
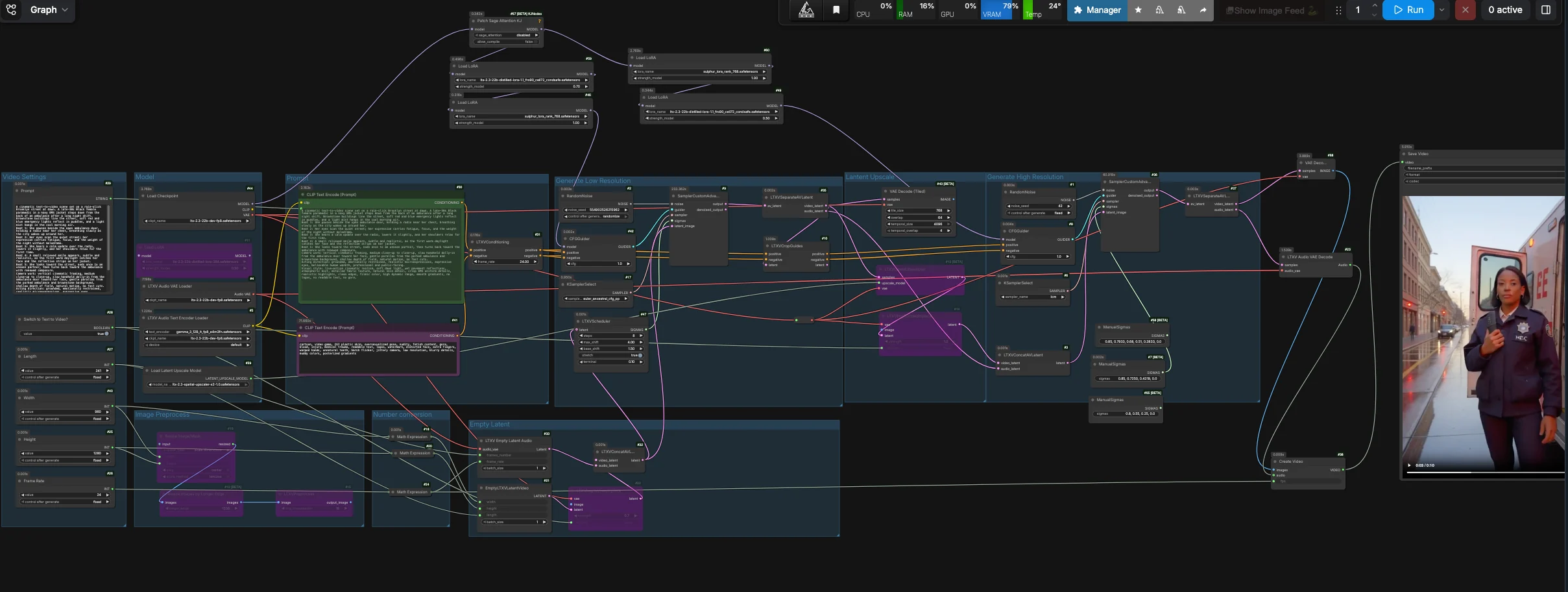
LTX 2.3 Sulphur T2V 工作流程:通过微表情、氛围和引导相机从提示到电影#
LTX 2.3 Sulphur T2V 工作流程将精心编写的提示转换为强调可信微表情、氛围场景细节和故事驱动运动的电影剪辑。它结合了精炼的 LTX 2.3 生成过程与 Sulphur 风格指导、可选的相机控制指导和稳定的平铺解码路径,以实现可靠的文本到视频结果。
专为希望获得扎实表演节拍和可控相机运动的创作者打造,此 ComfyUI 设置在叙事保真度与时间稳定性之间取得平衡。您可以运行纯文本到视频或从静态图像开始,然后将稳定的初始潜在解码为干净的编辑器友好序列,并附带占位音轨以便于编辑。
Comfyui LTX 2.3 Sulphur T2V 工作流程中的关键模型#
- Lightricks LTX-2.3 22B FP8 检查点。驱动生成和解码的基本文本到视频模型。模型库
- LTX-2.3 精炼 LoRA。保持质量的精炼适配器,同时实现更快、较低步长的采样和稳定的运动。模型系列
- LTX-2.3 空间放大器 x2。包含在图表中以供实验,默认导出路径使用稳定的初始解码以获得更清晰的结果。放大器
- LTX-2 19B LoRA 相机控制推拉左。为稳定的推拉运动和温和的视差提供可选指导,当您的场景需要时。LoRA
- LTX 文本编码器 (Gemma 3 12B 变体)。解释您的提示和节拍笔记的分词器和嵌入模型。文本编码器
- LTX 音频 VAE。打包静音音频流,以便生成的视频能在非线性编辑器中清晰加载。模型库
- Sulphur LoRA (捆绑)。为富有表现力但克制的微表情和电影色彩和谐而策划的风格和表演节拍适配器。
如何使用 Comfyui LTX 2.3 Sulphur T2V 工作流程#
此工作流程默认为稳定的初始文本到视频路径。它生成一致的视频潜在,分离视频和音频轨道,通过平铺 VAE 解码初始视频潜在,然后将帧和静音音频打包成可编辑的视频文件。潜在的放大和精炼节点仍在图表中以供高级实验,但默认输出绕过该分支以提高可靠性。
模型#
模型组加载 LTX-2.3 FP8 检查点、LTX 文本编码器、音频 VAE 以及整个过程中使用的适配器。精炼和 Sulphur LoRA 应用于基本模型,以便场景紧密遵循您的节拍和面部意图。如果您想要推拉运动,请在提供的 LoraLoader 节点中启用相机控制 LoRA。默认路径通过 CFGGuider (#42) 提供主采样器,而精炼分支则可用于手动实验。
提示#
在 Prompt 字段 (#29) 中将您的场景编写为简短的节拍线和简短的相机笔记。正文本由 CLIPTextEncode (#30) 编码,而 CLIPTextEncode (#41) 中的精选负面列表则压制 CGI 光泽、伪影、抖动和强烈闪烁。保持表演方向简洁并专注于眼睛、肩膀和呼吸,以解锁此工作流程调整的微表情。像“慢速手持推拉”和“温和视差”这样的相机语言很好地映射到调度器和可选相机 LoRA。
