
InfiniteTalk:从单张图像在 ComfyUI 中生成同步口型的肖像视频#
这个 ComfyUI InfiniteTalk 工作流程可以从单个参考图像加上音频片段创建自然的、语音同步的肖像视频。它结合了 WanVideo 2.1 图像到视频生成与 MultiTalk 讲话头模型,以产生富有表现力的口型动作和稳定的身份。如果您需要短社交片段、视频配音或头像更新,InfiniteTalk 可以在几分钟内将静止照片变为流畅的讲话视频。
InfiniteTalk 构建在 MeiGen-AI 的优秀 MultiTalk 研究基础上。有关背景和归属,请参见开源项目:MeiGen-AI/MultiTalk。
Comfyui InfiniteTalk 工作流程中的关键模型#
- MultiTalk (GGUF, InfiniteTalk 变体):从音频驱动音素感知的面部动作,使嘴巴和下巴的动作自然地跟随语音。参考:Kijai/WanVideo_comfy_GGUF › InfiniteTalk 和上游创意:MeiGen-AI/MultiTalk。
- WanVideo 2.1 I2V 14B (GGUF):主要的图像到视频生成器,在动画帧时保留身份、光照和姿势。推荐权重:city96/Wan2.1-I2V-14B-480P-gguf。
- Wan 2.1 VAE (bf16):将潜在帧解码为 RGB,颜色偏移最小;提供在上述 WanVideo 包中。
- UMT5-XXL 文本编码器:解释您的正面和负面提示,以推动风格、场景和动作上下文。模型家族:google/umt5-xxl。
- CLIP Vision:从您的参考图像中提取视觉嵌入,以锁定身份和整体外观。
- Wav2Vec2 (Tencent GameMate):将原始语音转换为 MultiTalk 嵌入的强大音频特征,提高同步和韵律:TencentGameMate/chinese-wav2vec2-base。
提示:此 InfiniteTalk 图是为 GGUF 构建的。保持 InfiniteTalk MultiTalk 权重和 WanVideo 主干在 GGUF 中以避免不兼容。也可用可选的 fp8/fp16 构建:Kijai/WanVideo_comfy_fp8_scaled 和 Kijai/WanVideo_comfy。
如何使用 Comfyui InfiniteTalk 工作流程#
工作流程从左到右运行。您需要提供三样东西:一张干净的肖像图片、一段语音音频文件和一个简短的提示来引导风格。然后图形提取文本、图像和音频线索,将它们融合成动作感知的视频潜在元素,并渲染同步的 MP4。
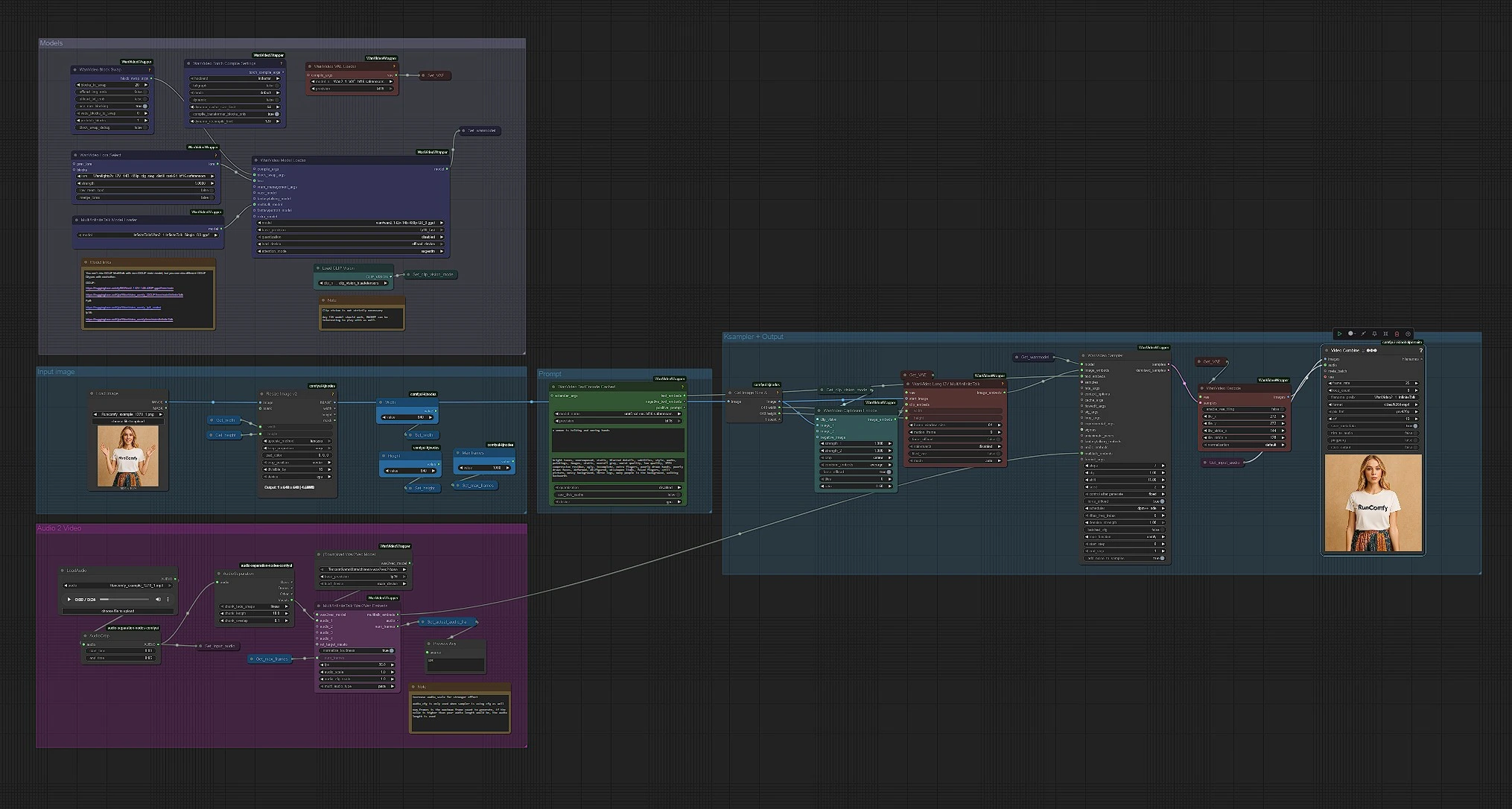
