
ChatterBox TTS ComfyUI:多模式 TTS、语音转换、多语言和对话合成于一体#
ChatterBox TTS ComfyUI 是一个紧凑、用户友好的音频工作流程,让您可以从单一画布生成多种模式的语音:标准 TTS、用于快速草稿的 Turbo TTS、多语言旁白、参考导向的语音克隆、语音转换和脚本化的双人对话。它由 ComfyUI_Fill-ChatterBox 提供的 FL ChatterBox 节点套件提供支持,该套件集成了开源的 Resemble AI Chatterbox 项目。
使用此工作流程来原型化 AI 语音,将台词本地化为其他语言,将一个演出转换为另一种语音,或规划角色交流。布局保持每条路径独立,因此您可以并排试听结果,并快速决定哪个 ChatterBox TTS ComfyUI 模式适合您的任务。
Comfyui ChatterBox TTS ComfyUI 工作流程中的关键模型#
- Resemble AI Chatterbox TTS 模型。核心神经 TTS 可将脚本转化为自然语音,并可选择性地使用参考音频来引导语音和风格。Resemble AI Chatterbox
- Resemble AI Chatterbox Turbo TTS。一个低延迟 TTS 变体,在需要快速录制和迭代提示时优化速度。Resemble AI Chatterbox
- Resemble AI Chatterbox 多语言 TTS。模型可以在多种语言中呈现文本,同时保留选定的风格或参考语音。Resemble AI Chatterbox
- Resemble AI Chatterbox 语音转换。将一个录音的音色转换为目标语音,同时保持时间和内容。Resemble AI Chatterbox
如何使用 Comfyui ChatterBox TTS ComfyUI 工作流程#
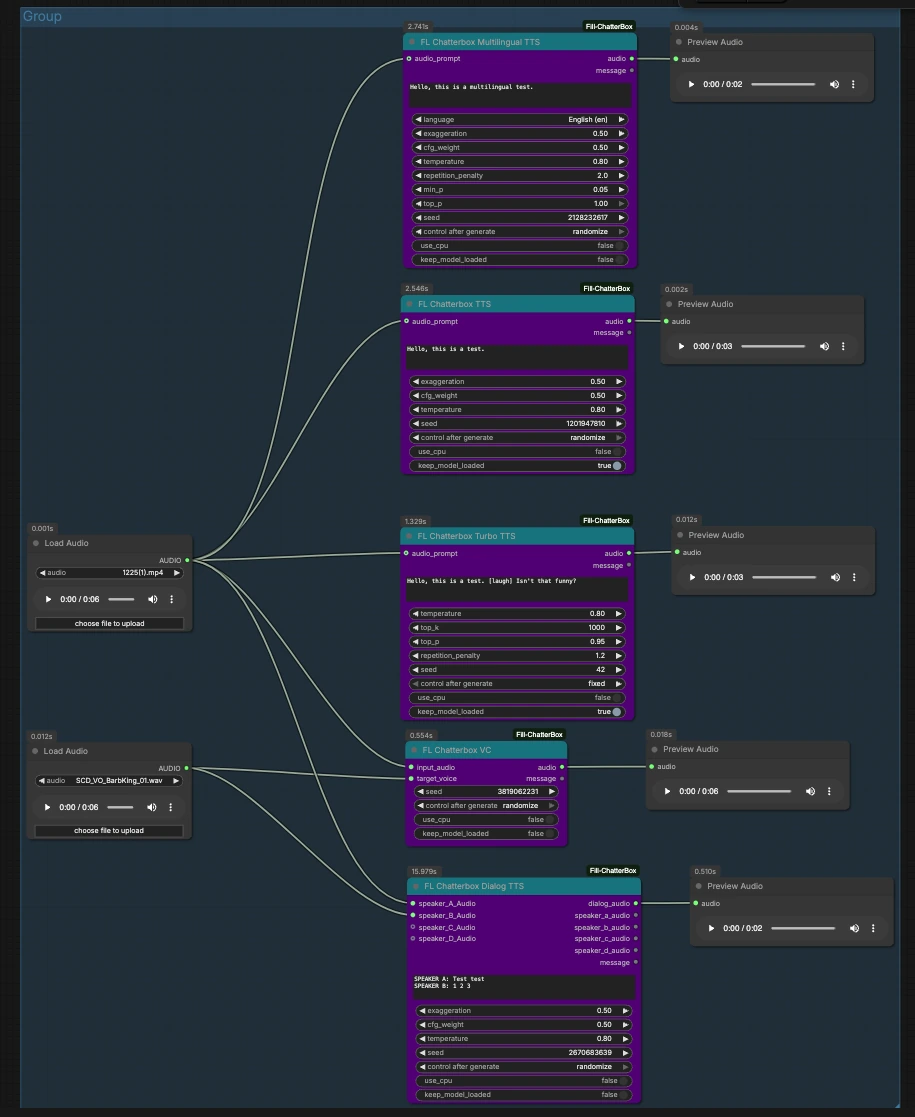
此图形被组织为从共享音频输入开始并流入 ChatterBox 节点的并行路径,每个节点预览其自己的结果。加载或替换两个输入剪辑,然后触发您想要的路径。
输入:参考和源音频#
两个 LoadAudio 节点提供可重复使用的输入。LoadAudio (#12) 作为风格或源参考馈送多个路径。LoadAudio (#20) 作为备用参考或目标语音。您可以将这些指向代表您想要模仿的说话风格或身份的短、干净的剪辑。两者都接受常见的音频文件,也可以从视频中提取音频。
带有可选风格参考的标准 TTS#
FL_ChatterboxTTS (#16) 从您的脚本生成语音,并可以选择从 LoadAudio (#12) 获取 audio_prompt 来捕捉语音和表达。输入您的文本,如果您想要语音相似性,则连接合适的参考,并排队节点。使用附加的 PreviewAudio 进行试听。在需要可重复的录制时固定种子,或随机化以探索变体。
用于快速迭代的 Turbo TTS#
FL_ChatterboxTurboTTS (#15) 专注于快速合成,以快速草稿和交互式编辑。它接受来自 LoadAudio (#20) 的 audio_prompt,如果您想微调语调或身份。快速移动时保持脚本简洁,并使用如例子中的“[laugh]”之类的标记来测试非语言提示。预览输出,然后切换到标准或多语言 TTS,如果您想要更丰富的表达。
多语言旁白#
FL_ChatterboxMultilingualTTS (#25) 以选定的语言呈现您的脚本,并可以从 LoadAudio (#12) 上的 audio_prompt 借用风格。选择语言标签(例如,图中显示的英语 (en)),并以该语言提供文本。简短的参考剪辑有助于在多语言之间保持一致的口音或角色。使用 PreviewAudio 聆听并在短语上进行迭代以提高清晰度。
语音转换#
FL_ChatterboxVC (#19) 将 LoadAudio (#12) 的 input_audio 线的音色转换为 LoadAudio (#20) 的 target_voice。当您已经有一个时间完美的读音并只想让它由另一个语音说出时,这是理想的。修剪静音并保持目标语音干净以减少伪影。使用预览确认内容在身份更改时得到保留。
