
SAM 3D ComfyUI 对象与身体运动控制#
此工作流通过基于Segment Anything的遮罩和深度推理,从单个图像提供3D感知的结构引导生成。它包括两个即用模式:对象模式用于提取并重建任何被遮罩的主体为纹理化的3D网格或3D高斯,身体模式用于构建身体部位感知的人体网格。SAM 3D ComfyUI设计强调空间一致性,非常适合对象运动控制、身体运动指导和为下游视频或3D管线创建可控资产。
基于开源SAM3D项目之上,此SAM 3D ComfyUI工作流将简单图像加遮罩转化为可导出的GLB、STL和PLY资产,具有姿势对齐和纹理烘焙功能。适合希望快速获得可控结果的创作者,无需微调。
注意: 建议在Medium、Large或XLarge机器上运行此3D "Object" 工作流。更大的机器类型可能导致运行时错误或不稳定结果。 "Body" 工作流适用于所有机器类型。 由于3D重建和优化的复杂性,"3D Object" 工作流可能需要约40分钟或更长时间完成。
Comfyui SAM 3D ComfyUI 工作流中的关键模型#
- Segment Anything Model (SAM)。用于高质量、可提示的分割,锚定空间约束。详情见原论文:Segment Anything。
- SAM3D Objects 预训练组件。提供深度、稀疏结构、SLAT生成、网格和高斯解码器以及纹理嵌入器用于对象重建。来源:PozzettiAndrea/ComfyUI-SAM3DObjects。
- SAM3D Body 预训练组件。提供身体部位感知处理以生成人体网格和调试视图。来源:PozzettiAndrea/ComfyUI-SAM3DBody。