模型#
这一组加载 WanVideo、VAE、MultiTalk、CLIP Vision 和文本编码器。WanVideoModelLoader (#122) 选择 Wan 2.1 I2V 14B GGUF 主干,而 WanVideoVAELoader (#129) 准备匹配的 VAE。MultiTalkModelLoader (#120) 加载驱动语音动作的 InfiniteTalk 变体。您可以选择附加一个 Wan LoRA 在 WanVideoLoraSelect (#13) 中以偏向外观和动作。首次运行时保持这些不变;它们预先设置为对大多数 GPU 友好的 480p 管道。
提示#
WanVideoTextEncodeCached (#241) 使用 UMT5 编码您的正面和负面提示。使用正面提示描述主题和场景基调,而不是身份;身份来自参考照片。将负面提示集中在您想要避免的伪影上(模糊、额外的肢体、灰色背景)。InfiniteTalk 中的提示主要塑造光照和运动能量,而面部保持一致。
输入图像#
CLIPVisionLoader (#238) 和 WanVideoClipVisionEncode (#237) 嵌入您的肖像。使用清晰、正面的头肩照片,光线均匀。如果需要,轻轻裁剪以便脸部有足够的活动空间;重度裁剪可能会导致动作不稳定。图像嵌入被传递以在视频动画中保留身份和服装细节。
从音频到 MultiTalk#
在 LoadAudio (#125) 中加载您的语音;使用 AudioCrop (#159) 剪裁以进行快速预览。DownloadAndLoadWav2VecModel (#137) 获取 Wav2Vec2,而 MultiTalkWav2VecEmbeds (#194) 将剪辑转化为音素感知的运动特征。短的 4–8 秒剪辑非常适合迭代;一旦您喜欢外观,可以运行更长的拍摄。干净、干燥的语音轨道效果最佳;强烈的背景音乐可能会干扰口型时序。
图像到视频、采样和输出#
WanVideoImageToVideoMultiTalk (#192) 将您的图像、CLIP Vision 嵌入和 MultiTalk 融合到由 Width 和 Height 常量确定的帧图像嵌入中。WanVideoSampler (#128) 使用 Get_wanmodel 和您的文本嵌入生成潜在帧,采用 WanVideo 模型。WanVideoDecode (#130) 将潜在元素转换为 RGB 帧。最后,VHS_VideoCombine (#131) 将帧和音频混合为 MP4,以 25 fps 的平衡质量设置生成最终的 InfiniteTalk 剪辑。
Comfyui InfiniteTalk 工作流程中的关键节点#