视频设置#
在视频设置组中选择输出 Width、Height、Frame Rate 和 Length (#40, #25, #26, #27)。内部,工作流程导出半分辨率潜在以提高生成过程的时间一致性,然后直接解码该稳定的潜在。使用 Switch to Text to Video? (#28) 运行纯 T2V,或将其关闭并通过图像预处理路径输入起始静止图像以进行受控的 I2V。尺寸应保持在常见倍数上,以实现快速、平铺友好的解码。
空潜在#
EmptyLTXVLatentVideo (#21) 根据您的设置创建一个空白视频潜在,LTXVEmptyLatentAudio (#33) 创建一个匹配的音频潜在,以便容器复用器对编辑器友好。如果您想从图像开始,LTXVImgToVideoInplace (#22) 可以将其注入潜在时间轴中,具有可控的 strength。当 bypass 开启时,节点生成一个纯文本驱动的初始化。
生成低分辨率#
音频和视频潜在由 LTXVConcatAVLatent (#32) 合并并由 LTXVScheduler (#47) 定时,设置一个视频感知的 sigma 调度以实现流畅的运动和相机移动。CFGGuider (#42) 将您的正面和负面条件与模型堆栈结合,SamplerCustomAdvanced (#9) 运行主要生成过程。然后 LTXVSeparateAVLatent (#35) 将剪辑重新拆分为视频和音频潜在;默认输出使用此稳定的视频潜在进行平铺解码。
可选潜在放大#
LTXVLatentUpsampler (#13) 使用 LatentUpscaleModelLoader (#39) 中的 LTX x2 空间放大器,保持时间结构不变。LTXVImgToVideoInplace (#14) 将放大的视频潜在与现有的音频轨道重新包装在一起。如果您想进行更高分辨率的精炼实验,此分支保持可用,但不连接到默认最终输出。
可选精炼#
精炼分支使用 CFGGuider (#8) 和 SamplerCustomAdvanced (#36) 进行短而手动的 sigma 调度。对于高级用户测试高分辨率路径非常有用,但默认工作流程输出绕过此分支,因为稳定的初始平铺解码在提供的 RunComfy 设置上提供更清晰的结果。
输出#
VAEDecodeTiled (#43) 从 LTXVSeparateAVLatent (#35) 解码稳定的视频潜在,LTXVAudioVAEDecode (#23) 生成一个让编辑器满意的静音轨道。CreateVideo (#38) 以您选择的 fps 组装序列,SaveVideo (#45) 将其写入磁盘。您将获得一个准备分享的视频,具有稳定的运动、干净的渐变和可控的相机流。
Comfyui LTX 2.3 Sulphur T2V 工作流程中的关键节点#
LTXVScheduler (#47)#
协调第一遍的视频感知 sigma 序列。其移位控制影响帧间运动的积累强度;更高的移位强调相机移动和更快的主体运动,而较低的值则有利于更稳定的构图。如果您启用相机控制 LoRA,适度的移位搭配最佳可避免夸张的漂移。