- SAM3D 仓库中捆绑的单目深度估计器。提供相机内参、点图和深度感知遮罩以改善重建和姿势对齐。参见上述两个SAM3D仓库。
- 3D高斯溅射公式。支持快速、真实感的基于点的场景表示,适用于快速预览和某些渲染器:3D Gaussian Splatting for Real-Time Rendering。
如何使用 Comfyui SAM 3D ComfyUI 工作流#
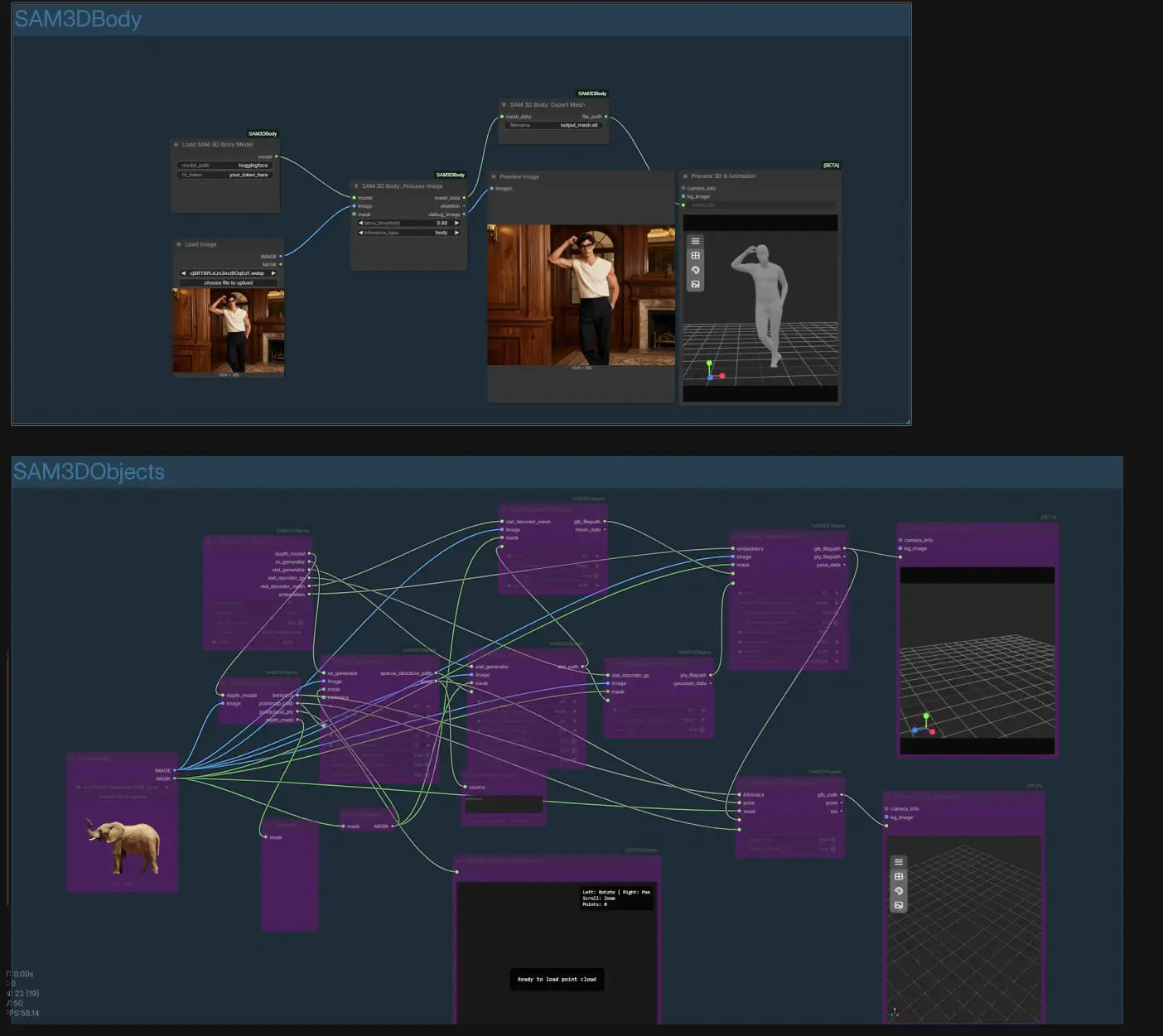
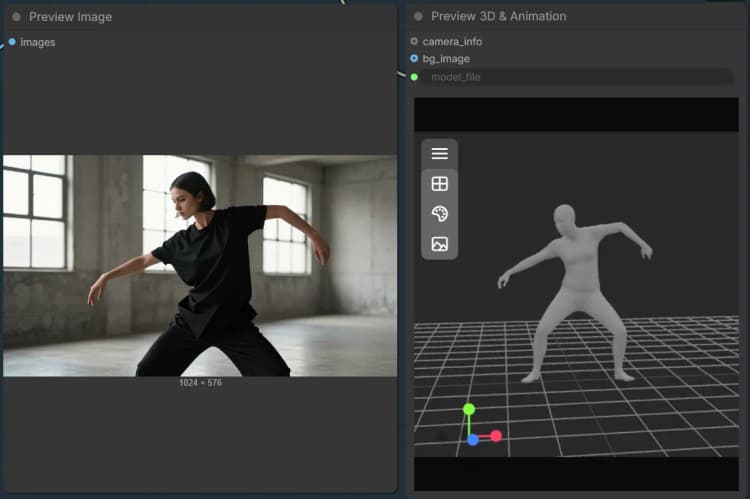
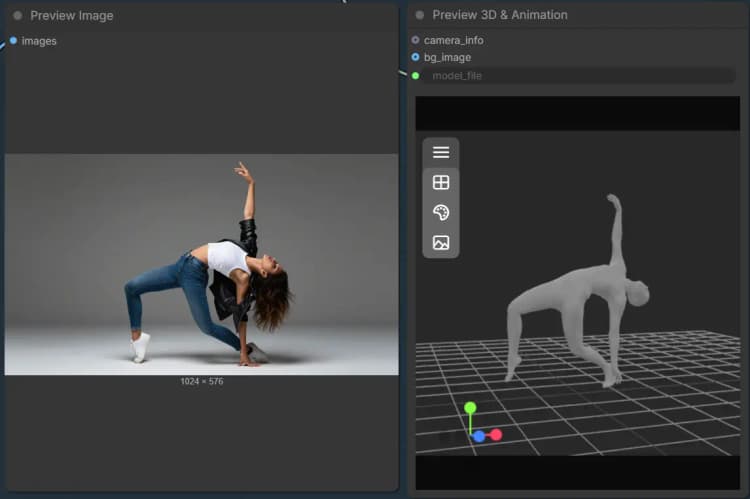
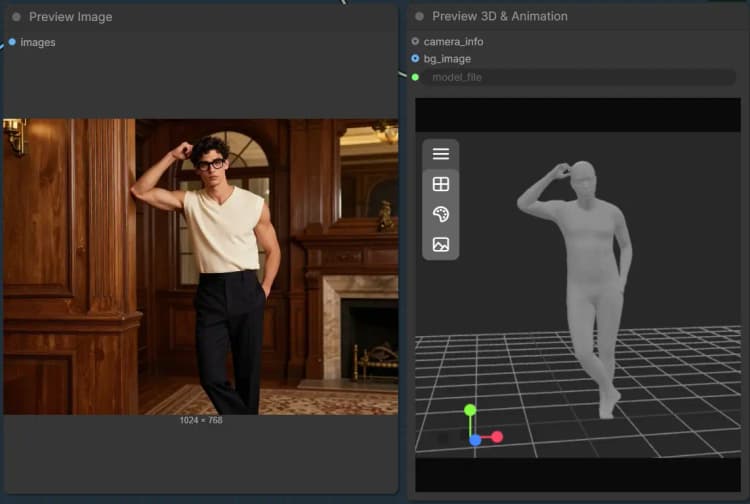
在高层次上,您加载单个图像及其遮罩,然后选择对象组或身体组。对象模式重建纹理化网格和3D高斯表示,具备可选的姿势精炼。身体模式构建身体部位感知网格并导出以便快速检查或下游使用。
SAM3DObjects 组#
此组将您的遮罩主体转化为3D资产。提供一个图像及其遮罩以隔离您想要控制的对象;工作流自动处理反转以将主体视为前景。估计深度和相机内参以生成点图,然后创建稀疏结构和初始姿势。从那里生成SLAT表示并解码为网格和3D高斯;纹理烘焙将外观从源图像转移到网格。最后,姿势优化精炼对齐,然后您可以预览和导出;参见 SAM3D_DepthEstimate (#59), SAM3DSparseGen (#52), SAM3DSLATGen (#35), SAM3DMeshDecode (#45), SAM3DGaussianDecode (#37), SAM3DTextureBake (#47), 和 SAM3D_PoseOptimization (#57)。
