
LTX 2.3 IC-LoRA: ComfyUI 中的动作跟踪视频生成#
此工作流程将 LTX 2.3 IC-LoRA 系统引入 ComfyUI,让您在自由使用提示或额外的 LoRAs 进行风格化的同时引导动作和场景结构。它将 LTX-2.3 视频生成器基于深度、姿态和边缘等参考信号进行条件化,支持动作转移、摄像机锁定和可预测的构图。
从事视频到视频、动作重定向和控制 AI 动画的创作者会发现 LTX 2.3 IC-LoRA 将动作控制与视觉风格分开。您可以通过文本和风格 LoRAs 引导外观,通过结构化指南引导动作,所有这些都在单个 ComfyUI 图中完成。
Comfyui LTX 2.3 IC-LoRA 工作流程中的关键模型#
- Lightricks 的 LTX-2.3。高保真潜在视频扩散转换器,生成时间一致的序列,并支持结构和动作控制的条件化。 Hugging Face: Lightricks/LTX-2.3
- LTX 2.3 IC-LoRA 联合控制权重。上下文 LoRA 权重旨在将结构化指导信号注入 LTX-2.3,以实现精确的动作和几何控制。与工作流程的模型链一起提供,并在生成之前加载。
- LTX-2.3 的视频和音频 VAEs。与 LTX-2.3 配对的潜在编码器/解码器,用于在采样期间压缩和重建视频和音频特征。在图中预配置,并在使用量化构建时可切换。分包示例在此处提供:Hugging Face: unsloth/LTX-2.3-GGUF
- Depth Anything V2。稳健的单目深度估计,用于锁定摄像机运动或在生成期间保持场景布局。Hugging Face: LiheYoung/Depth-Anything-V2
- DWPose。轻量级多人体姿态估计器,通过关键点重新定位或保持角色动作。Hugging Face: yzd-v/DWPose
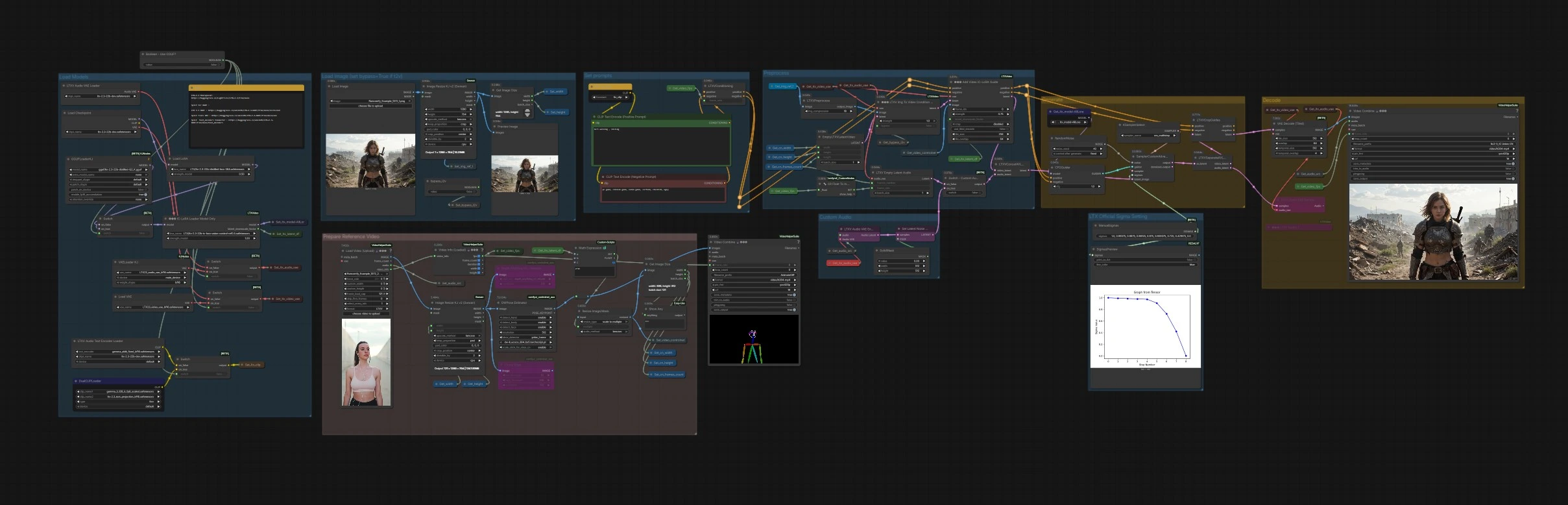
如何使用 Comfyui LTX 2.3 IC-LoRA 工作流程#
图表被组织成清晰的组。您准备提示和参考视频,选择一个或多个结构化指南,然后生成和导出。
设置提示#
使用 CLIP Text Encode (Positive Prompt) (#2483) 和 CLIP Text Encode (Negative Prompt) (#2612) 描述视觉风格并排除不需要的特征。文本编码器加载在模型组中,并路由到 LTXVConditioning (#1241),它还接收工作帧速率,以便条件与您的剪辑时间匹配。保持提示集中在外观上,因为 LTX 2.3 IC-LoRA 将处理动作和结构。
预处理#
将参考剪辑加载或传递到 VHS_LoadVideo (#5182)。帧在 ImageResizeKJv2 (#5080) 中调整大小,并送入指南提取器:DepthAnythingV2Preprocessor (#5064) 用于深度,DWPreprocessor (#4986) 用于姿态,CannyEdgePreprocessor (#4991) 用于边缘。下游调整大小节点确保指南映射与模型友好的倍数匹配,GetImageSize (#5029) 记录宽度、高度和帧数,以供管道的其余部分使用。生成的指南图像序列由 Set_video_controlnet (#5100) 存储,以供 IC-LoRA 使用。
