
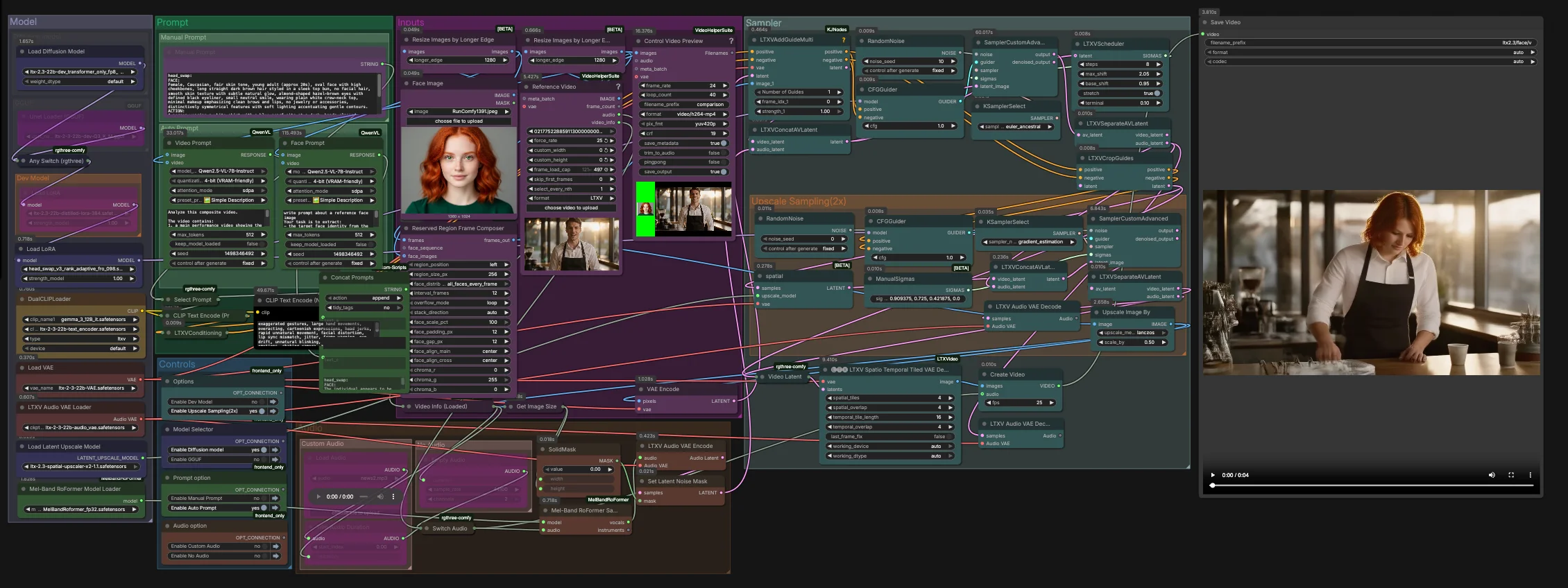
LTX-2.3-Video-Face-Swap for ComfyUI#
此工作流程利用 LTX 2.3 系列提供高保真、时间稳定的视频人脸替换。为 RunComfy 和 ComfyUI 构建,它将身份指导图像与目标视频和可选的音频指导融合,以在帧间保持表情、光照和运动。结果是逼真且抗闪烁的交换,在特写和中景镜头下表现出色。
创作者、VFX 艺术家和 AI 电影制作者可以使用 LTX-2.3-Video-Face-Swap 保持完全的创意控制:手动提示或从输入生成结构化提示,选择 dev、distilled、FP8 或 GGUF 变体,并通过时空解码和可选的 2x 潜在放大完成以获得清晰的细节。
ComfyUI LTX-2.3-Video-Face-Swap 工作流程中的关键模型#
- LTX 2.3 22B 视频扩散变压器。核心视频生成和编辑模型,推动身份保留和时间一致性。在 Lightricks/LTX-2.3 查看官方模型系列。
- LTX 2.3 文本编码器。图形将 LTX 2.3 文本编码器与 Gemma 3 12B 指令编码器配对,以改善视频编辑的提示对齐。示例工件:ltx-2-3-22b-text_encoder.safetensors 和 gemma_3_12B_it.safetensors。
- LTX 2.3 VAE 和音频 VAE。编码器/解码器用于压缩和重建视觉帧和音轨,同时保留细节和同步。查看 Lightricks/LTX-2.3 VAE 文件 和音频 VAE 变体在拆分存储库 vantagewithai/LTX-2.3-Split。
- LTX 2.3 空间放大器 x2。潜在空间 2x 放大器,在最终解码前提高空间保真度,非常适合面部细节。ltx-2.3-spatial-upscaler-x2-1.1.safetensors。
- 头部交换 LoRA。专门用于身份转移的自适应 LoRA,改善相似度和稳定性。当进行编辑时提高相似度和稳定性。示例:head_swap_v3_rank_adaptive_fro_098.safetensors。
- MelBandRoFormer。可选的音乐源分离模型,用于隔离人声以获得更强的嘴部运动指导。Kijai/MelBandRoFormer_comfy。
- 可选的部署变体。FP8 仅变压器权重,用于支持的 GPU 上的速度 Kijai/LTX2.3_comfy 和轻量级 UNet GGUF 构建,用于 CPU 或低 VRAM 场景 vantagewithai/LTX-2.3-GGUF。
如何使用 ComfyUI LTX-2.3-Video-Face-Swap 工作流程#
此图形分为两个阶段运行。第一阶段在本地潜在分辨率下执行核心交换,带有音频感知指导。第二阶段在潜在空间中进行上采样并在时空解码和最终多路复用到视频之前完善面部区域。
输入#
- 在
Face Image(LoadImage(#255)) 中加载您的身份图像。使用光线充足的正面或四分之三镜头以获得最可靠的身份提取。 - 在