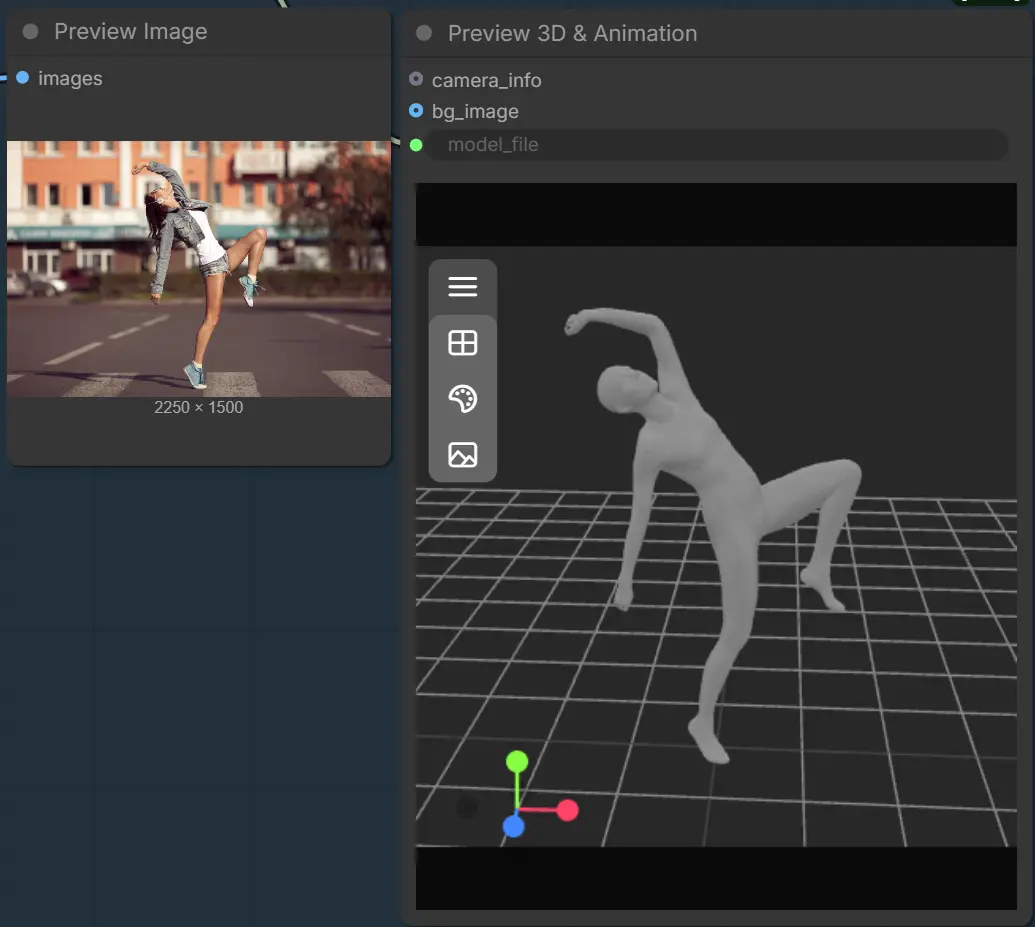
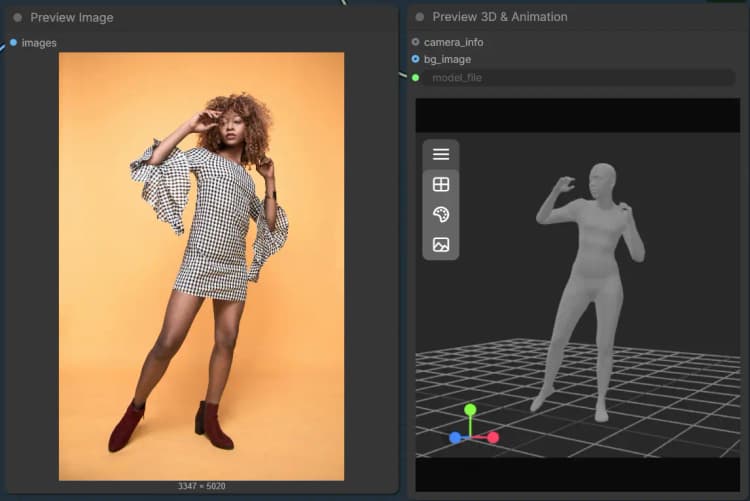
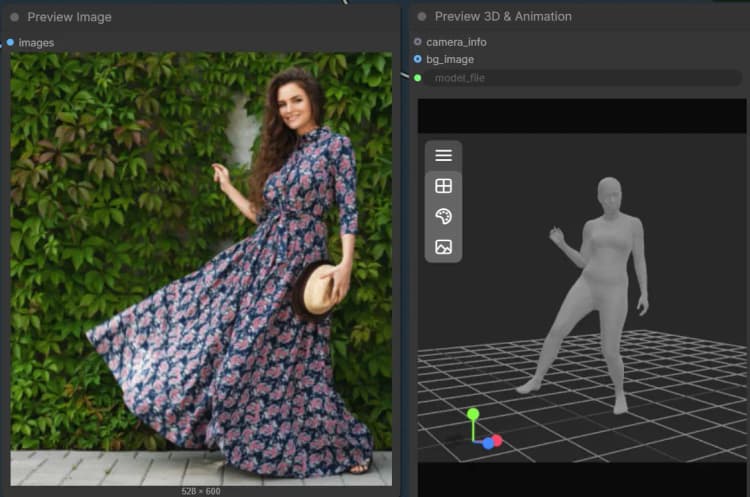
SAM3DBody 组#
此组专注于人类主体。提供一个图像和覆盖人物的遮罩。身体处理器生成一个身体部位感知网格和调试图像,以便您验证分割质量。您可以导出结果为网格以进行检查或装配,然后交互式预览。基本步骤通过 LoadSAM3DBodyModel (#62), SAM3DBodyProcess (#61), SAM3DBodyExportMesh (#64), 和 Preview3D (#65) 运行。
Comfyui SAM 3D ComfyUI 工作流中的关键节点#
LoadSAM3DModel (#44) 在一个地方加载所有对象模式权重,包括深度、稀疏结构生成器、SLAT生成器和解码器,以及纹理嵌入器。如果权重托管在Hugging Face上,输入您的令牌并保持提供者设置相应。除非有理由强制特定数据类型,否则使用自动精度。一旦加载,相同的句柄将为整个对象管线提供服务。
SAM3D_DepthEstimate (#59) 从您的输入图像估计单目深度、相机内参、点图和深度感知遮罩。好的构图很重要:保持主体适度居中,避免极端裁剪以获得更稳定的内参。使用内置的点云预览进行几何检查,然后再进行长时间烘焙。此处产生的内参和点图稍后用于姿势优化。