加载模型#
基础模型和 LoRAs 在此组中组装。CheckpointLoaderSimple (#3940) 加载 LTX-2.3;LoraLoaderModelOnly (#4922) 应用蒸馏 LTX LoRA 以提高质量和速度;LTXICLoRALoaderModelOnly (#5011) 添加 LTX 2.3 IC-LoRA 权重,并发布所需的潜在缩放因子。为视频和音频加载 VAEs,Boolean - Use GGUF? (#5158) 可以通过 GGUFLoaderKJ (#5150) 使用兼容的文本编码器和 VAEs 在 VRAM 紧张时切换到量化 GGUF 构建。
加载图像(如果 t2v,设置 bypass=True)#
如果您希望使用静态参考或第一帧锚定构图,请使用 LoadImage (#2004)。它通过 ImageResizeKJv2 (#5076) 调整大小,并预览以进行快速检查。布尔值 bypass_i2v 控制是否使用图像;对于纯文本到视频的 LTX 2.3 IC-LoRA,将其设置为 True。
生成#
EmptyLTXVLatentVideo (#3059) 创建潜在画布。如果启用图像锚定,LTXVImgToVideoConditionOnly (#3159) 只注入图像的结构信息,而不烘焙风格。核心步骤在 LTXAddVideoICLoRAGuide (#5012) 中完成,它使用 IC-LoRA 加载器的潜在缩放因子将您选择的指南序列附加到模型。音频条件也通过 LTXVEmptyLatentAudio (#3980) 或自定义音频路径流入潜在空间。CFGGuider (#4828)、KSamplerSelect (#4831)、ManualSigmas (#5025) 和 SamplerCustomAdvanced (#4829) 然后执行去噪,以合成最终的潜在视频,同时尊重提示和 LTX 2.3 IC-LoRA 控制。
解码#
LTXVSeparateAVLatent (#4845) 分离生成的音频和视频潜在空间以进行解码。LTXVCropGuides (#5013) 在需要时对齐和裁剪,然后 VAEDecodeTiled (#4851) 高效地重建帧。VHS_VideoCombine (#5070) 将帧合成为 MP4,默认使用参考剪辑的音频。如果您希望单独试听生成的音频潜在空间,可以使用 LTXVAudioVAEDecode (#4848) 解码。
准备参考视频#
此辅助区域显示参考帧管道。VHS_VideoInfoLoaded (#5073) 提取 fps 和持续时间,这些信息被传播到条件节点和导出器,以确保时间同步。一个小的合并节点提供源序列的快速视觉预览,以进行理智检查。
自定义音频#
如果您希望进行音频感知生成,参考音频将通过 LTXVAudioVAEEncode (#5146) 编码,并在 SetLatentNoiseMask (#5148) 中应用简单的掩码。标题为 Switch - Custom Audio? (#5149) 的开关在空或编码的音频潜在空间之间进行选择,然后在 LTXVConcatAVLatent (#4528) 中连接。在最终导出时仍默认使用参考音频;如果您更喜欢模型解码的音频,请将 LTXVAudioVAEDecode 输出路由到导出器的音频输入。
