
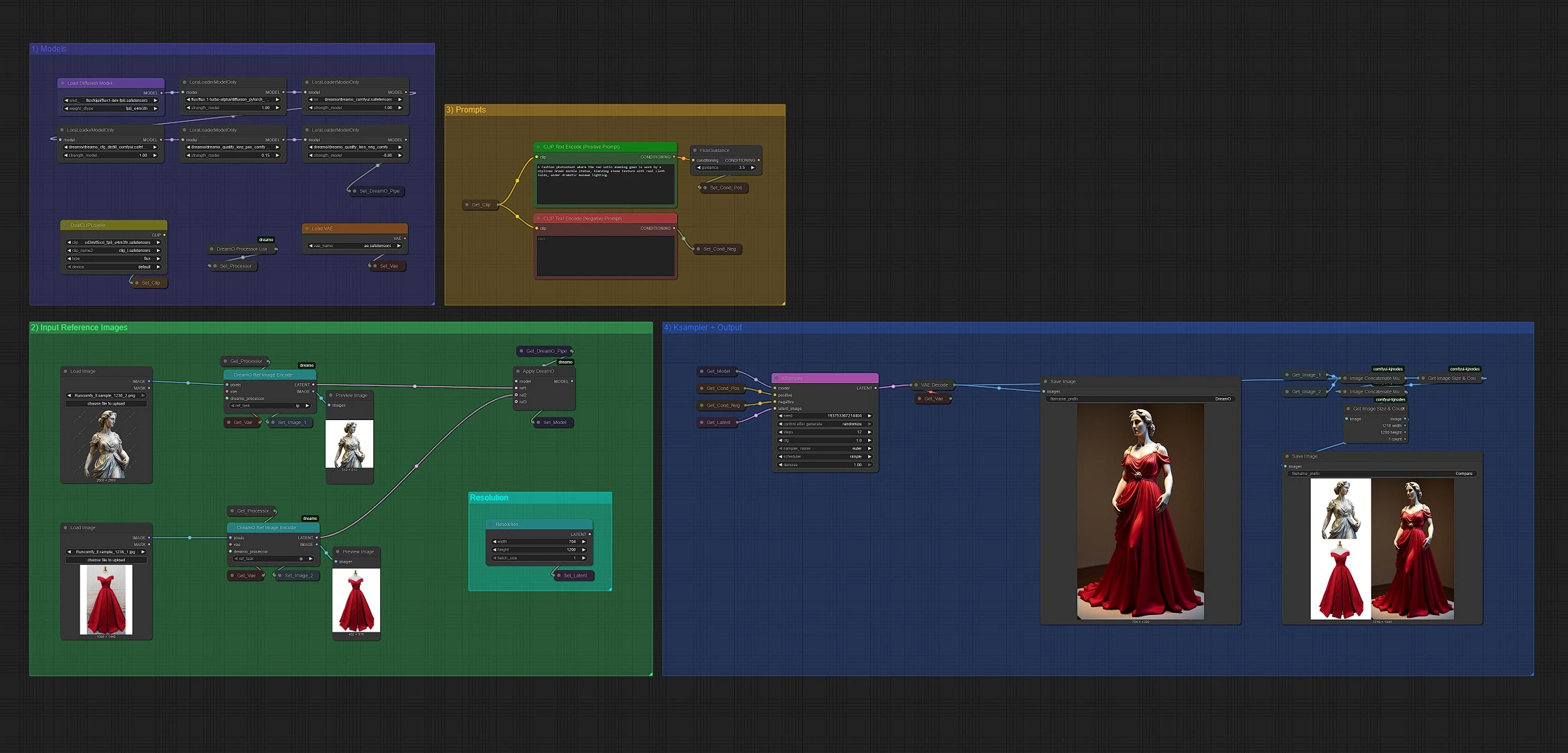









DreamO: 统一多任务图像定制框架#
DreamO 是一个强大的基于参考的图像生成工作流,支持多种视觉定制任务,包括身份保留、风格迁移、虚拟试穿和多条件混合。
基于统一的架构,DreamO 可以从一到三个输入参考中进行灵活的图像合成,由自然语言提示指导。无论您是在处理角色、服装、物品还是面部身份,DreamO 都能在跨任务的结构和风格一致性中提供高保真输出。
为什么使用 DreamO?#
DreamO 框架提供:
- 多任务支持: DreamO 支持 IP、ID、Try-On、Style 或 Multi-Condition 模式
- 1–3 个参考图像: DreamO 使用一到三个输入图像来指导生成
