
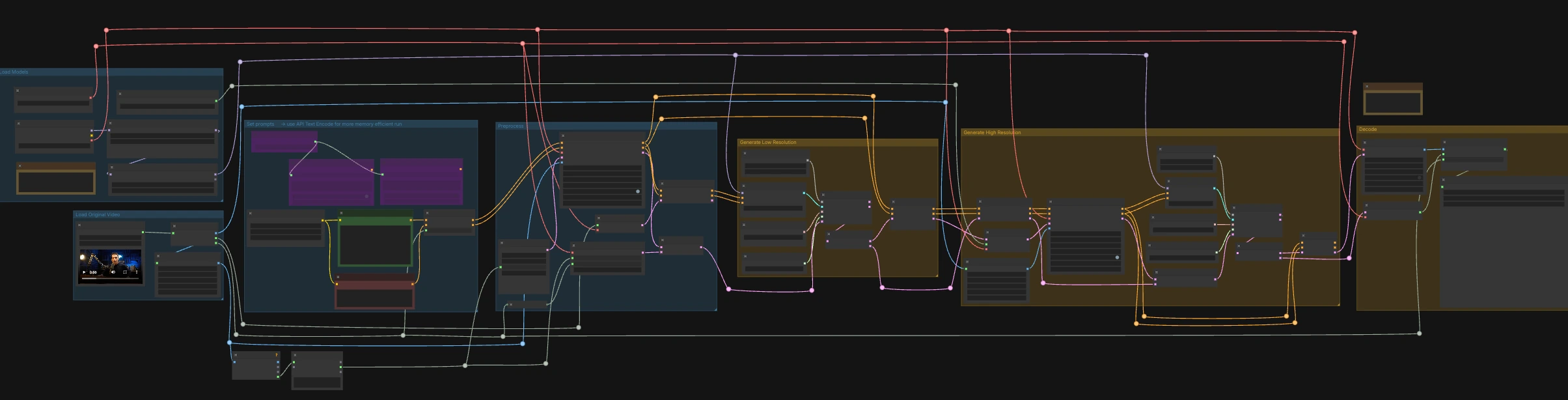
LTX-2.3 ICLoRA LipDub for ComfyUI#
LTX-2.3 ICLoRA LipDub是一个双通道、视频和音频控制的ComfyUI工作流程,在保持身份和运动一致的同时为对话者配音。它结合了Lightricks LTX-2.3文本和视频条件与LipDub IC-LoRA,以精确对齐嘴部运动到提供的语音,然后在更高分辨率下细化结果以获得清晰的细节。该图为RunComfy准备,具有标准化输入/输出名称,因此您可以可靠地交换媒体和重复运行。
这个ComfyUI LTX-2.3 ICLoRA LipDub工作流程非常适合需要多语言配音、改写或类似ADR修正的创作者,同时保留原始表演。提供已经包含目标语音的源视频,描述场景和人物应该说的话,工作流程将合成同步的视觉和音频到一个完成的剪辑。
ComfyUI LTX-2.3 ICLoRA LipDub工作流程中的关键模型#
- LTX-2.3 22B基础视频模型。生成视频的基础扩散模型,控制提示如何引导外观、运动和风格。
- LTX-2.3 IC-LoRA LipDub。专门用于唇同步的LoRA,条件模型遵循提供的语音并将嘴形对齐到音素,同时保留身份和头部运动。模型卡
- LTX-2.3音频VAE。将输入语音编码为音频潜在空间,可以注入文本条件并稍后解码回波形,确保时间保持与帧同步。
- LTX-2.3空间上采样器x2。在高分辨率细化通过前将视频潜在空间上采样到更高的空间分辨率,改善纹理而不改变运动。
- LTX-2.3蒸馏LoRA (384)。与基础检查点一起使用的强化LoRA,以提高细节和时间稳定性而不过度拟合参考帧。
如何使用ComfyUI LTX-2.3 ICLoRA LipDub工作流程#
此工作流程在两个协调阶段运行:低分辨率通过将时间和嘴形锁定到音频,然后是高分辨率通过上采样和细化细节,同时保持同步。首先加载已包含所需语音的源视频,然后编写您希望人物说的文本行。
加载原始视频#
LoadVideo (#5002)节点导入嵌入音频的源剪辑。GetVideoComponents (#5010)提取帧、音频和帧率;帧率在整个图中共享,因此视频和音频保持对齐。两个调整器,Resize Image/Mask (s1 size) (#5009)和Resize Image/Mask (s2 size) (#5003),为低分辨率和高分辨率通过准备工作图像流。帧数被测量并四舍五入为采样器友好的长度,以保持解码稳定。
加载模型#
CheckpointLoaderSimple (#5017)加载整个图中使用的LTX-2.3 22B基础模型和VAE。两个加载器,LoraLoaderModelOnly (#5018)和LTXICLoRALoaderModelOnly (#5012),在基础上添加蒸馏LoRA和IC-LoRA LipDub,因此生成器在保持身份的同时遵循语音。LTXVAudioVAELoader (#4010)提供编码/解码音轨的音频VAE。IC-LoRA加载器的latent_downscale_factor输出在此处故意未使用,因为LipDub训练假定全分辨率参考帧,与附带注释匹配。
设置提示#
在CLIP Text Encode (Positive Prompt) (#2483)中编写场景描述和确切的口语行。使用CLIP Text Encode (Negative Prompt) (#2612)来最小化不希望的特征或伪影。这些输入到LTXVConditioning (#1241),它将条件适应到视频领域并将帧率上下文向前传递。对于低VRAM运行,图中还包括基于API的编码器(🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980)和... - NEGATIVE (#4981)),通过LTX API KEY字符串 (#4979)进行门控;默认接线使用本地编码器。
预处理#
LTXVAudioVAEEncode (#5005)将源语音转换为音频潜在空间,LTXVSetAudioRefTokens (#5006)将该潜在空间注入文本条件,因此生成器“听到”时间和音素。EmptyLTXVLatentVideo (#3059)准备一个具有正确空间尺寸和帧数对齐输入的视频潜在占位符。LTXAddVideoICLoRAGuide (#5004)使用s1帧附加IC-LoRA参考指导,在采样前建立身份和嘴部区域关注。
生成低分辨率#
标准扩散循环由CFGGuider (#4828)、KSamplerSelect (#4831)、ManualSigmas (#4984)和SamplerCustomAdvanced (#4829)形成。采样器在由LTXVConcatAVLatent (#4528)组成的音频+视频潜在空间上运行,确保音频条件参与每一步。采样后,LTXVSeparateAVLatent (#4845)分离潜在空间,以便LTXVSetAudioRefTokens (#5013)可以冻结相同的语音表示用于高分辨率通过。此阶段将嘴形锁定到语音并在s1尺寸设定运动基线。
