
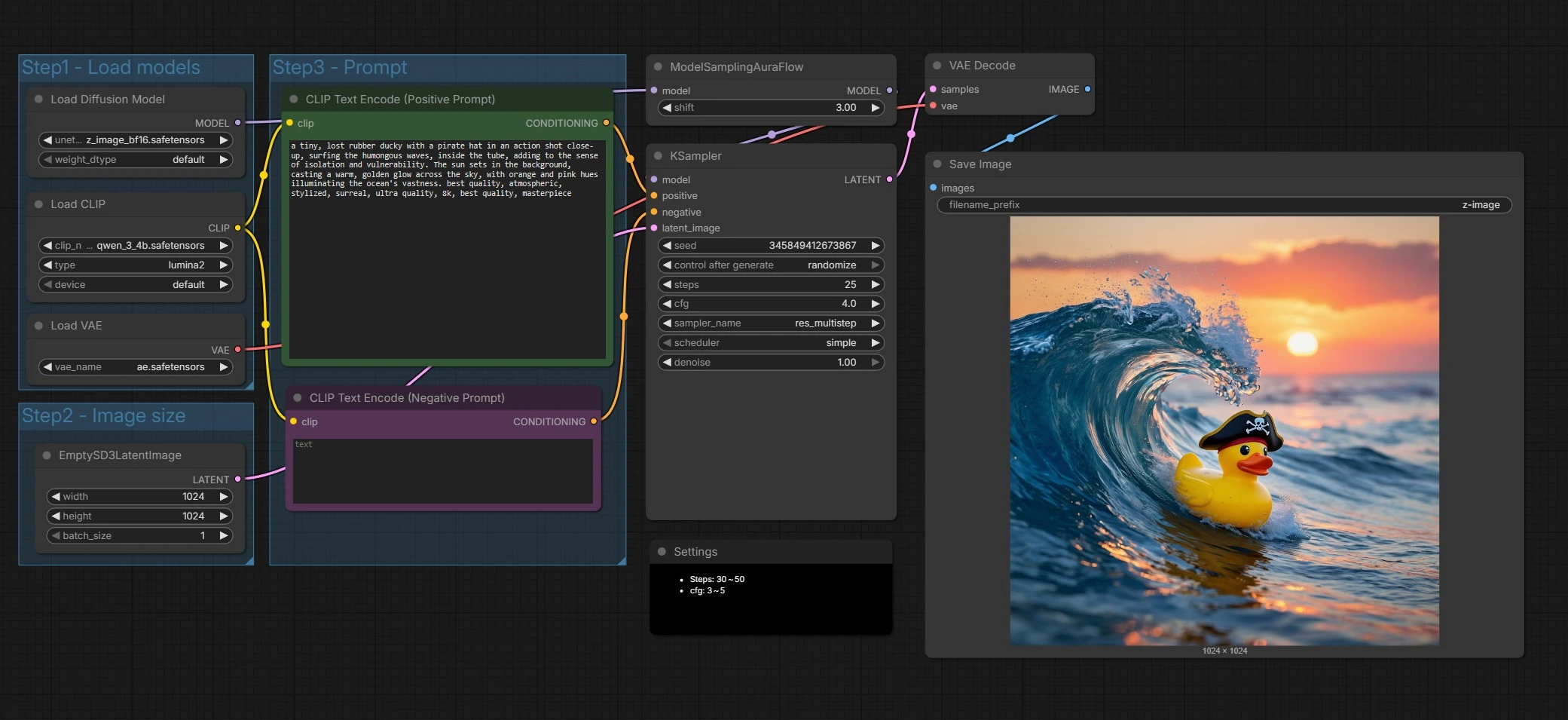
















Z-Image текст-в-изображение рабочий процесс для ComfyUI#
Этот рабочий процесс ComfyUI демонстрирует Z-Image, трансформер следующего поколения, разработанный для быстрой, высококачественной генерации изображений. Построен на масштабируемой одно-поточной архитектуре с около 6 миллиардов параметров, Z-Image балансирует между фотореализмом, сильной приверженностью задачам и отображением текста на двух языках.
Из коробки график настроен на Z-Image Base для максимизации качества при сохранении эффективности на обычных GPU. Он также хорошо работает с вариантом Z-Image Turbo, когда важна скорость, а его структура делает его легким для расширения в сторону Z-Image Edit для задач "изображение-в-изображение". Если вам нужен надежный, минимальный график, который превращает четкие задачи в чистые результаты, этот рабочий процесс Z-Image является надежной отправной точкой.
Ключевые модели в рабочем процессе Comfyui Z-Image#
- Z-Image Base трансформер диффузии (bf16). Основной генератор, который удаляет шум из латентов в изображения с одно-поточной топологией и контролем задач Z-Image. Страница модели • bf16 веса
- Qwen 3 4B текстовый энкодер. Кодирует задачи для Z-Image с сильным двухязычным покрытием и четкой токенизацией для отображения текста. веса энкодера
- Z-Image автоэнкодер VAE. Сжимает и восстанавливает изображения между пространством пикселей и латентным пространством Z-Image. VAE веса
Как использовать рабочий процесс Comfyui Z-Image#
На высоком уровне график загружает компоненты Z-Image, подготавливает латентный холст, кодирует ваши положительные и отрицательные задачи, запускает самплер, настроенный для Z-Image, затем декодирует и сохраняет результат. В основном, вы предоставляете задачу и выбираете размер вывода; остальное настроено для разумных значений по умолчанию.