双人对话合成#
FL_ChatterboxDialogTTS (#23) 将多行脚本转换为单个 dialog_audio 轨道。提供可选的 speaker_A_Audio 和 speaker_B_Audio 来自两个 LoadAudio 节点,以锚定每个角色的声音。在脚本框中,使用像“SPEAKER A:”和“SPEAKER B:”这样的标签为每个角色分配台词,如图中所示。您可以通过将参考剪辑添加到他们的输入中来扩展到说话者 C 和 D。
预览和比较#
每条路径都展开到自己的 PreviewAudio,因此您可以立即收听并比较模式。在同一 ChatterBox TTS ComfyUI 会话中同时运行一条路径或排队几个,以试听标准、Turbo、多语言、转换和对话输出之间的差异。
Comfyui ChatterBox TTS ComfyUI 工作流程中的关键节点#
FL_ChatterboxTTS (#16)#
通用 TTS,接受脚本和可选的 audio_prompt 参考来模仿风格。当质量和可控性最重要时使用它。在拍摄之间保持相同的参考剪辑以保持一致的身份,并在需要精确再现性时锁定种子。
FL_ChatterboxTurboTTS (#15)#
用于起草台词、迭代提示或预览标记想法的快速 TTS。它也接受 audio_prompt 以引导语音。如果您注意到与标准路径相比更薄的韵律,请使用相同的脚本和参考最终使用 FL_ChatterboxTTS。
FL_ChatterboxMultilingualTTS (#25)#
语言感知 TTS,在切换语言时保留选定的角色。选择语言标签并以该语言提供文本。匹配的 audio_prompt 保持口音和能量与您的参考语音一致。
FL_ChatterboxVC (#19)#
语音转换,将 input_audio 表演映射到 target_voice。使用干净、具有代表性的目标剪辑和节奏良好的源读取。为获得最佳效果,修剪长时间的静音,并避免在任一剪辑中出现严重的背景噪音。
FL_ChatterboxDialogTTS (#23)#
多说话者 TTS,将标记的台词解析为单个对话。为您计划使用的每个角色输入分配参考,然后使用清晰的“SPEAKER X:”标签构建脚本。保持轮次合理简短,以便于后续自然节奏和时间编辑。
可选附加功能#
- 保持参考剪辑简短、干净且富有表现力;房间音和噪音降低语音保真度。
- 当您需要在修订中匹配时间和表达时使用固定种子;随机化以探索替代方案。
- 如果某条路径听起来太响或被剪切,合成前请规范化您的参考并降低输入增益。
- Turbo 非常适合提示探索;使用标准或多语言 TTS 重新运行有前途的台词以进行最后的润色。
- 如果您在每行放置一个发声并一致地标记说话者,维护对话脚本会更容易。
- 如果您想直接从画布导出文件,请在任何预览后添加一个
SaveAudio节点。
ChatterBox TTS ComfyUI 为您提供了一个灵活的单一图形游乐场,可以在不切换上下文的情况下尝试语音、语言和对话,所有这些都由 ComfyUI_Fill-ChatterBox 和 Resemble AI Chatterbox 提供支持。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们对 filliptm 提供的 ComfyUI_Fill-ChatterBox 和 Resemble AI 提供的 Chatterbox 的贡献和维护表示感谢。有关权威细节,请参考下面链接的原始文档和存储库。
资源#
- filliptm/ComfyUI_Fill-ChatterBox
- GitHub: filliptm/ComfyUI_Fill-ChatterBox
- resemble-ai/chatterbox
- GitHub: resemble-ai/chatterbox
注意:引用的模型、数据集和代码的使用受其作者和维护者提供的各自许可和条款的约束。
