







OmniGen-ComfyUI 节点及其相关工作流程完全由 AIFSH 和 saftle 开发。我们完全归功于 AIFSH 和 saftle 的这项创新工作。在 RunComfy 平台上,我们只是向社区展示 AIFSH 和 saftle 的贡献。需要注意的是,RunComfy 与 AIFSH 和 saftle 之间目前没有正式的联系或合作。我们深深感谢 AIFSH 和 saftle 的工作!
ComfyUI OmniGen 工作流程让您可以操作照片以更改主体的衣服、背景、虚拟试穿、与名人自拍、添加或删除元素等等。您最多可以添加 3 张参考图像以获得所需的结果。
OmniGen#
OmniGen 是一个多功能、统一的图像生成模型,旨在通过简单和灵活性从多模态提示中创建多样化的视觉效果。与传统模型不同,它消除了对额外模块如 ControlNet 或预处理步骤如姿势估计的需求,使得通过基于文本的指令直接输出成为可能。受 GPT 无缝文本生成方法的启发,OmniGen 使用户能够以最小的努力对其进行微调,以适应任何创意或专业任务。其创新框架使图像生成更加便捷,激发了无限的视觉创意可能性。OmniGen 是通用图像生成的一个进步,激励了下一波变革性 AI 工具。
1.1 如何使用 OmniGen 工作流程?#
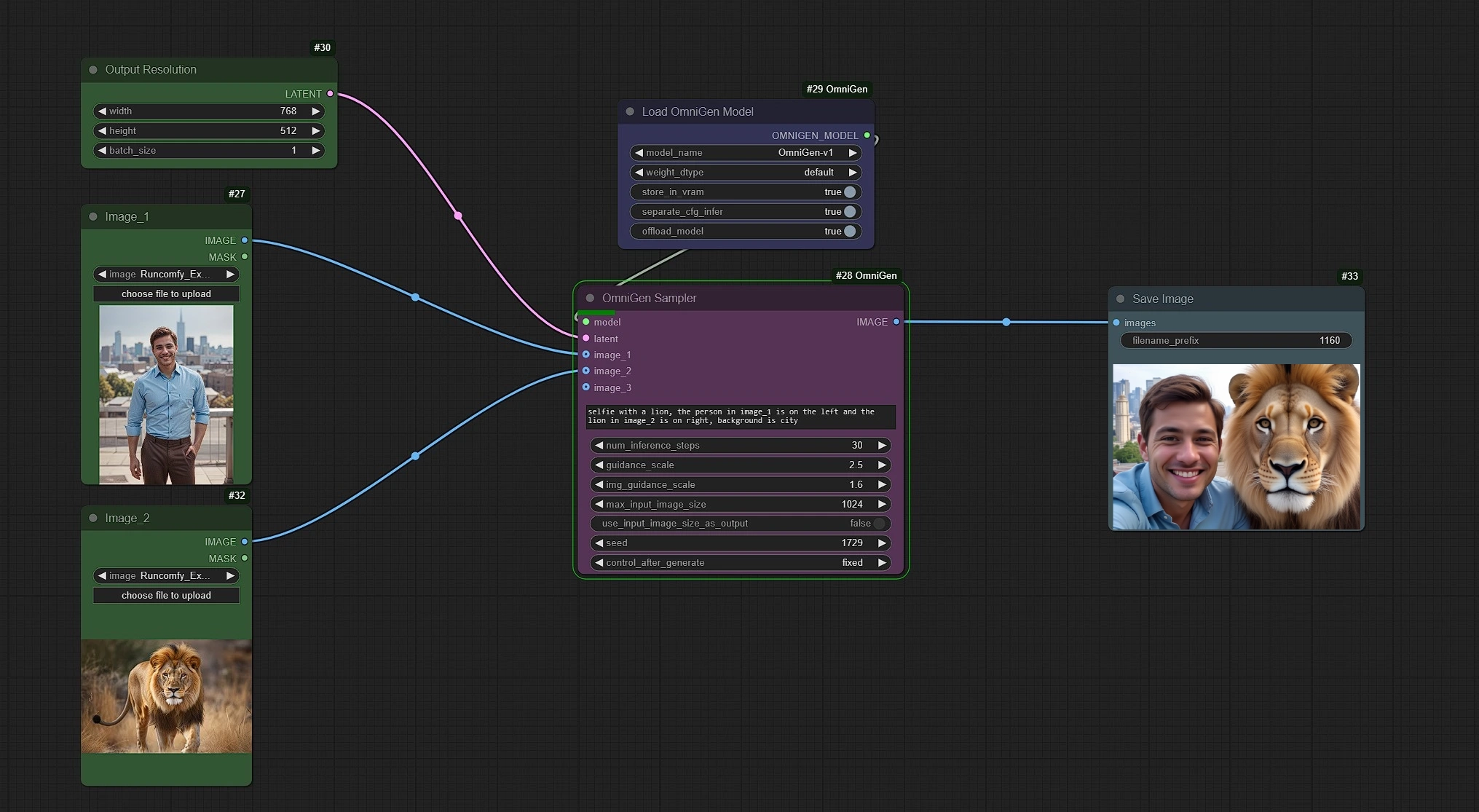
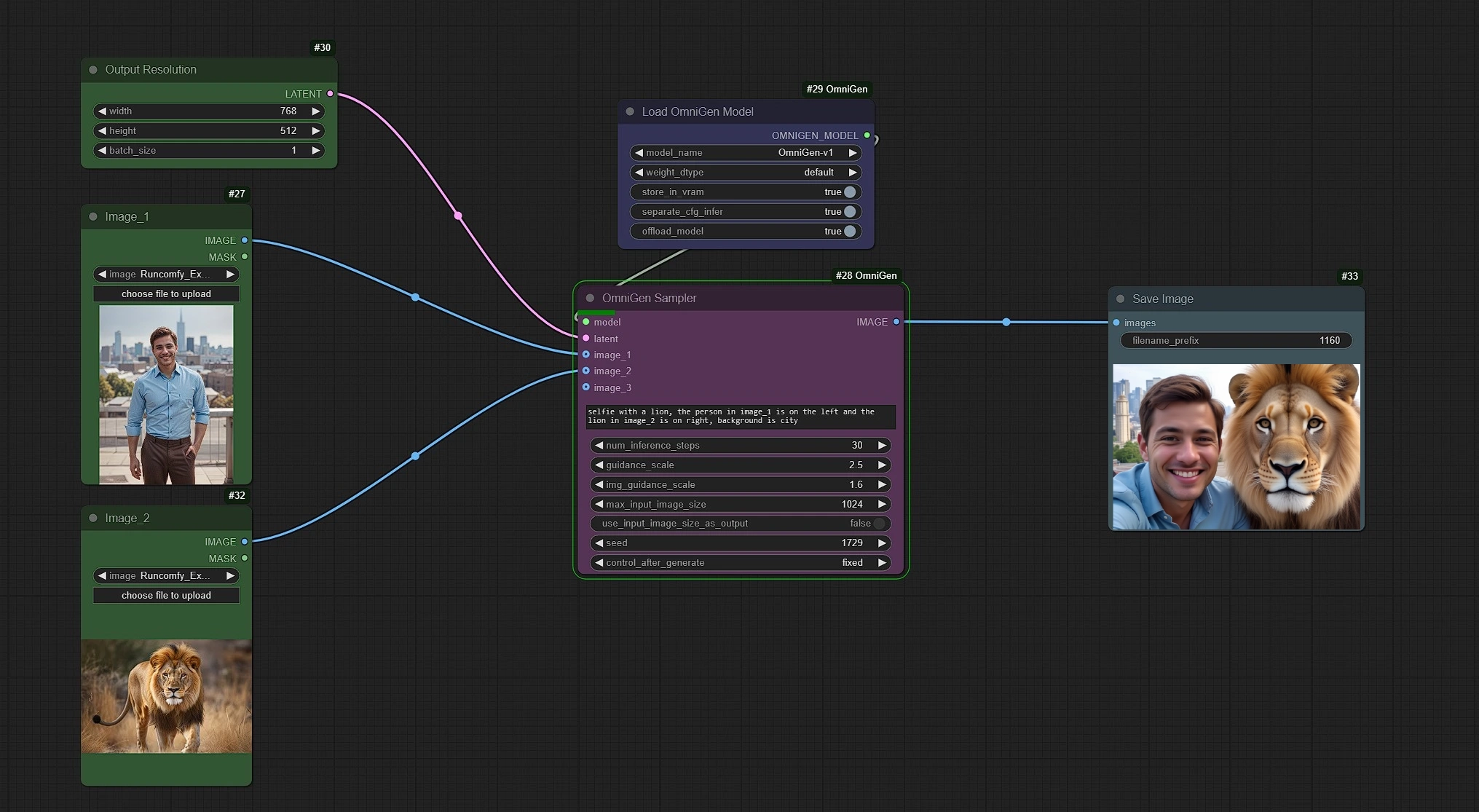
在此工作流程中,左侧绿色节点是参考图像和分辨率的输入。中间粉色和紫色节点是 OmniGen 反采样器和 OmniGen 模型加载器,右侧蓝色是图像保存节点。
- 上传您的参考图像。
- 输入您的分辨率和提示
- 点击队列
无需设置任何内容,渲染就是这么简单。
1.2 加载参考输入图像#
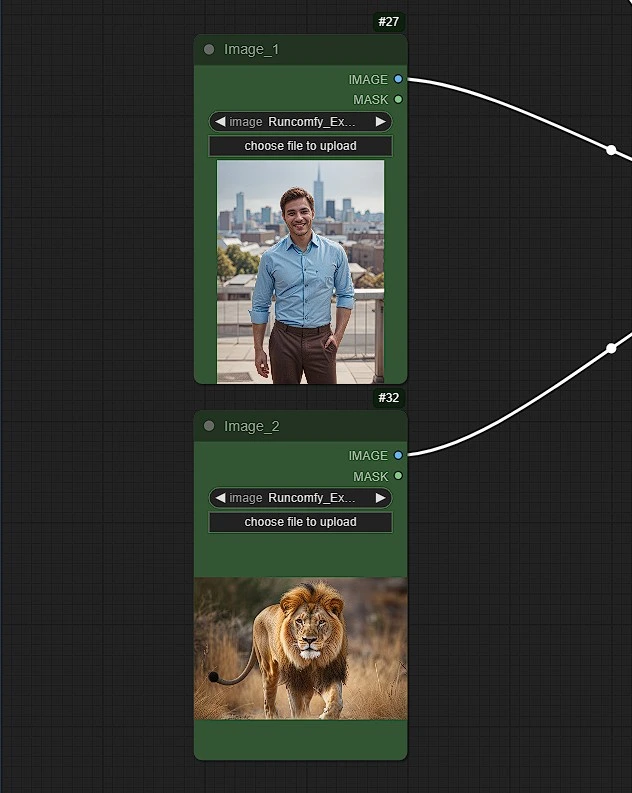
