
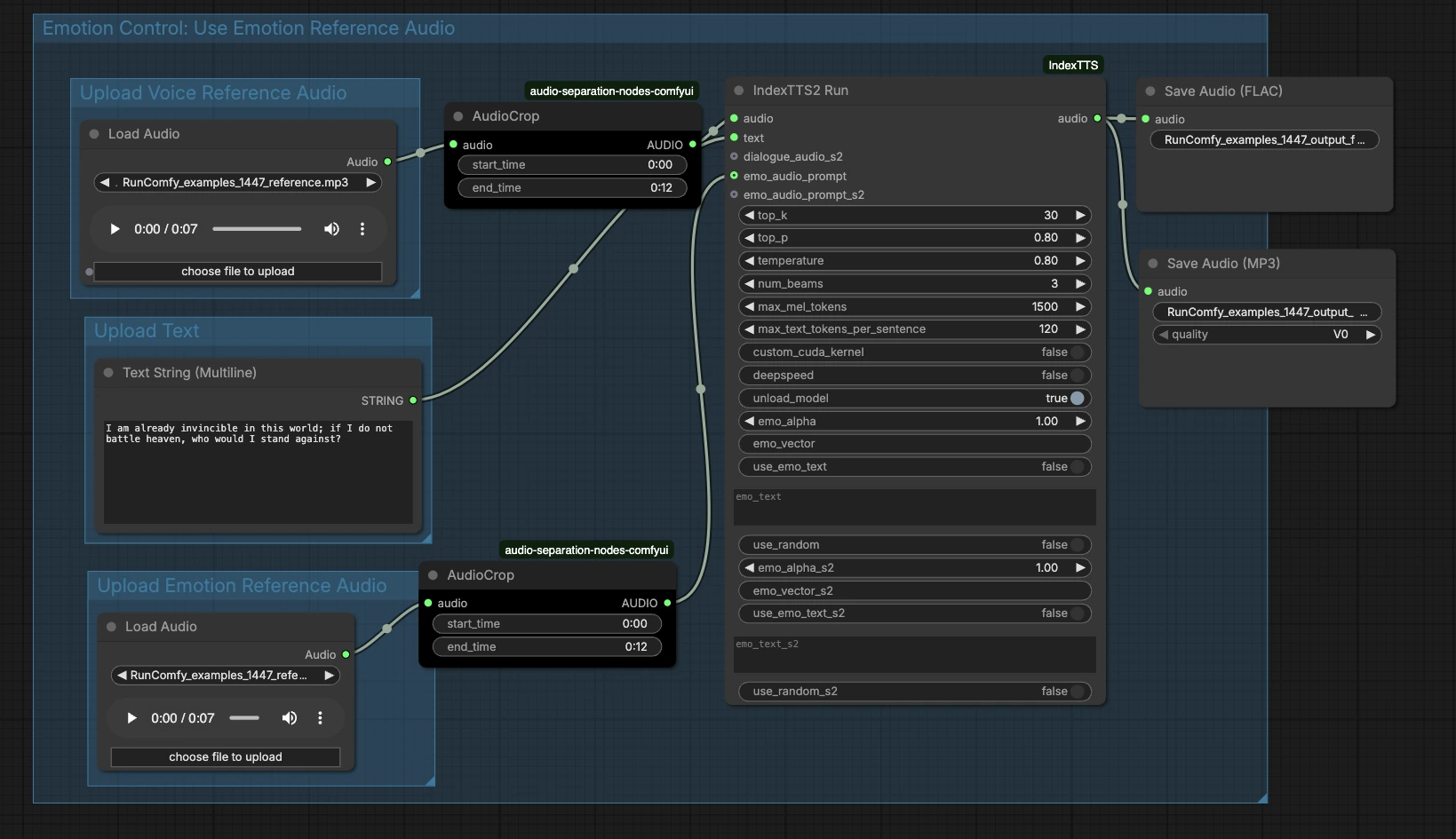
IndexTTS2 ComfyUI 工作流程:使用参考音频进行情感语音克隆#
此 IndexTTS2 ComfyUI 工作流程将短参考片段转换为自然、富有表现力的语音,匹配说话者的音色和风格。您提供干净的参考音频、可选的情感提示和您的脚本;图表生成高质量语音克隆,并将其导出为 FLAC 以供存档使用或 MP3 以便快速共享。
该工作流程围绕 IndexTTS‑2 模型和 ComfyUI IndexTTS 节点构建,非常适合需要快速、可复制情感 TTS 的创作者、角色设计师、教育者和 RunComfy 用户。一切都在 ComfyUI 内部进行,因此您可以检查输入、调整设置,并快速迭代旁白、对话和配音示例。
Comfyui IndexTTS2 ComfyUI 工作流程中的关键模型#
- IndexTTS‑2 由 IndexTeam 提供。一个现代的文本到语音系统,执行参考条件语音克隆和表现性韵律控制。它基于一个简短的说话者示例和可选的情感提示,从文本中呈现自然语音。有关架构和训练的详细信息,请参阅 Hugging Face 上的模型卡和附带的论文:IndexTTS‑2,IndexTTS 项目,IndexTTS‑2 论文。
如何使用 Comfyui IndexTTS2 ComfyUI 工作流程#
在高层次上,图表接受三个输入——参考音色音频、文本和可选的情感音频——然后运行生成并导出结果。下面的组显示了添加输入的位置以及它们如何连接到最终语音。
上传语音参考音频#
此组准备说话者身份。将目标声音的干净样本加载到 LoadAudio (#13),最好是一个单一的说话者清晰地讲话,没有音乐或效果。使用 AudioCrop (#37) 隔离一个稳定的片段,以便系统学习一致的音色。具有稳定音高和中性表达的短片段通常会产生最可靠的克隆。裁剪后的参考被发送到生成器进行条件设置。
上传文本#
在 PrimitiveStringMultiline (#14) 中输入您的脚本。清晰的标点符号有助于模型推断停顿和重音,因此请按照您希望的方式编写文本。如果您计划多句阅读,请保持每句话的结构良好,避免使用表情符号或不常见的符号。文本直接流入合成节点进行渲染。
上传情感参考音频#
提供一个可选的片段,捕捉您想要的情感或表达方式——例如兴奋、平静或忧郁——通过 LoadAudio (#15)。使用 AudioCrop (#38) 修剪它,仅保留您想要模仿的表现部分。这与音色参考分开,重点在于节奏、能量和语调。如果您跳过此步骤,IndexTTS2 ComfyUI 工作流程将仅依赖文本来进行韵律。
情感控制:使用情感参考音频#
此区域将您的情感提示连接到生成器。裁剪后的情感片段将输入到 IndexTTS2Run (#12) 的 emo_audio_prompt,指导节奏和强度,同时保留目标语音。您也可以使用节点的情感文本控制来微调风格,如果您没有情感音频示例。在实践中,情感音频往往提供更强、更一致的表现力,而情感文本提供较轻的引导。当您想要一个具体的例子和文字提示时,可以结合使用。
生成和导出#
IndexTTS2Run (#12) 使用您的文本、音色参考和任何情感指导合成语音。输出路由到 SaveAudio (#17) 以获得无损的 FLAC,并路由到 SaveAudioMP3 (#39) 以获得小型、网络友好的预览。使用保存节点上的文件名字段,在迭代中保持录音的组织性。此设计使得在保持相同说话者身份的情况下,轻松对比不同的文本或情感。
