
ACE-Step 1.5XL 基础文本到音乐:ComfyUI 的提示到歌曲工作流#
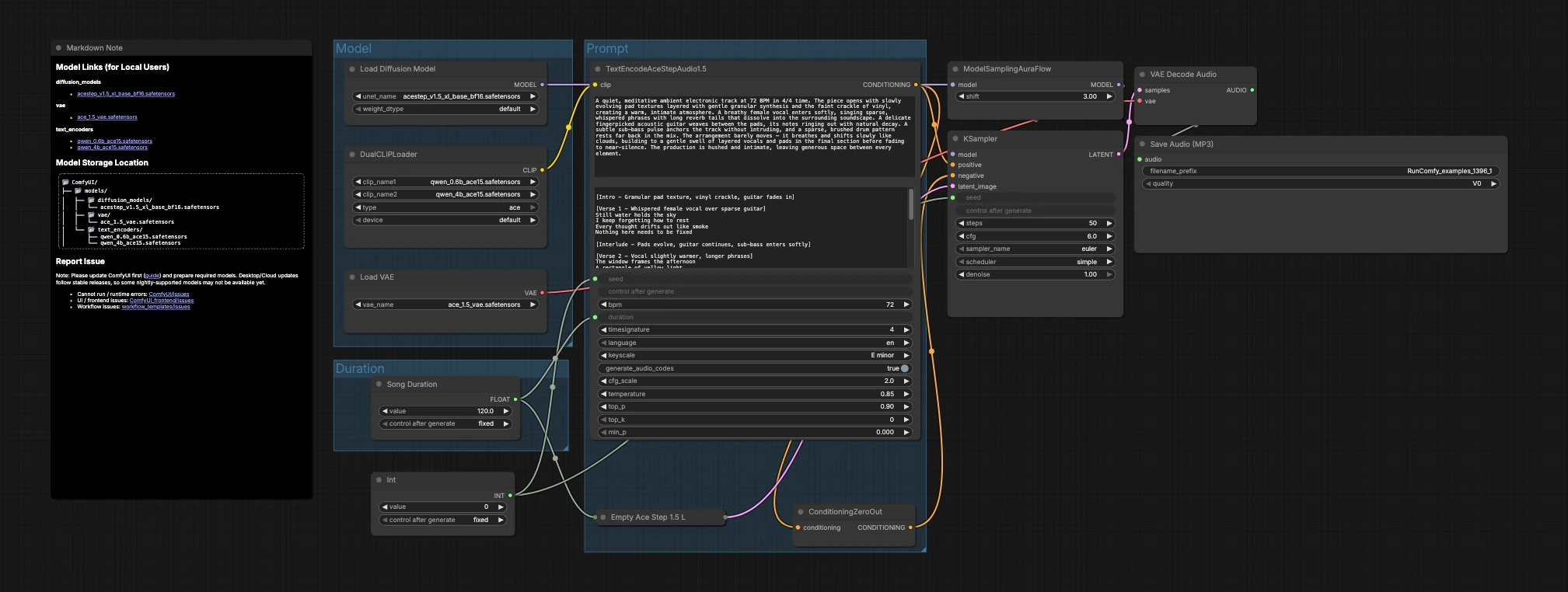
此工作流使用 ACE-Step 1.5XL 基础扩散系列将自然语言描述转化为成品音频。它将基础模型与其 ACE Step VAE 和双 Qwen 文本编码器配对,以确保结果完全在音乐领域,而非 TTS 或语音。如果您想要具有可预测结构、节奏和乐器的提示驱动 AI 音乐,这个 ACE-Step 1.5XL 基础文本到音乐管道是一个专注的最小设置,可以快速从想法到 MP3。
专为制作人、声音设计师和创作者设计,图表强调清晰性:选择模型、设置时长、编写音乐提示,然后生成并保存。ACE-Step 1.5XL 基础文本到音乐工作流足够紧凑以实现快速迭代,同时在详细的编曲、键和节奏上保持表现力。
Comfyui ACE-Step 1.5XL 基础文本到音乐工作流中的关键模型#
- ACE-Step 1.5 XL Base (bf16) 扩散模型。生成性的骨干,将音频潜在变量去噪成连贯的音乐短语和纹理。模型文件
- ACE Step 1.5 VAE。配对的变分自编码器,在潜在空间和波形域之间进行编码/解码,保持音色和混音平衡。模型文件
- Qwen 4B ACE15 文本编码器。为 ACE 适配的大型文本编码器,从提示中捕捉丰富的音乐语义、结构和编曲线索。模型文件
- Qwen 0.6B ACE15 文本编码器。一个更轻量的 ACE 适配编码器,优先考虑速度和资源效率,同时保持强大的提示理解能力。模型文件
如何使用 Comfyui ACE-Step 1.5XL 基础文本到音乐工作流#
图表分为三个组,流入生成和导出:模型、时长和提示。您加载模型,选择目标长度,描述音乐,然后采样器创建潜在变量,VAE 解码为音频。
模型#
此组加载核心资产。UNETLoader (#104) 选择 ACE-Step 1.5 XL Base 扩散检查点,VAELoader (#106) 加载匹配的 ACE Step 1.5 VAE,以便解码质量与训练一致。DualCLIPLoader (#105) 引入两个 Qwen ACE15 编码器;工作流联合使用它们,因此丰富的文本提示转化为强大的音乐条件。
时长#
这里决定作品的长度。Song Duration (#99) 设置目标长度(秒),并向前传递,以便潜在画布和文本条件一致。PrimitiveInt (#109) 提供种子,让您锁定精确结果以实现可重复性,或进行变更以探索替代演绎。
提示#
这是语言变成音乐的地方。在 TextEncodeAceStepAudio1.5 (#94) 中编写您的描述,包括节奏(BPM)、拍号、调性、编排、乐器、编曲、声乐存在和混音笔记等有用的音乐元数据。节点发出积极的条件;ConditioningZeroOut (#47) 提供一个中性的负路径,以便生成保持专注于您的描述。EmptyAceStep1.5LatentAudio (#98) 初始化所选时长的潜在音频时间线。ModelSamplingAuraFlow (#78) 将基础模型适配为适合 ACE-Step 音频的调度器。KSampler (#3) 将模型、条件、潜在变量和种子结合生成音乐潜在变量。VAEDecodeAudio (#18) 将潜在变量转换回波形,SaveAudioMP3 (#107) 将结果写入 MP3 文件,准备分享。
Comfyui ACE-Step 1.5XL 基础文本到音乐工作流中的关键节点#
TextEncodeAceStepAudio1.5 (#94)#