- 上传 1、2 或最多 3 张参考图像,元素如衣服、人物、名人、动物等。
- 这些图像将在提示中使用,触发词分别为 "image_1" 、 "image_2" 和 "image_3"。
1.3 分辨率#
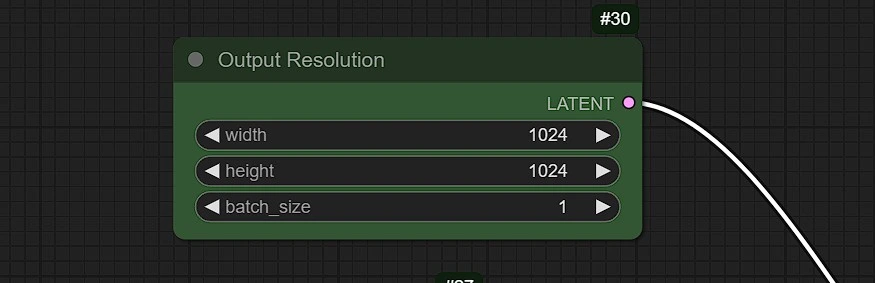
- 在此节点中设置输出图像的分辨率。
- 在更高图像分辨率(超过 1k)下,会消耗更多的 Vram 也可能出现双重图像或主体。
- 您可以更改采样器中的 batch_size 和 seed 以生成变体。
1.4 OmniGen 采样器和提示#
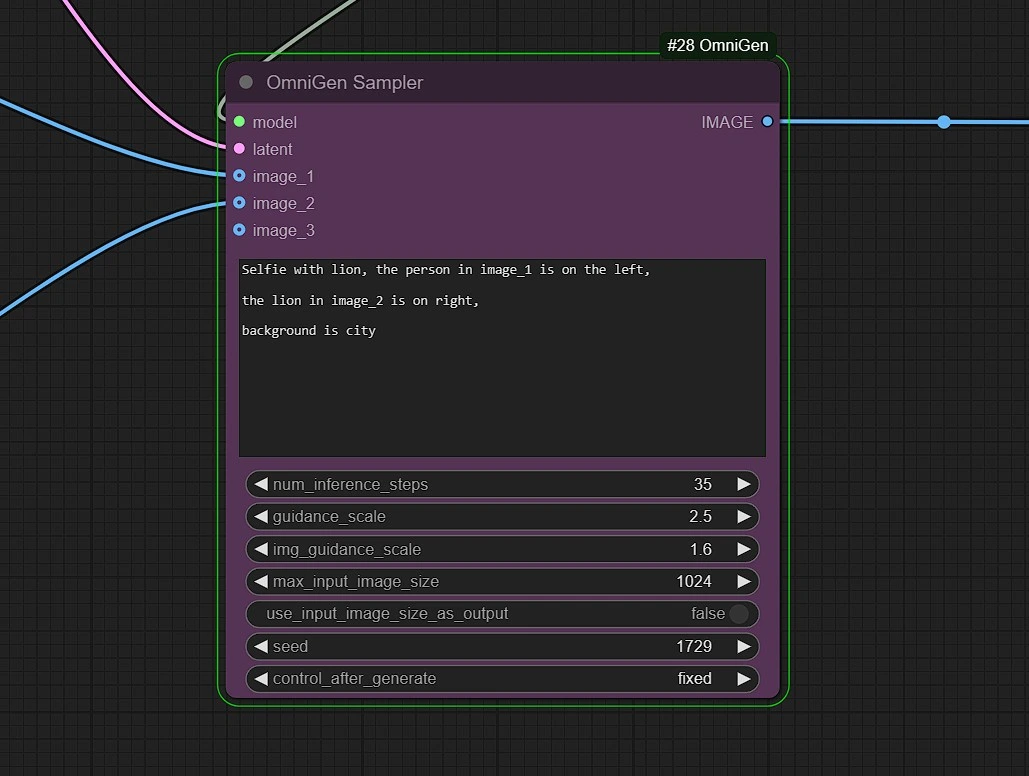
- 提示:根据您的参考图像添加提示。将输入图像表示为 "image_1" 、 "image_2" 和 "image_3"。
- 示例:image_1 中的人穿着 image_2 中的夹克。