- 任务特定控制: DreamO 应用针对性的定制,如面部身份、服装或外观风格
- 文本 + 图像融合: DreamO 将视觉参考与提示驱动的创意相结合
- 创作者的完美选择: DreamO 是角色设计、虚拟试穿演示、产品原型设计等的理想选择
DreamO 为艺术家、开发者和设计师提供了一个全面的工具包用于控制图像合成——灵活、模块化且具有创意可扩展性。
DreamO 模型#
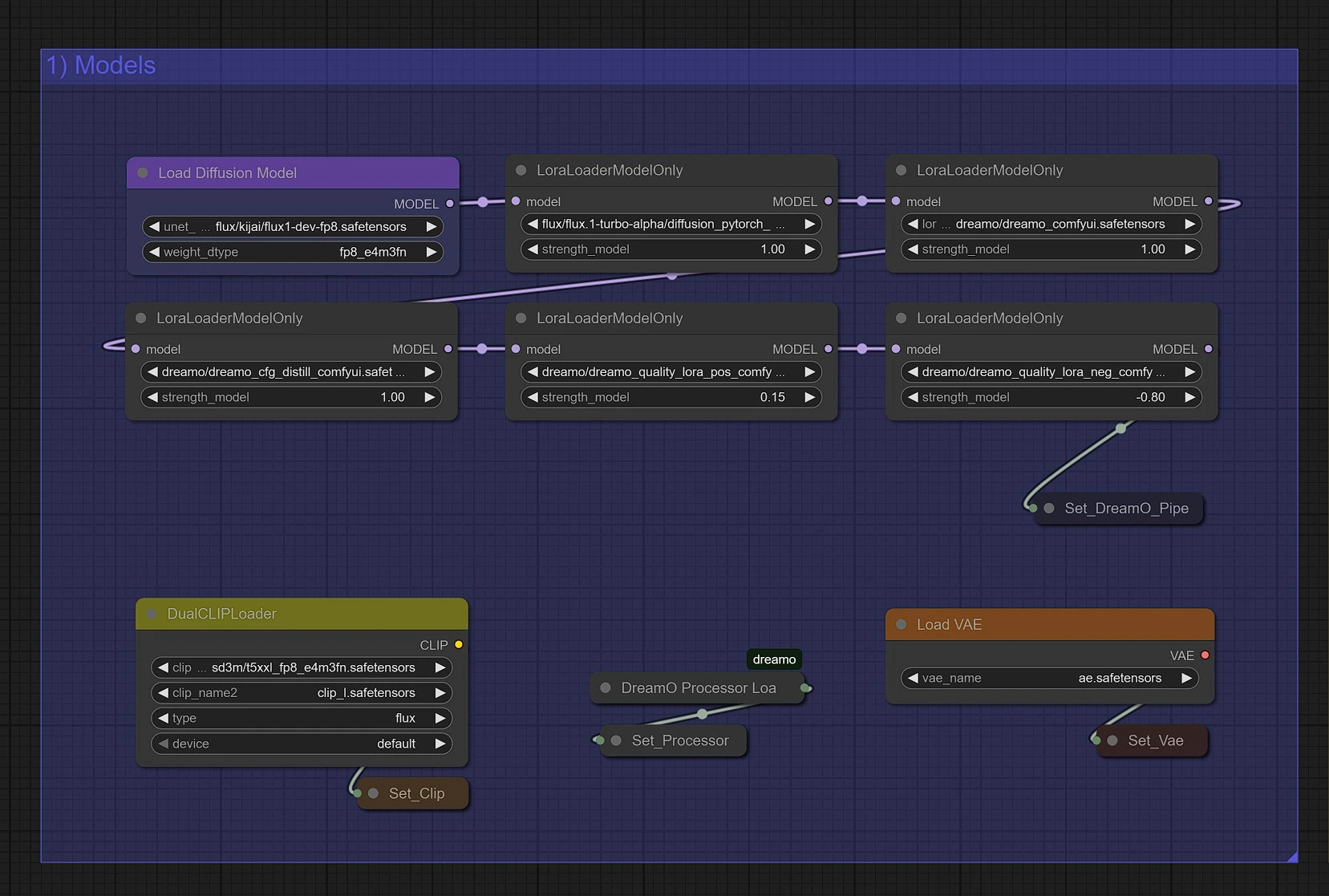
此组在您首次运行 DreamO 工作流时自动加载所有所需的 DreamO 模型。无需手动设置。 DreamO 模型托管于官方仓库: https://github.com/ToTheBeginning/ComfyUI-DreamO