Шаг1 - Загрузка моделей#
Эта группа инициализирует Z-Image UNet, текстовый энкодер Qwen 3 4B и VAE, чтобы все компоненты соответствовали. UNETLoader (#66) по умолчанию указывает на Z-Image Base, который отдает предпочтение верности и возможностям редактирования. CLIPLoader (#62) подключает энкодер на основе Qwen, который хорошо обрабатывает многоязычные задачи и текстовые токены. VAELoader (#63) устанавливает автоэнкодер, используемый позже для декодирования. Замените веса здесь, если хотите попробовать Z-Image Turbo для более быстрой черновой работы.
Шаг2 - Размер изображения#
Эта группа настраивает латентный холст через EmptySD3LatentImage (#68). Выберите ширину и высоту, на которой хотите генерировать, и учитывайте соотношение сторон для композиции. Z-Image хорошо работает на распространенных творческих размерах, поэтому выберите размеры, которые соответствуют вашим раскадровкам или формату доставки. Большие размеры увеличивают детализацию и стоимость вычислений.
Шаг3 - Задача#
Здесь вы пишете свою историю. Узел CLIP Text Encode (Positive Prompt) (#67) принимает описание сцены и стилистические указания для Z-Image. Узел CLIP Text Encode (Negative Prompt) (#71) помогает избегать артефактов или нежелательных элементов. Z-Image настроен для отображения текста на двух языках, поэтому вы можете включать текстовое содержание на нескольких языках непосредственно в задачу, когда это необходимо. Держите задачи конкретными и визуальными для наиболее последовательных результатов.
Образец и удаление шума#
ModelSamplingAuraFlow (#70) применяет политику выборки, согласованную с одно-поточным дизайном Z-Image, затем KSampler (#69) управляет процессом удаления шума, чтобы превратить шум в изображение, которое соответствует вашим задачам. Самплер сочетает ваши положительные и отрицательные условия с латентным холстом, чтобы итеративно уточнять структуру и детали. Вы можете обменивать скорость на качество здесь, настраивая параметры самплера, как описано ниже. На этом этапе действительно проявляется приверженность задачам Z-Image и ясность текста.
Декодирование и сохранение#
VAEDecode (#65) преобразует финальный латент в RGB изображение. SaveImage (#9) записывает файлы, используя префикс, установленный в узле, чтобы ваши выходные данные Z-Image было легко найти и организовать. Это завершает полный проход от задачи до пикселей.
Ключевые узлы в рабочем процессе Comfyui Z-Image#
UNETLoader (#66)#
Загружает основу Z-Image, выполняющую фактическое удаление шума. Переключитесь на другой вариант Z-Image здесь, когда исследуете скорость или случаи использования редактирования. Если вы меняете варианты, держите энкодер и VAE совместимыми, чтобы избежать изменения цвета или контраста.
CLIP Text Encode (Positive Prompt) (#67)#
Кодирует основное описание для Z-Image. Пишите краткие, визуальные фразы, которые указывают на объект, освещение, камеру, настроение и любой текст на изображении. Для отображения текста поместите желаемые слова в кавычки и держите их короткими для лучшей читабельности.
CLIP Text Encode (Negative Prompt) (#71)#
Определяет, чего избегать, чтобы Z-Image мог сосредоточиться на правильных деталях. Используйте его для подавления размытия, лишних конечностей, неаккуратной типографики или элементов вне стиля. Держите его кратким и по теме, чтобы он не чрезмерно ограничивал композицию.
EmptySD3LatentImage (#68)#
Создает латентный холст, на котором Z-Image будет рисовать. Выберите размеры, которые подходят для окончательного использования, и держите их кратными 64 пикселям для эффективного использования памяти. Более широкие или высокие холсты влияют на композицию и перспективу, поэтому корректируйте задачи соответственно.
ModelSamplingAuraFlow (#70)#
Выбирает предустановку самплера, которая соответствует обучению и латентному пространству Z-Image. Вам редко нужно менять это, если только вы не тестируете альтернативные самплеры. Оставьте его как предоставлено для стабильных, свободных от артефактов результатов.
KSampler (#69)#
Контролирует компромисс между качеством и скоростью для Z-Image. Увеличьте steps для большей детализации и стабильности, уменьшите для более быстрых черновиков. Держите cfg умеренным, чтобы сбалансировать приверженность задачам с натуральными текстурами; типичные значения в этом графике: steps: 30 до 50 и cfg: 3 до 5. Установите фиксированный seed для воспроизводимости или рандомизируйте его, чтобы исследовать вариации.
VAEDecode (#65)#
Преобразует финальный латент из Z-Image в RGB изображение. Если вы когда-либо меняете VAE, держите его соответствующим семейству моделей, чтобы сохранить точность цвета и резкость.
SaveImage (#9)#
Записывает результат с четким префиксом имени файла, чтобы выходные данные Z-Image было легко каталогизировать. Настройте префикс, чтобы разделить эксперименты, варианты моделей или соотношения сторон.
Дополнительные опции#
- Используйте Z-Image Turbo для быстрого генерирования идей, затем переключитесь обратно на Z-Image Base и увеличьте шаги для финальных рендеров.
- Для двухязычных задач и текста на изображении держите формулировки короткими и с высоким контрастом в задаче, чтобы помочь Z-Image отобразить четкую типографику.
- Заблокируйте seed при сравнении небольших изменений задач, чтобы различия отражали ваши изменения, а не новый шум.
- Если вы видите перенасыщение или ореолы, немного снизьте
cfgили усильте отрицательную задачу, чтобы восстановить баланс.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы искренне благодарны Comfy-Org за шаблон рабочего процесса Z-Image Day-0 для ComfyUI за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Comfy-Org/Z-Image Day-0 поддержка в ComfyUI
- GitHub: Comfy-Org/workflow_templates
- Документы / Примечания к выпуску: Источник
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими лицами.
