

什么是PhotoMakerV2#
PhotoMakerV2是PhotoMaker的升级版,提供了一种高效的个性化文本到图像生成方法。它使用少量输入身份图像和文本提示合成逼真的个人照片。
PhotoMakerV2的一些主要特点包括:#
- 高效:快速生成个性化照片。
- 优秀的身份保留:保持输入身份的相貌。
- 灵活的文本控制:允许在提示中指定背景、风格、属性等。
- 改进的身份保真度:相比PhotoMaker V1有所增强。
PhotoMakerV2在各种背景下生成逼真的个人图像,风格化外观,改变年龄和性别等属性,合并身份,并将旧照片或艺术作品中的人物现代化。它解锁了无数的创意可能性。
PhotoMakerV2的工作原理#
PhotoMakerV2将一个或多个输入身份图像编码为"堆叠ID嵌入",作为封装身份信息的统一表示。
这个嵌入与文本提示结合,输入到文本到图像扩散模型中。然后模型生成一张图像,展示嵌入身份在提示描述的背景下。
其工作原理的一些关键方面:
- 使用身份编码器从输入的面部图像中提取身份信息
- 通过利用外部面部识别模型(InsightFace)改进身份保留
- 将多个身份图像编码为堆叠嵌入,以全面捕捉身份
- 将堆叠ID嵌入输入到扩散模型的交叉注意力层中
- 在文本提示的指导下,自适应地合并身份信息
- 使用面向身份的数据集进行训练,以提高识别能力
如何使用ComfyUI PhotoMakerV2#
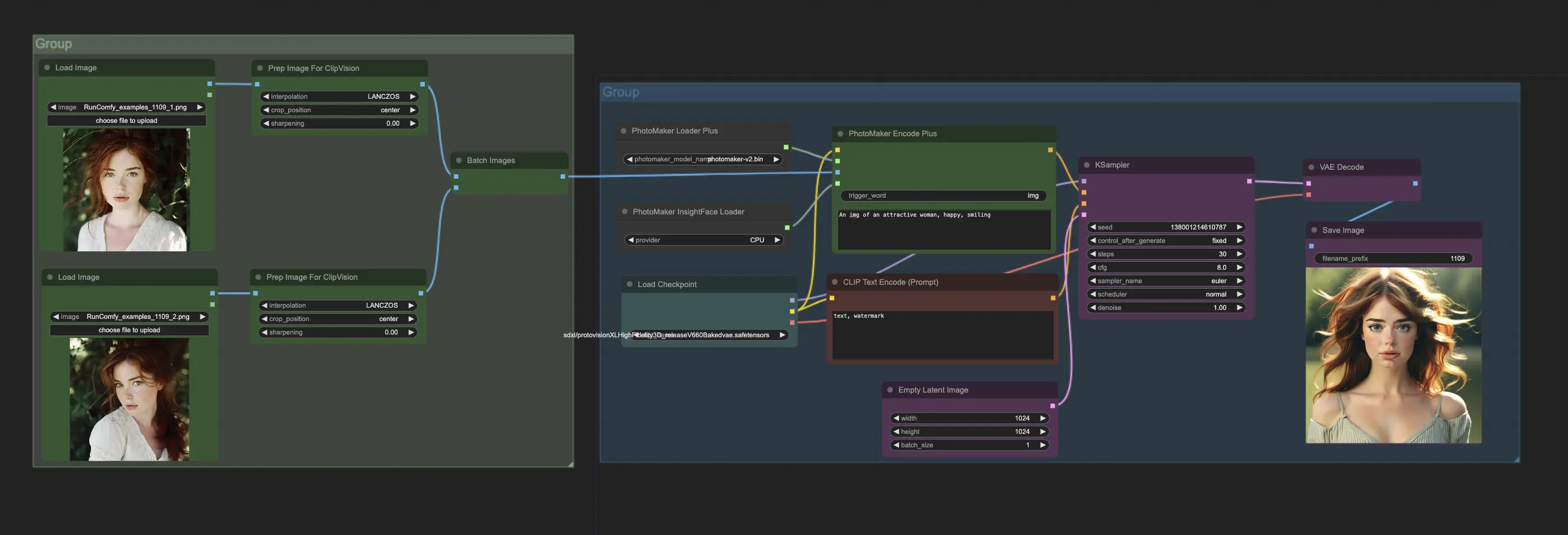
要在ComfyUI中使用PhotoMakerV2,主要与PhotoMakerEncodePlus节点交互。典型的工作流程包括:
- 使用"PhotoMaker Loader Plus"节点加载PhotoMakerV2模型。
- 使用"Prepare Images For CLIP Vision"节点加载一个或多个身份图像。
- 使用"PhotoMaker InsightFace Loader"节点加载PhotoMakerV2所需的InsightFace模型。
- 将这些节点的输出连接到"PhotoMaker Encode Plus"节点的对应输入。
- 在"PhotoMaker Encode Plus"节点中指定描述所需图像的提示。使用提示中特殊的触发词指示身份出现的位置。
- 将"PhotoMaker Encode Plus"的输出条件连接到"KSampler"节点以生成图像。
更多信息,请访问PhotoMaker Hugging Face和ComfyUI-PhotoMaker-Plus。所有功劳归于他们的贡献。