num_inferene_step:这是为 OmniGen 设置采样步骤的,使用大约 25-35 的值以获得良好的效果img_guidance_scale:设置参考图像的权重/强度。max_input_image_size:限制输入的分辨率。
1.5 OmniGen 模型#
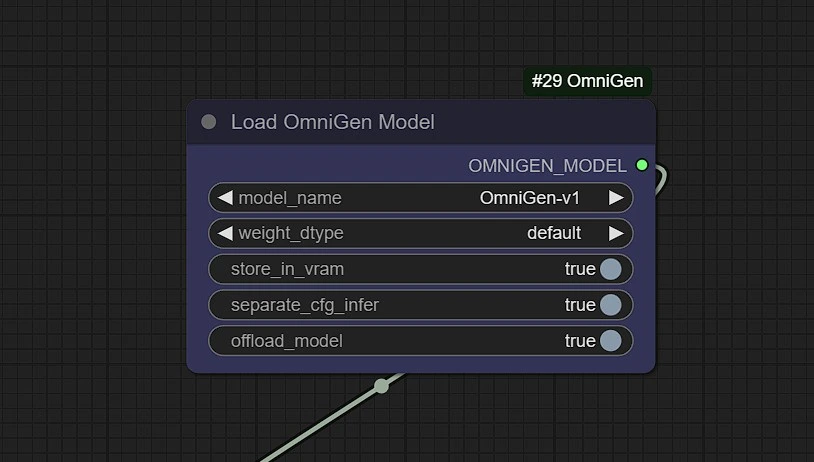
模型从此 Shitao's Hugging Face Repo 下载,在您的 comfyui/model/OmniGen 文件夹中由 runcomfy 服务器手动存储。可能需要 3-5 分钟在您的机器上创建本地副本。
您可以在这里上传其他 OmniGen 模型,当它们发布时。
OmniGen 通过提供一个统一、灵活的方式,简化工作流程并消除对额外工具或预处理的需求,从而重新定义了图像生成。其易于微调和多模态功能为创意和专业任务开辟了新的可能性。OmniGen 为未来更易获取和创新的 AI 驱动的视觉生成奠定了基础。