生成高分辨率#
LTXVLatentUpsampler (#4975)使用空间上采样器x2提升视频潜在空间,在增加空间细节容量的同时保持运动。LTXAddVideoICLoRAGuide (#5014)在高分辨率使用s2帧重新应用IC-LoRA,因此细化通过保留相同的说话者身份和准确的嘴形。如果更改高分辨率帧大小,请重新访问此节点以保持参考指导与目标输出一致。第二个扩散循环(CFGGuider (#4964)、KSamplerSelect (#4976)、ManualSigmas (#4985)、SamplerCustomAdvanced (#4971))在LTXVConcatAVLatent (#4969)保持冻结语音潜在空间同步时细化上采样潜在空间。LTXVCropGuides (#5011, #5015)管理安全裁剪和区域指导,因此面部在两个通过中保持正确框定。
解码#
LTXVTiledVAEDecode (#4995)使用瓦片将最终视频潜在空间转换为图像以提高VRAM效率,LTXVAudioVAEDecode (#4848)返回同步音频。CreateVideo (#4849)以原始帧率组装帧和音频,SaveVideo (#4852)以预填充的RunComfy名称写入文件;更改此值以为您的输出添加品牌标识。结果是一个完全同步的LTX-2.3 ICLoRA LipDub剪辑,准备好供审查或交付。
ComfyUI LTX-2.3 ICLoRA LipDub工作流程中的关键节点#
LTXICLoRALoaderModelOnly (#5012)#
加载LipDub IC-LoRA并将其附加到基础模型上,因此嘴部运动遵循输入语音而不覆盖身份。如果需要更强或更微妙的唇控,请在此处调整LoRA权重;保持它与您在堆栈中应用的任何其他LoRA协调,以避免过度条件化。
LTXAddVideoICLoRAGuide (#5004)#
在低分辨率阶段使用缩小的参考帧应用IC-LoRA指导。这是工作流程首次锁定身份和嘴部区域关注的地方;通过切换指南进行A/B测试,查看参考指导对时间和发音的影响。
LTXAddVideoICLoRAGuide (#5014)#
在高分辨率使用s2帧重新应用IC-LoRA指导,因此细化通过保留相同的说话者身份和准确的嘴形。如果更改高分辨率帧大小,请重新访问此节点以保持参考指导与目标输出一致。
LTXVSetAudioRefTokens (#5006)#
将编码的语音绑定到文本条件,以便采样器将视觉音素与音素对齐。在两个通过中使用相同的音频潜在空间以获得稳定的结果;此图表自动处理此问题,但如果您在运行中更换音频,您应该刷新条件和连接的潜在空间。
LTXVLatentUpsampler (#4975)#
使用LTX-2.3空间上采样器x2上采样视频潜在空间,在高分辨率采样器之前为细节留出空间。如果VRAM紧张,请将其与较小的s2尺寸或解码器中的较轻瓦片配对,以平衡质量和吞吐量。
LTXVTiledVAEDecode (#4995)#
使用瓦片解码最终潜在空间为帧,以适应有限GPU上的大输出。调整瓦片数量和重叠以在速度和内存占用之间进行权衡;更少的瓦片速度更快但需要更多VRAM,而更多的瓦片减少VRAM但以时间为代价。
可选附加项#
- 配音提示:包括您希望说的确切词语;模型不会自动翻译。使用目标语言的母语脚本,保持单一说话者,并尽量与原始行长度相似,以便节奏保持自然。
- 性能提示:如果遇到VRAM限制,请在
Resize Image/Mask (s2 size)(#5003)中减少s2调整,并在LTXVTiledVAEDecode(#4995)中增加瓦片。为了可重复性,保持RandomNoise种子在两个通过中固定。 - 工作流程默认值:示例输入文件名在
LoadVideo(#5002)中预填充,保存器设置一致的输出名称。更换两者以批量运行多个LTX-2.3 ICLoRA LipDub而不覆盖结果。 - 裁剪:如果面部在边缘附近漂移,请调整
LTXVCropGuides(#5011, #5015)以便嘴部区域在两个通过中保持稳定裁剪。
致谢#
此工作流程实现并基于以下作品和资源。我们对Lightricks的LTX-2.3-22b-IC-LoRA-LipDub模型和RunComfy的共享ComfyUI工作流程(云存储源)表示感谢,感谢他们的贡献和维护。有关权威详情,请参考下列链接的原始文档和存储库。
资源#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- 文档/发布说明: RunComfy共享工作流程
注意:使用参考的模型、数据集和代码需遵循其作者和维护者提供的各自许可证和条款。