LTX 官方 Sigma 设置#
调度节点 ManualSigmas (#5025) 定义了一个简明的 sigma 配置文件,针对 LTX-2.3 进行了调整,SigmasPreview (#5142) 可视化它,以便您可以推理关于噪声分配随时间的情况。这样您可以在保持 LTX 2.3 IC-LoRA 特有的时间稳定性的同时,在速度和细节之间进行权衡。
Comfyui LTX 2.3 IC-LoRA 工作流程中的关键节点#
LTXICLoRALoaderModelOnly(#5011)。加载 LTX 2.3 IC-LoRA 权重,并输出指南注入器所需的潜在缩放因子。如果您添加额外的风格 LoRAs,请将它们放在此加载器之前,以保持动作指导的主导地位。LTXAddVideoICLoRAGuide(#5012)。深度、姿态或边缘序列作为上下文指导进入模型的点。调整其强度,以在严格的结构遵从和从您的提示和风格 LoRAs 中获得的风格自由之间进行平衡。LTXVImgToVideoConditionOnly(#3159)。提供可选的图像到视频条件,仅从静态图像中传输构图和粗略结构。在 i2v 和纯文本到视频之间切换时,使用其bypass切换。CFGGuider(#4828)。控制模型相对于 LTX 2.3 IC-LoRA 指导遵循提示的强度。当风格忠实度最重要时增加指导,减少它以在最小漂移的情况下保留动作和几何。SamplerCustomAdvanced(#4829) 和ManualSigmas(#5025)。一个紧凑的调度和多步采样器配对,为 LTX-2.3 提供良好的时间一致性。如果您修改调度,请保持其平滑递减,并在进行较长渲染之前测试短片段。
可选附加项#
- 选择合适的指南。使用深度锁定摄像机和布局,使用姿态进行角色动作,使用边缘处理刚性物体或干净的轮廓。如果它们描述不同的方面,可以混合使用两个指南。
- 保持尺寸对采样器友好。预处理器已经将尺寸四舍五入到模型友好的倍数;保持您的源接近目标纵横比,以最大限度地减少填充。
- 在不破坏动作的情况下样式化。在 IC-LoRA 加载器之前添加一个轻风格 LoRA,并保持其权重适中,以便 LTX 2.3 IC-LoRA 可以保持几何和时间。
- 低 VRAM 模式。切换使用 GGUF 以运行量化蒸馏模型和匹配的文本编码器/VAEs,如果您的 GPU 受限。 Hugging Face: unsloth/LTX-2.3-GGUF
- 稳定的时间。参考视频读取的帧速率被注入到条件和导出器中,以便动作和音频保持对齐。如果您覆盖 fps,请在条件和导出中保持一致。
致谢#
此工作流程实现并基于以下作品和资源构建。我们感谢 @Benji’s AI Playground 的 LTX 2.3 IC-LoRA Source 提供的源材料和指导。有关权威细节,请参阅以下链接的原始文档和存储库。
资源#
- LTX 2.3 IC-LoRA Source
- 文档 / 发布说明:YouTube @Benji’s AI Playground
注意:使用引用的模型、数据集和代码受制于其作者和维护者提供的各自许可和条款。