Reference Video(VHS_LoadVideo(#393)) 中加载目标素材。通过ResizeImagesByLongerEdge和Control Video Preview(VHS_VideoCombine(#396)) 标准化并预览帧,以便在采样前快速检查。 ReservedRegionFrameComposer(#395) 准备对齐面部图像的引导帧,以帮助模型在条件期间专注于交换区域。
提示#
- 您可以在
Manual Prompt中手动描述所需的外观和动作,或让图形自动组合结构化提示。Video Prompt(AILab_QwenVL(#400)) 从视频中提取身体运动和场景,而Face Prompt(AILab_QwenVL(#401)) 从面部图像中提取身份细节。 Concat Prompts将身份和动作合并为一个简明指令,然后Select Prompt将您的手动文本或自动提示路由到CLIP Text Encode。负面提示文本单独编码以抑制常见的视频伪影。
模型#
Model组加载 LTX 2.3 UNet 或其 GGUF 变体,应用蒸馏 LoRA 和头部交换 LoRA,并引入 LTX VAEs 和双文本编码器。双编码器设置改善了口语内容和相机阻挡的对齐,而不会过度限制身份。- 如果您正在优化速度或内存,请在提供的模型选择器中切换 dev、distilled、FP8 transformer-only 或 GGUF。RunComfy 中不需要额外设置。
采样器#
- 第一阶段在
LTXVConcatAVLatent(#321) 中组合视频和音频潜在变量,然后通过CFGGuider(#326)、LTXVScheduler(#324) 和SamplerCustomAdvanced(#257) 去噪。LTXVAddGuideMulti(#392) 注入您的身份指导,使面部从一开始就稳定并随着时间保持稳定。 - 在第一次通过后,
LTXVSeparateAVLatent(#323) 分离流,以便LTXVCropGuides(#282) 可以专注于面部周围的编辑。这将计算集中在重要的地方并提高时间一致性。
放大采样 (2x)#
LTXVLatentUpsampler(#279) 在潜在空间中应用 LTX 2.3 x2 空间放大器。然后将上采样的视频潜在变量与音频潜在变量在LTXVConcatAVLatent(#287) 中重新组合,并通过CFGGuider(#284) 引导的第二个SamplerCustomAdvanced(#288) 传递进行优化。- 这种两阶段策略产生更清晰的皮肤、眼睛和头发,同时保持交换锁定在预期的身份上。
音频#
Audio组允许您通过Switch Audio路由原始音频、静音或修剪的片段。为了更强的唇部运动提示,选择的音轨通过MelBandRoFormerSampler(#355) 进行人声隔离,然后使用LTXVAudioVAEEncode(#364) 编码。- 稳固的噪声掩码 (
SetLatentNoiseMask(#365)) 防止嘴部区域以外的非预期音频驱动更改,同时仍利用语音时间来指导表情。
解码和导出#
- 最终帧使用
