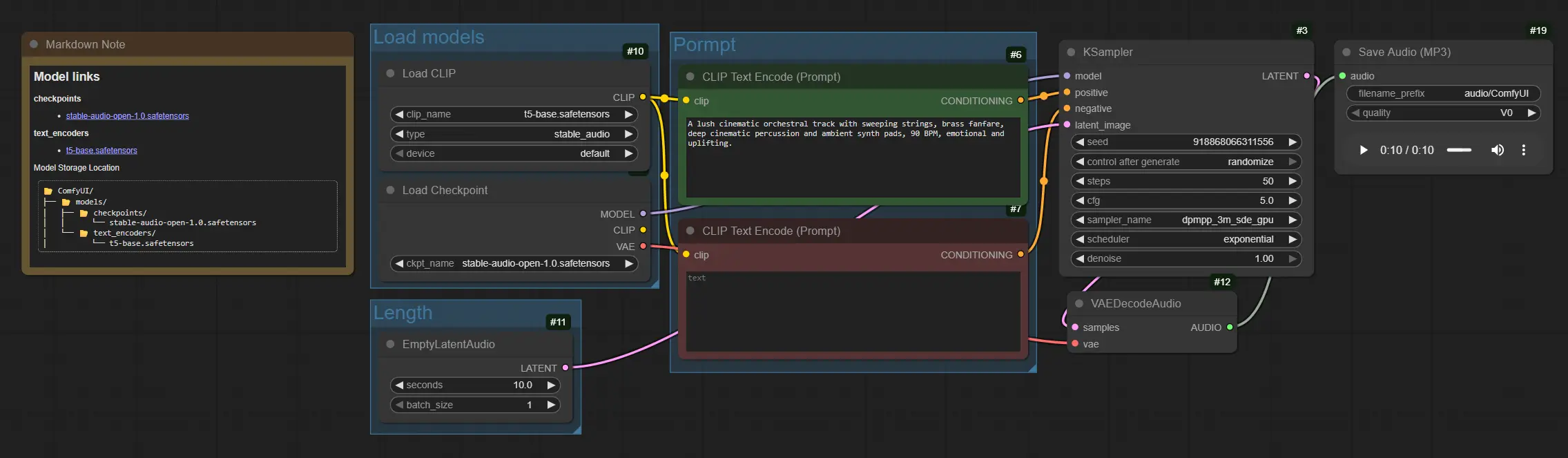
如何使用 Comfyui Stable Audio 工作流#
图表从模型加载到提示调节,然后采样、解码和保存。组的组织使您可以一次设置模型,调整长度,编写提示并渲染。
加载模型#
此组初始化核心资产。CheckpointLoaderSimple (#4) 加载 Stable Audio Open 1.0 检查点,其中包括扩散模型及其音频 VAE。CLIPLoader (#10) 加载用于调节的基于 T5 的文本编码器。加载后,这些模型为 Stable Audio 生成提供了基础,并在后续运行中保持驻留。
时长#
此组定义音频的长度。EmptyLatentAudio (#11) 创建一个具有所选时长的空潜在轨道,以便采样器知道要生成多少帧。较长的片段会消耗更多时间和内存,因此请从适度开始,然后逐步扩展。通过增加批次维度来探索想法时,您还可以制作多个变体。
提示#
此组将文本转化为扩散过程的指导信号。使用 CLIPTextEncode (#6) 编写包含乐器、流派、情绪、节奏和制作提示的正面提示,例如:“华丽的电影管弦乐队,扫荡的弦乐和铜管乐器,深沉的打击乐,环境垫,90 BPM,振奋人心。”使用 CLIPTextEncode (#7) 编写负面提示以抑制伪影,例如“刺耳的噪音、剪辑、失真。”它们共同引导 Stable Audio 朝向您想要的纹理和结构。
生成和导出#
KSampler (#3) 执行将空潜在变量转化为由文本编码指导的音乐潜在变量的扩散步骤。VAEDecodeAudio (#12) 将潜在音频转换回波形。最后,SaveAudioMP3 (#19) 写入一个 MP3 文件,以便您可以查看或直接拖入时间线。对于迭代工作,请调整文件名前缀以保持版本有序。
Comfyui Stable Audio 工作流中的关键节点#
CLIPTextEncode(#6) 此节点将您的正面提示编码为 Stable Audio 遵循的调节。优先考虑清晰的乐器列表、流派、情绪、节奏或 BPM,以及诸如“温暖”、“低保真”、“电影”或“环境”之类的制作术语。微妙的措辞变化可以显著影响构图。请参阅 ComfyUI 核心节点以了解一般行为。ComfyUICLIPTextEncode(#7) 负面提示有助于避免不需要的音色或混音问题。添加描述要去除的术语,例如“刺耳的、金属响声、故障弹出、无线电嘶嘶声。”保持简洁通常会产生更清晰的 Stable Audio 渲染。ComfyUIEmptyLatentAudio(#11) 控制片段的秒数和可选的批次计数以获得多种变体。增加秒数以获得较长的作品,注意计算随长度而缩放。使用批量生成可以从单个提示中试听多个 Stable Audio 版本。ComfyUIKSampler(#3) 驱动音频潜在变量的扩散过程。最具影响力的控制是steps、sampler、cfg和seed。提高steps以获得更精细的细节,调整cfg以平衡提示遵从性与创造性,并设置固定的seed以重现或改变想法。请参阅 ComfyUI 的采样器说明以获得一般指导。ComfyUISaveAudioMP3(#19) 将最终波形导出为 MP3。使用filename_prefix给版本标记标签并保持迭代整洁。在比较提示或种子时,将多个版本并排保存可以更快地选择 Stable Audio。ComfyUI
可选附加项#
- 像会话简报一样编写提示:乐器、流派、情绪、节奏或 BPM 以及混音形容词。
- 使用简短、集中的负面提示来减少嘶嘶声、刺耳或不需要的乐器。
- 在迭代文本时锁定
seed,然后更改seed以探索新的 Stable Audio 变体。 - 从较短的时长开始调整风格,然后在声音正确后延长。
- 每个概念保持一致的文件名前缀,以便稍后可以对 Stable Audio 进行 A/B 测试。
深入阅读的资源:Stable Audio 模型详细信息和示例 here,ComfyUI 核心和节点行为 here,以及 T5-Base 模型卡片 here。
致谢#
此工作流实现并建立在以下作品和资源之上。我们感谢 Stability AI 提供的 Stable Audio Open,感谢 comfyanonymous (ComfyUI) 提供的 ComfyUI 节点和工作流参考,以及感谢 Comfy-Org 和 ComfyUI-Wiki 提供的 Stable Audio Open 1.0 检查点和 T5-Base 文本编码器的贡献和维护。有关权威细节,请参阅以下链接的原始文档和存储库。
资源#
- Comfy-Org/Stable Audio Open 1.0 工作流
- GitHub: Stability-AI/stable-audio-open
注意:使用引用的模型、数据集和代码需遵守其作者和维护者提供的相应许可和条款。