DreamO 输入图像#
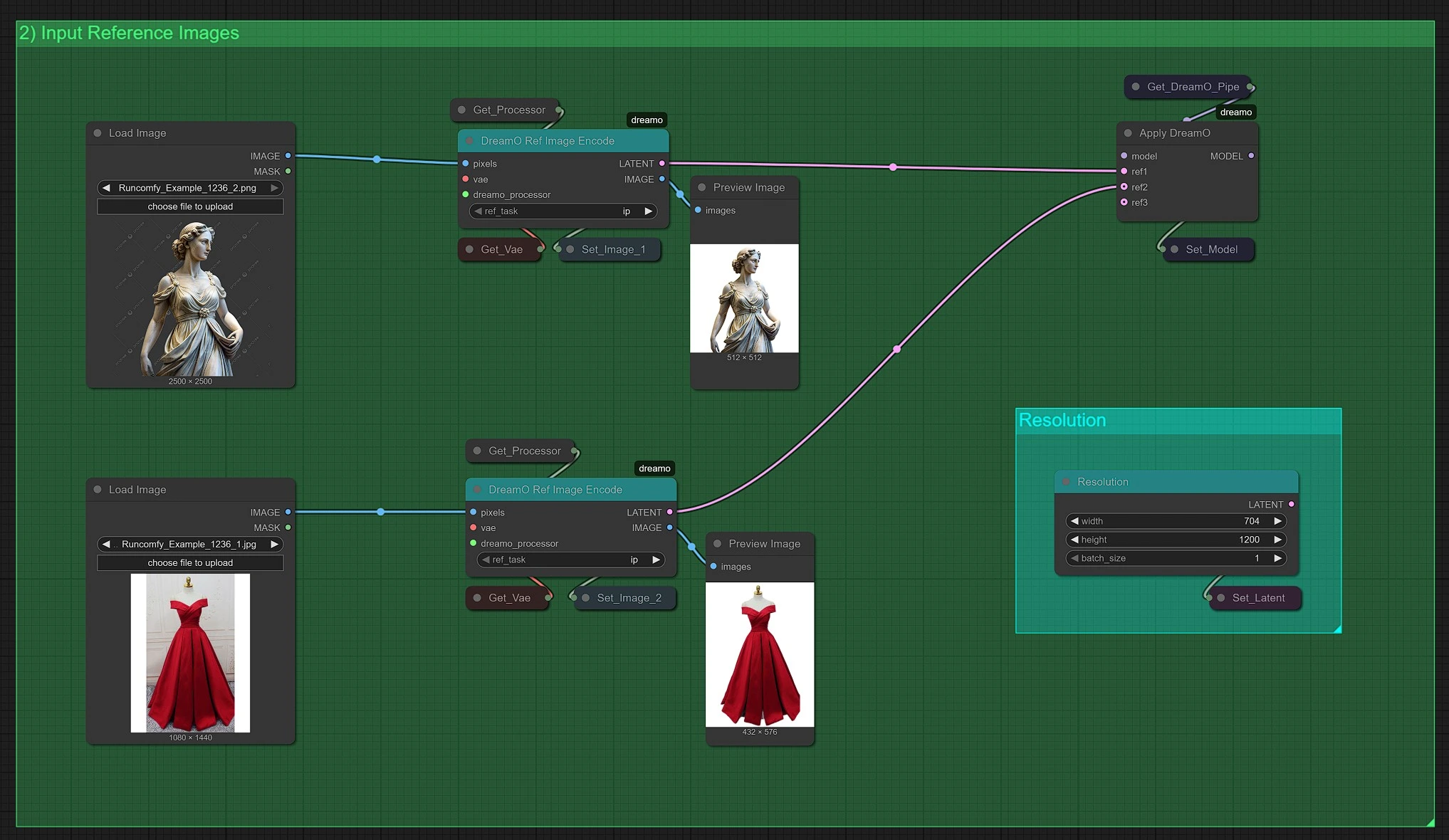
在此部分,您可以上传 1 到 3 张参考图像 并选择您希望 DreamO 执行的 任务:
- IP (身份 + 姿势)
- ID (仅面部身份)
- Style
您还可以设置 渲染分辨率 以定义 DreamO 输出图像的大小。根据您的期望质量或使用场景调整此设置。适当的图像分辨率可改善对齐并在 DreamO 输出中保留细节。
DreamO 提示#
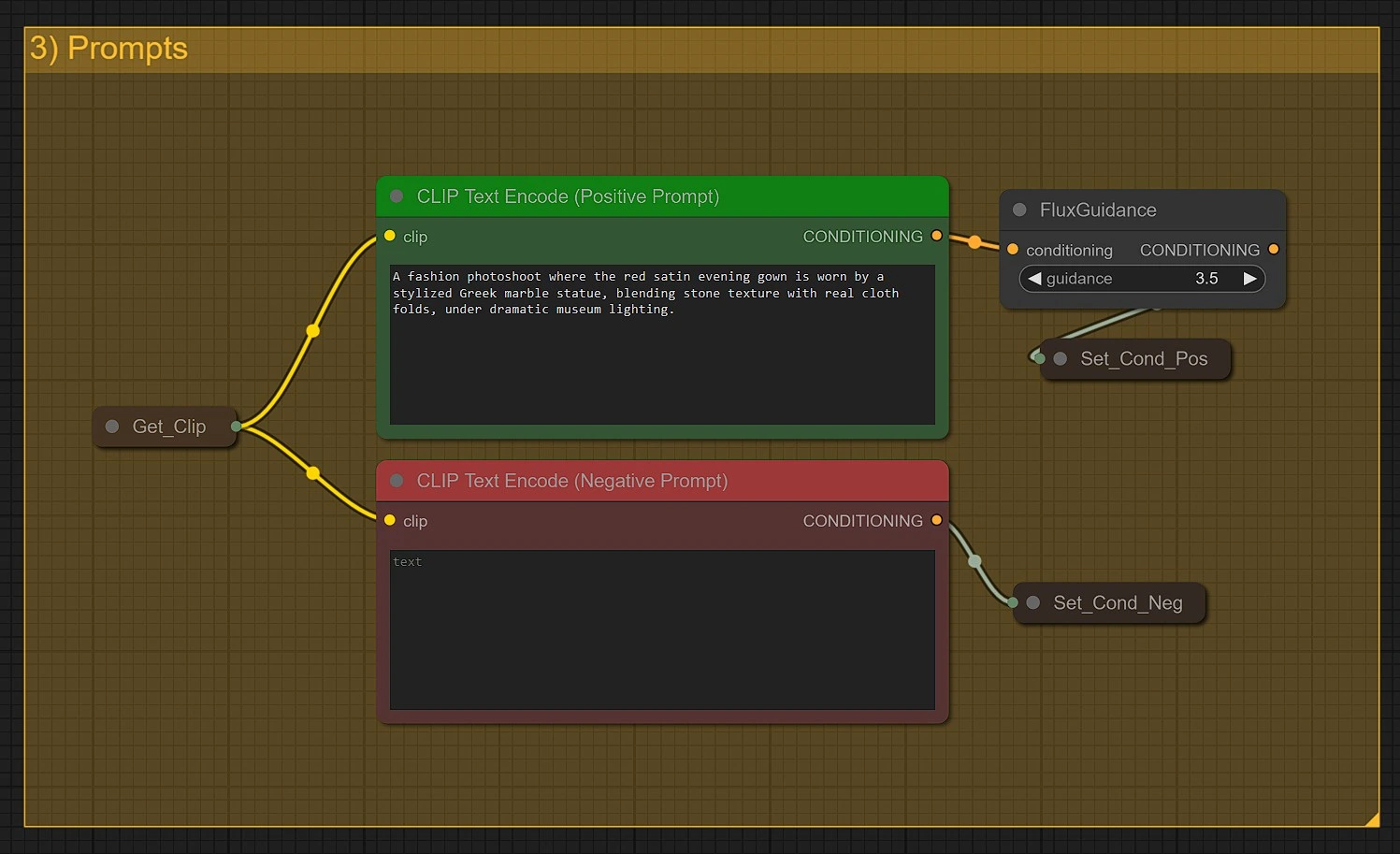
在此输入您的 主要文本提示 以控制 DreamO 输出图像的外观、背景或风格:
- 撰写详细、生动的提示来指导 DreamO 生成方向
