
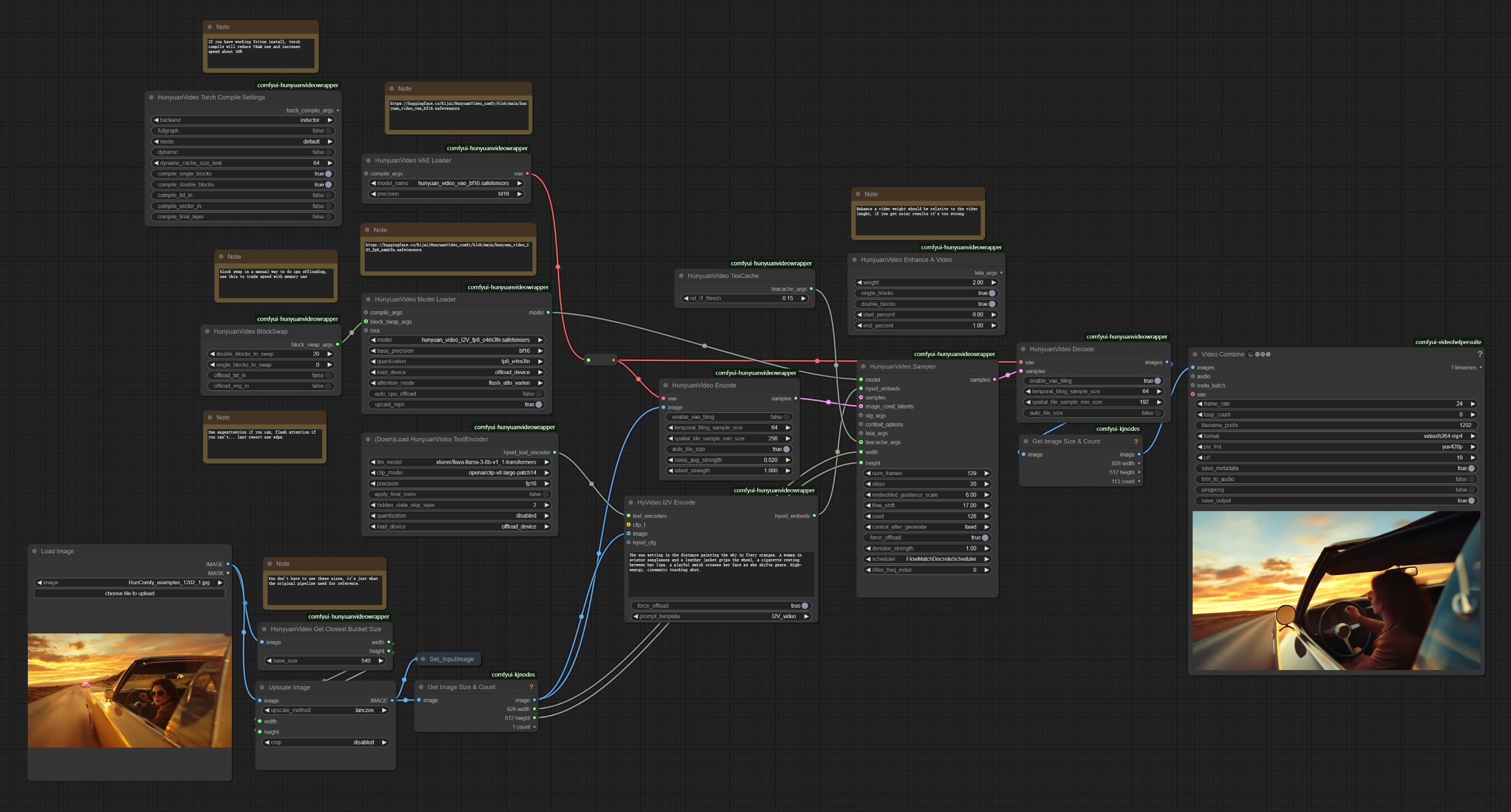
ComfyUI Hunyuan图像到视频工作流描述#
1. 什么是Hunyuan图像到视频工作流?#
Hunyuan图像到视频工作流是一个强大的管道,旨在将静态图像转换为具有自然运动的高质量视频。由腾讯开发,这项尖端技术使用户能够创建具有流畅24fps播放的电影动画,分辨率高达720p。通过利用潜在图像连接和多模态大语言模型,Hunyuan图像到视频解释图像内容,并根据文本提示应用一致的运动模式。
2. Hunyuan图像到视频的优势:#
- 高分辨率输出 - 生成高达720p的24fps视频
- 自然运动生成 - 从静态图像创建流畅逼真的动画
- 文本引导动画 - 使用文本提示引导运动和视觉效果
- 电影级质量 - 生成专业级高保真视频
- 可定制效果 - 支持LoRA训练的效果,如头发生长、面部表情和风格调整
- 优化内存使用 - 利用FP8权重更好地管理资源
3. 如何使用Hunyuan图像到视频工作流#
3.1 使用Hunyuan图像到视频的生成方法#
示例工作流:#
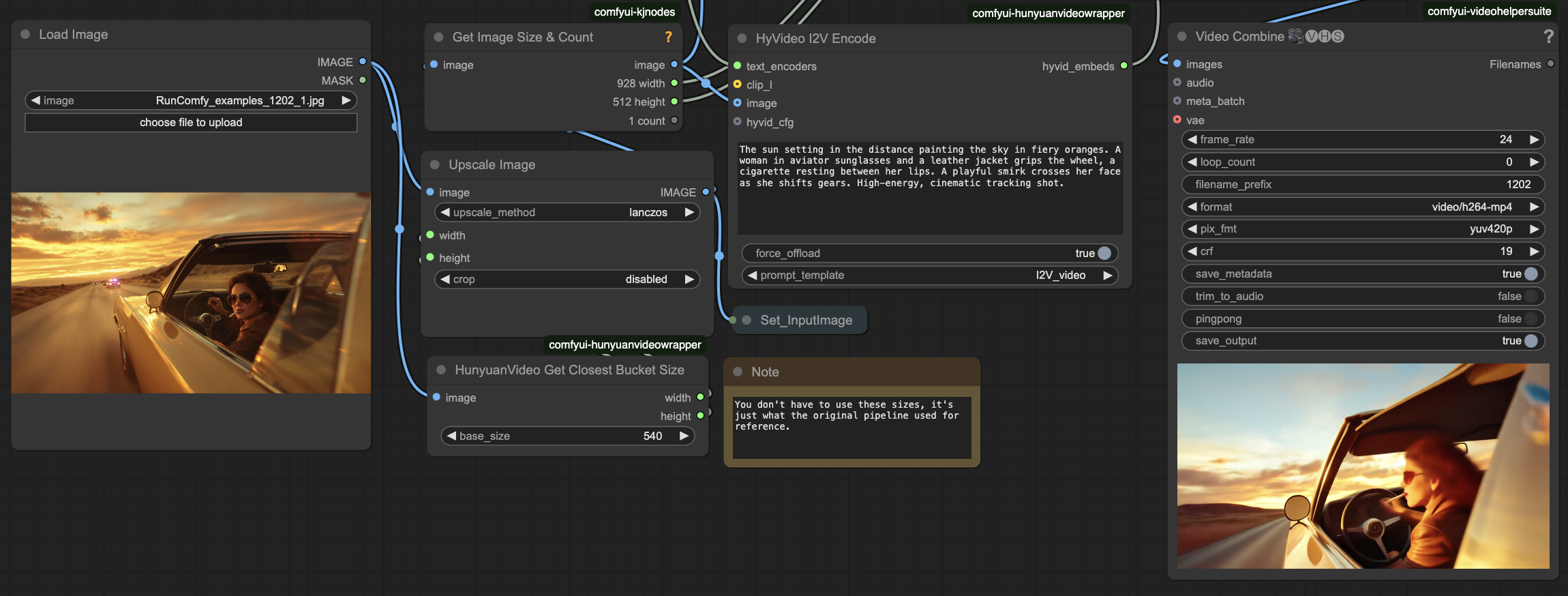
- 准备输入
- 在Load Image中:上传您的源图像
- 输入运动描述
- 在HyVideo I2V Encode中:输入所需运动的描述性文本提示