Comfyui IndexTTS2 ComfyUI 工作流程中的关键节点#
IndexTTS2Run (#12)#
这是核心生成器,包装了 IndexTTS‑2 并提供采样、束搜索和情感条件的控制。调整 top_p、top_k 和 temperature 以平衡稳定性和多样性——较低的值提供更一致的读取,较高的值增加自发性。当您希望节点搜索更多候选读取时,使用 num_beams,以速度换取质量。对于长脚本,max_mel_tokens 和 max_text_tokens_per_sentence 有助于通过限制音频和文本块大小来防止超限。情感可以通过 emo_audio_prompt、用于混合强度的 emo_alpha 或通过 use_emo_text 和 emo_text 在您更喜欢文字提示时进行引导。根据您的硬件,性能助手如 deepspeed、custom_cuda_kernel 和 unload_model 可用。节点实现由 ComfyUI IndexTTS 自定义节点提供:ComfyUI_IndexTTS,底层模型在此记录:IndexTTS‑2,IndexTTS 项目。
AudioCrop (#37) — 参考音色#
使用此节点从您的说话者样本中隔离一个干净、稳定的片段。避免背景噪音、笑声或极端情感,因为这些细节可能会泄露到克隆语音中。裁剪到一致的音调可以提高身份锁定并减少不必要的伪影。
AudioCrop (#38) — 情感提示#
此裁剪选择控制表达的提示。选择具有您想要的确切节奏或强度的部分,并保持简洁以避免稀释信号。为了最佳的一致性,尽可能使用与音色参考相同说话者的情感提示。
可选额外功能#
- 保持参考音频干净单声道;去除混响、背景音乐和重压缩以实现更清晰的克隆。
- 有意标点。逗号、句号和问号有助于模型放置与您的意图相匹配的停顿和重音。
- 为了可再现的录音,禁用节点中的随机性或记录文本和音频选择的笔记,以便您可以稍后重新生成相同的输出。
- 如果 VRAM 不足,在运行之间启用模型卸载;这可能会增加一些时间成本,但释放内存以供其他图表使用。
- 尊重语音权利。仅使用您被授权克隆的参考录音,并在需要时披露合成语音。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们感谢 RunningHub 提供的工作流程参考,RunComfy 提供的云保存工作流程,Index Team 提供的 IndexTTS 和 IndexTTS-2,IndexTTS2 论文的作者,以及 billwuhao 提供的 ComfyUI IndexTTS 自定义节点的贡献和维护。有关权威细节,请参阅下面链接的原始文档和存储库。
资源#
- RunningHub/Workflow Reference
- 文档 / 发布说明: RunningHub post
- RunComfy/Cloud Save Workflow
- 文档 / 发布说明: RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/Paper
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
注意:引用的模型、数据集和代码的使用受其作者和维护者提供的相应许可证和条款的约束。