- 您可以结合视觉参考和语言来塑造服装、配饰、情感或环境在 DreamO 中的呈现
- 使用 负面提示 以避免 DreamO 输出中的不想要特征或伪影
提示指导对于在所有 DreamO 任务中实现精细结果至关重要。
DreamO KSampler + 输出#
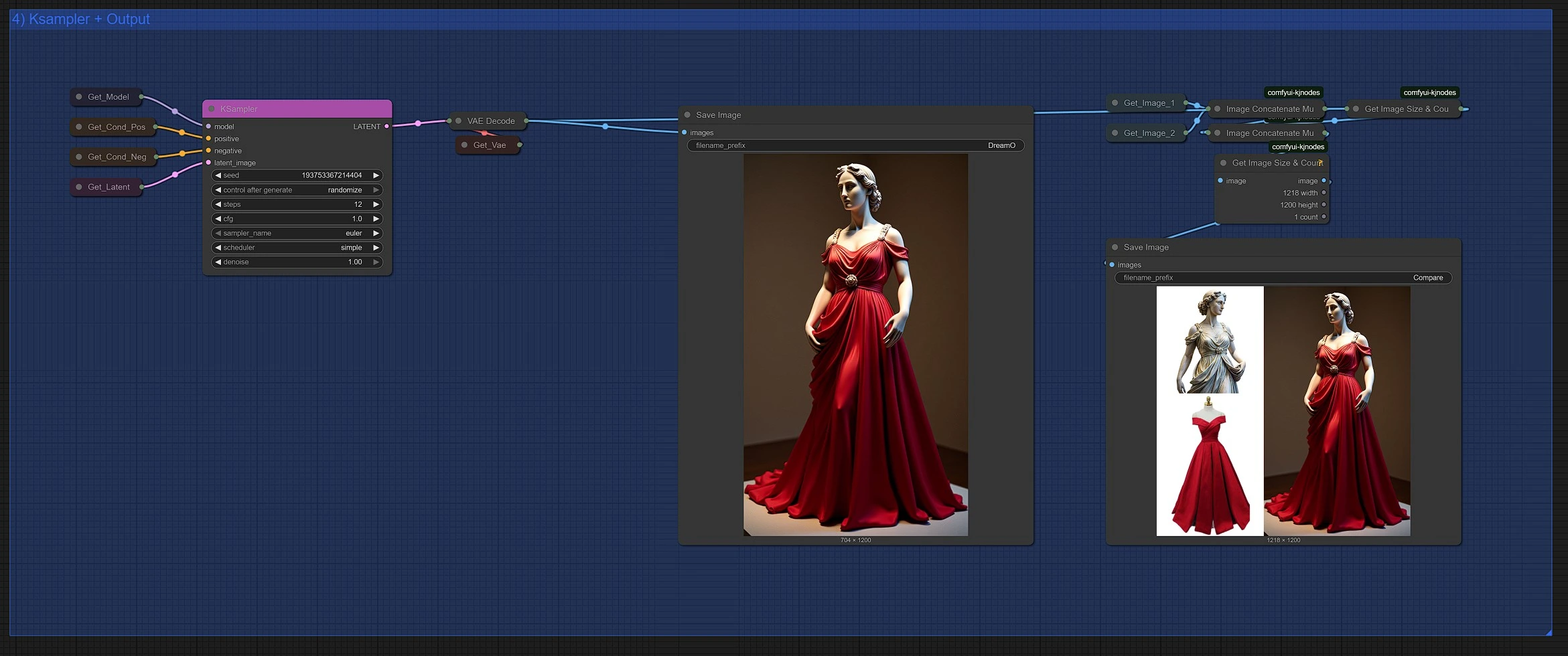
在此 DreamO 部分,您可以:
- 配置 采样参数 如步数、采样器类型 (Euler, DPM++) 和 DreamO 的指导规模
- 触发 DreamO 生成过程
- 查看并比较 DreamO 输出结果
所有 DreamO 生成的图像都会自动保存到您的 ComfyUI > output 文件夹中。
DreamO 呈现一个 并排比较,展示参考和提示如何影响最终结果——帮助您快速且富有创意地进行迭代与 DreamO。
致谢#
此工作流使用了由 ToTheBeginning 开发的 DreamO 模型。 所有荣誉归于他们,感谢他们构建了这个统一的多任务图像定制架构并在 ComfyUI 中实现了无缝的多输入工作流与 DreamO。 DreamO GitHub 仓库: https://github.com/ToTheBeginning/ComfyUI-DreamO
DreamO 汇集了多年关于身份、结构和风格保留的研究,涵盖了任务如 IP-Adapter、InstantID、InstantStyle 和 Try-On 生成。DreamO 是一个多功能且具备生产就绪的工具包,适合希望将基于参考的控制与深度模型保真度结合的创作者,所有这些都在 ComfyUI 中通过 DreamO 实现。