WanVideoImageToVideoMultiTalk (#192)#
这个节点是 InfiniteTalk 的核心:它通过将起始图像、CLIP Vision 特征和 MultiTalk 指导合并在目标分辨率下调节讲话头动画。调整 width 和 height 来设置纵横比;832×480 是速度和稳定性的良好默认值。将其用作在采样前对齐身份与动作的主要场所。
MultiTalkWav2VecEmbeds (#194)#
将 Wav2Vec2 特征转换为 MultiTalk 动作嵌入。如果口型动作太微妙,在此阶段提高其影响力(音频缩放);如果过于夸张,降低影响力。确保音频以语音为主,以便可靠的音素时序。
WanVideoSampler (#128)#
根据图像、文本和 MultiTalk 嵌入生成视频潜在元素。首次运行时保持默认调度器和步骤。如果看到闪烁,增加总步骤数或启用 CFG 可以帮助;如果动作感觉过于僵硬,减少 CFG 或采样器强度。
WanVideoTextEncodeCached (#241)#
使用 UMT5-XXL 编码正面和负面提示。使用简洁、具体的语言,如“工作室光、柔和的皮肤、自然色彩”,保持负面提示集中。请记住,提示精炼框架和风格,而口型同步来自 MultiTalk。
可选额外功能#
- 将 MultiTalk 和 WanVideo 保持在同一部署家族(全部 GGUF 或全部非 GGUF)以避免不兼容。
- 使用 5–8 秒的音频剪辑和默认的 480p 大小进行迭代;如有需要,稍后再进行放大。
- 如果身份不稳,尝试更干净的源照片或更温和的 LoRA。强烈的 LoRA 可能会覆盖相似性。
- 在安静的房间中录制语音并规范化音量;InfiniteTalk 在清晰、干燥的声音下最佳跟踪音素。
致谢#
InfiniteTalk 工作流程通过将 ComfyUI 的灵活节点系统与 MultiTalk AI 模型结合,实现了 AI 驱动的视频生成的重大飞跃。此实现得益于 MeiGen-AI 的原创研究和发布,其 MultiTalk 项目为 InfiniteTalk 的自然语音同步提供了动力。特别感谢 InfiniteTalk 项目团队提供来源参考,以及 ComfyUI 开发者社区,使得工作流程的无缝集成成为可能。
此外,感谢 Kijai,他将 InfiniteTalk 实现到 Wan Video Sampler 节点,使创作者更容易在 ComfyUI 内直接制作高质量的讲话和歌唱肖像。InfiniteTalk 的原始资源链接可在此处获得:InfiniteTalk 示例工作流程。
这些贡献共同使创作者能够将简单的肖像转化为栩栩如生的连续讲话头像,释放 AI 驱动的讲故事、配音和表演内容的新机会。