- 精细调整(可选)
- 在HunyuanVideo Sampler中:调整
frames以控制视频长度(默认:129帧≈5秒) - 在HunyuanVideo TeaCache中:修改
cache_factor以优化内存使用 - 在HunyuanVideo Enhance A Video中:启用以保持时间一致性并减少闪烁
- 在HunyuanVideo Sampler中:调整
- 输出
- 在Video Combine中:检查预览并在ComfyUI > Output文件夹中找到保存的结果
3.2 Hunyuan图像到视频的参数参考#
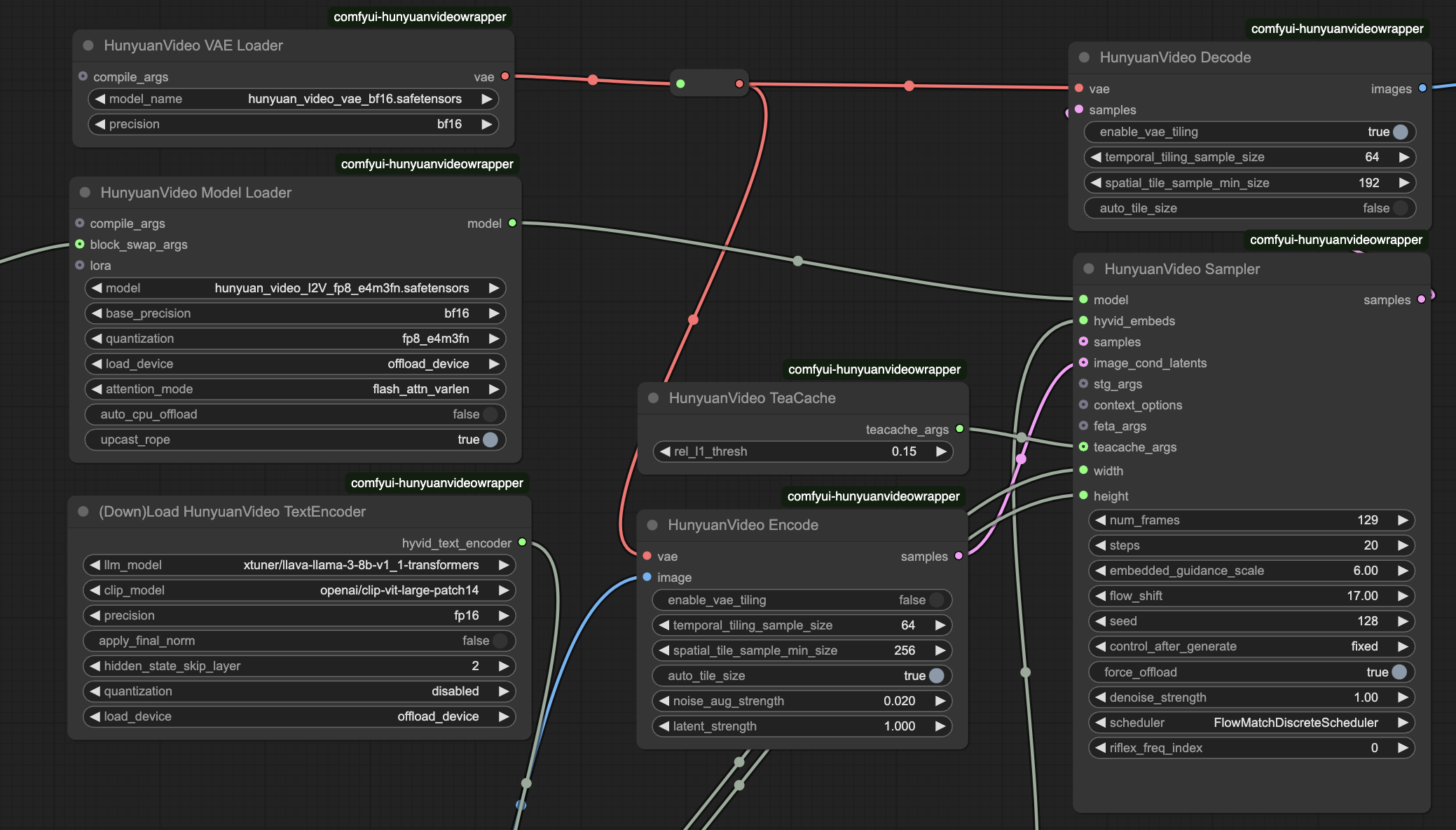
- HunyuanVideo模型加载器
model_name: hunyuan_video_I2V_fp8_e4m3fn.safetensors - 图像到视频转换的核心模型weight_precision: bf16 - 定义模型权重的精度级别scale_weights: fp8_e4m3fn - 优化内存使用attention_implementation: flash_attn_varlen - 控制注意力处理效率
- HunyuanVideo采样器
frames: 129 - 帧数(24fps下5.4秒)steps: 20 - 采样步骤(更高的值提高质量)cfg: 6 - 控制提示遵从强度seed: varies - 确保生成一致性
- HyVideo I2V编码
prompt: [text field] - 描述性提示用于运动和风格add_prepend: true - 启用自动文本格式化
3.3 Hunyuan图像到视频的高级优化#
- 内存优化
- HunyuanVideo BlockSwap:CPU卸载以提高VRAM效率
- HunyuanVideo TeaCache:控制缓存行为以平衡内存和速度
- scale_weights:FP8权重(
e4m3fn format)用于减少内存
- 速度优化
- HunyuanVideo Torch编译设置:启用Torch编译以加快处理速度
- attention_implementation:选择高效的注意力机制以提升性能
- offload_device:配置GPU/CPU内存管理
更多信息#
有关Hunyuan图像到视频工作流的更多详细信息,请访问Tencent's HunyuanVideo-I2V repository。
致谢#
此工作流由Hunyuan图像到视频提供支持,由腾讯开发。ComfyUI集成包括由Kijai创建的包装节点,启用高级功能,如上下文窗口和直接图像嵌入支持。所有的荣誉归属于原始创造者,他们在图像到视频生成方面的开创性工作!