LTXVCropGuides (#10)#
从您的文本生成裁剪感知的调节通道,使重要区域,尤其是面部,以更高的保真度解析。使用它来引导微表情和眼睛细节,而不会过度增加全局采样器。如果特写看起来柔和,收紧您的表演节拍并让裁剪指南进行精细引导。
LTXVImgToVideoInplace (#22, #14)#
将静态图像转换为时间一致的潜在,或重新包装放大的潜在以进行可选精炼。strength 控制设置源图像在时间线中保留的程度;较低的值允许更多的生成性适应,较高的值保持构图和身份不变。切换 bypass 可在 I2V 和纯 T2V 之间干净切换。
LTXVLatentUpsampler (#13)#
在潜在中应用 LTX x2 空间放大器,以提升纹理和边缘以进行可选精炼实验。默认导出路径不依赖此节点,因此您可以在不改变主要输出链的情况下比较稳定的初始输出与精炼分支。
CFGGuider (#42, #8) 和 KSamplerSelect (#17, #6)#
这些配对定义模型如何严格遵循您的文本以及如何积极采样。保持指导保守以实现视频现实主义;提高它可能会增加提示的粘性,但可能导致运动僵硬或闪烁。默认导出依赖于主采样器以实现稳定运动,而次采样器则保留用于可选精炼测试。
可选附加功能#
- 编写 3 至 6 个节拍,描述意图和身体语言而不是情节;微表情从“眼睛柔和”或“肩膀松弛”等特定提示中涌现。
- 保持相机语言简洁:一个运动动词加一个主体,例如“慢速推拉到她的脸上”或“从停放的汽车中温柔视差”。
- 如果您想要静态构图,请禁用相机控制 LoRA 并略微降低调度器移位;如果需要更多移动,请启用 LoRA 并适度增加移位。
- 使用 32 的整数倍的宽度和高度,以实现可预测的平铺和解码。
- 为可重现性,在
RandomNoise(#2, #1) 中锁定种子;在探索变化时仅更改一个种子。 - 负面提示已抑制 CGI 伪影和闪烁;保持其专注,让您的正面文本承载风格和意图。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们感谢 RunningHub 提供的工作流程参考,Lightricks 提供的 LTX 2.3 模型、精炼 LoRA 和空间放大器,以及相机控制 LoRA,以及 Comfy-Org 提供的 LTX 文本编码器的贡献和维护。有关权威细节,请参阅下方链接的原始文档和库。
资源#
- RunningHub/Workflow Reference
- 文档 / 发布说明:Post
- Lightricks/LTX-2.3-fp8
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX-2.3
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
注:所引用模型、数据集和代码的使用须遵循其作者和维护者提供的各自许可证和条款。