SAM3DSparseGen (#52) 通过结合图像、前景遮罩和深度输出,构建稀疏结构和初始姿势。如果您的遮罩过于松散,预期会有漂浮物和较弱的结构;收紧边缘以获得更清晰的结果。此节点还发出一个姿势对象,您可以预览以确保方向正确。此稀疏结构直接条件化SLAT生成器。
SAM3DSLATGen (#35) 将稀疏结构转换为紧凑且几何感知的SLAT表示。更清晰的SLAT通常来自精确的遮罩和良好的深度。如果您计划依赖网格输出而不是高斯,倾向于保留细节而不是极端稀疏的设置。发出的SLAT路径为两个解码器提供服务。
SAM3DMeshDecode (#45) 将SLAT解码为密封的3D网格,适合纹理化和导出。当您需要在DCC工具和游戏引擎中工作的拓扑时,选择网格。如果看到过度平滑或孔洞,请回到上游的遮罩和稀疏结构密度。这条路径生成的GLB将在后续进行烘焙和可选的姿势对齐。
SAM3DGaussianDecode (#37) 从相同的SLAT生成3D高斯表示,用于快速预览和某些渲染器。当您想快速验证几何和视点覆盖时,它很有用。如果您的高斯看起来噪声较多,改善遮罩或提高结构质量,而不是对该节点进行过度调节。生成的PLY也有助于纹理烘焙。
SAM3DTextureBake (#47) 将外观从源图像投射到解码的网格上。当您需要特写时使用更高的纹理分辨率,快速迭代时使用更快的预设。渲染器的选择会影响清晰度和速度;选择更快的选项用于预览,选择更高质量的选项用于最终效果。此节点输出纹理化的GLB以供预览和姿势精炼。