将您的提示转化为扩散模型可以遵循的条件。它接受音乐细节,如节奏、拍号、调性、编排笔记、乐器、语言和可选的声乐意图。为获得最佳效果,请具体说明流派、感觉和混音位置,并保持结构性提示简洁,以便模型在请求的时长内保持连贯性。
EmptyAceStep1.5LatentAudio (#98)#
为作品创建潜在音频“画布”。将其秒数与您在 Song Duration (#99) 中设置的时长匹配,并在文本编码器中引用,以避免意外截断或填充。较长的画布邀请更渐进的发展,而较短的画布适合循环、提示和片段。
ModelSamplingAuraFlow (#78)#
配置适合 ACE-Step 音频的采样策略。按提供的方式使用以获得稳定的结果;仅在您有特定的调度器偏好时调整,因为它与 KSampler (#3) 中的步数和指导交互。
KSampler (#3)#
执行将条件转化为音频潜在变量的去噪。这里的关键杠杆是采样器类型、步数和种子。增加步数以细化细节,代价是时间;比较提示时保持种子不变,以便将变化归因于文本而非随机性。
DualCLIPLoader (#105)#
加载两个 Qwen ACE15 文本编码器。如果您可以访问两者,请先激活 4B 编码器以获得更丰富的语言理解;当您需要更快的迭代或更低的内存使用时,切换到 0.6B 变体。在评估细微提示编辑时,保持编码器选择一致。
ConditioningZeroOut (#47)#
提供一个中性的负路径。如果您想抑制特定的伪影或远离语音内容,您可以用实际的负提示节点替换此项;否则,零负值保持 ACE-Step 1.5XL 基础文本到音乐生成专注于您的积极描述。
可选附加项#
- 使用紧凑的配方开始提示:流派 + 情绪 + 节奏 + 拍号 + 调性 + 乐器 + 编排 + 混音笔记。
- 使用明确的音乐动词和角色(主导、垫底、低音、打击乐),以便模型在混音中分配空间,避免语音内容。
- 在 A/B 测试提示时固定种子,然后变化种子以探索获胜想法的替代演绎。
- 在
Song Duration(#99)、TextEncodeAceStepAudio1.5(#94) 和EmptyAceStep1.5LatentAudio(#98) 中保持时长一致,以便预测短语。 - 选择 Qwen 4B 以获得更丰富的提示理解或 0.6B 以获得速度;在迭代时保持您的选择一致,以便进行公平比较。
致谢#
此工作流实现并建立在以下作品和资源之上。我们感谢 Comfy.org 为 audio_ace_step1_5_xl_base 工作流,Comfy-Org 为 ACE Step 1.5 XL Base 扩散模型和 ACE Step 1.5 VAE,以及 Qwen 团队为 0.6B 和 4B ACE15 文本编码器的贡献和维护。有关权威的详细信息,请参阅下面链接的原始文档和存储库。
资源#
- Comfy.org/工作流源页面
- 文档 / 发布说明:audio_ace_step1_5_xl_base 工作流页面
- Comfy-Org/ACE Step 1.5 XL Base 扩散模型
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Qwen 0.6B ACE15 文本编码器
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Qwen 4B ACE15 文本编码器
- Hugging Face: qwen_4b_ace15.safetensors
注意:使用所引用的模型、数据集和代码需遵守其作者和维护者提供的各自许可和条款。