LTXVSpatioTemporalTiledVAEDecode(#377) 重建,时间感知平铺解码以避免接缝并保持运动连续性。CreateVideo(#292) 将图像与您选择的音频多路复用,SaveVideo写入完成的剪辑。
ComfyUI LTX-2.3-Video-Face-Swap 工作流程中的关键节点#
LTXVAddGuideMulti(#392)。在条件流中馈入对齐的面部指导,使模型从一开始就锁定目标身份。如果在快速运动中相似度漂移,则增加引导帧的数量或频率,而不是全局提高指导。LTXVCropGuides(#282)。自动将第二次通过集中在从第一阶段潜在变量和提示中派生的面部区域。用于在背景或手部争夺注意力时收紧编辑区域。SamplerCustomAdvanced(#257)。主要去噪通过,建立身份、光照和粗略运动。与LTXVScheduler配对以进行步长塑形,并在实验中保持采样器选择稳定,以使比较有意义。LTXVLatentUpsampler(#279)。在精炼前使用 LTX 空间放大器进行 2x 潜在放大。当您需要更清晰的毛孔、睫毛和帽子接缝而不引入后解码像素放大器的闪烁时使用此功能。SamplerCustomAdvanced(#288)。放大后的精炼通过。适度调整此处的指导,以在保留第一次通过设置的身份的同时锐化特征。LTXVSpatioTemporalTiledVAEDecode(#377)。时间感知解码器,减少跨帧的平铺接缝。如果在长剪辑上遇到 VRAM 限制,请优先调整其平铺布局而不是降低分辨率。MelBandRoFormerSampler(#355)。仅用于指导的人声分离。如果源音频嘈杂,请切换到原始或静音音频,以避免将伪影传播到嘴部运动中。
可选额外功能#
- 面部图像质量很重要。使用中性、光照良好的正面或轻微四分之三的照片,其年龄和表情与表演相似。
- 保持参考视频稳定。静态或三脚架拍摄可以产生最稳定的 LTX-2.3-Video-Face-Swap 结果,尤其是在中景和特写镜头中。
- 提示应简洁。用一个段落陈述场景和动作,将身份形容词保留给面部提示,而不是动作提示。
- 音频指导是可选的。清晰的语音改善嘴部形状;只有音乐的音轨几乎没有好处,因此选择静音以将计算集中在视觉上。
- 对于低 VRAM 或仅 CPU 运行,优先选择 GGUF UNet 构建;对于现代 GPU 上的高吞吐量,FP8 仅变压器权重是一个不错的默认选择。
- 负责任地使用。获取您交换的任何相似度的同意,并遵守适用的法律和平台政策。
鸣谢#
此工作流程实现并基于以下作品和资源构建。我们对 LTX-2.3 的 LTX-2.3 模型以及 EyeForAILabs 的 YouTube 教程的贡献和维护表示感谢。有关权威详情,请参阅下文链接的原始文档和存储库。
资源#
- LTX-2.3/LTX-2.3 模型
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube 教程
- 文档 / 发布说明: EyeForAILabs YouTube Tutorial
注意:所引用模型、数据集和代码的使用受其作者和维护者提供的各自许可证和条款的约束。