SAM3D_PoseOptimization (#57) 使用相机内参、点图、原始遮罩和初始姿势精炼GLB的对齐。若观察到细结构如四肢或把手周围的错位,请增加优化预算。保持前景遮罩干净,以防优化器漂移到背景几何。优化后的GLB即可以在3D预览中检查。
SAM3DBodyProcess (#61) 执行身体部位感知处理以生成人体网格和调试覆盖。选择适合您的用例的模式,例如全身与特定区域,以引导网格覆盖。如果手或头发夹住,请在这些区域细化遮罩以获得更好的保真度。导出为STL以快速检查或根据需要稍后转换。
可选额外功能#
- 使用干净、高对比度的遮罩。仅轻微羽化;硬边通常在SAM 3D ComfyUI对象模式下重建更好。
- 快速迭代时,首先依赖高斯路径,然后切换到网格解码和更高分辨率的纹理烘焙。
- 如果权重需要认证,请在加载节点中粘贴有效的Hugging Face令牌,然后再排队图形。
- 在长时间烘焙之前检查点云和姿势预览,以便及早发现构图或遮罩问题。
- 导出格式:GLB适用于DCC和引擎,PLY高斯用于兼容渲染器,STL从身体模式快速打印规模检查。
- 如果您计划使用SAM 3D ComfyUI输出驱动下游运动或多视角序列,请保持主体比例一致。
致谢#
此工作流实现并构建在以下作品和资源之上。我们诚挚感谢PozzettiAndrea为SAM 3D Objects和SAM 3D Body的贡献和维护。有关权威细节,请参阅下方链接的原始文档和仓库。
资源#
- PozzettiAndrea/SAM 3D Objects
- PozzettiAndrea/SAM 3D Body
- GitHub: PozzettiAndrea/ComfyUI-SAM3DBody
注意:使用引用的模型、数据集和代码须遵循其作者和维护者提供的相应许可证和条款。
