
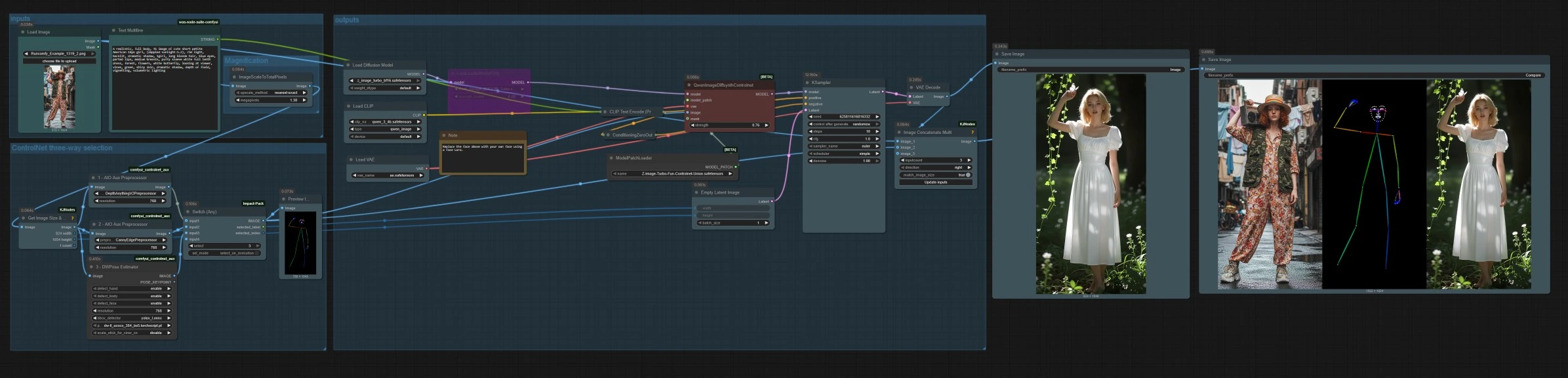








Рабочий процесс Z Image ControlNet для генерации изображений с учетом структуры в ComfyUI#
Этот рабочий процесс привносит Z Image ControlNet в ComfyUI, чтобы вы могли управлять Z‑Image Turbo с точной структурой из справочных изображений. Он объединяет три режима управления в одном графе: глубина, края canny и человеческая поза, и позволяет переключаться между ними в зависимости от вашей задачи. Результат — быстрая, высококачественная генерация текста или изображения в изображение, где макет, поза и композиция остаются под контролем, пока вы итеративно работаете.
Разработан для художников, концептуальных дизайнеров и планировщиков макетов, график поддерживает двуязычные подсказки и необязательный стиль LoRA. Вы получаете чистый предварительный просмотр выбранного управляющего сигнала плюс автоматическую полосу сравнения для оценки глубины, краев canny или позы по сравнению с конечным результатом.
Ключевые модели в рабочем процессе Comfyui Z Image ControlNet#
- Модель диффузии Z‑Image Turbo с 6B параметрами. Основной генератор, который быстро создает фотореалистичные изображения из подсказок и управляющих сигналов. alibaba-pai/Z-Image-Turbo
- Патч Z Image ControlNet Union. Добавляет многоконтурное управление в Z‑Image Turbo и позволяет управление глубиной, краями и позой в одном патче модели. alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2. Создает плотные карты глубины, используемые для управления структурой в режиме глубины. LiheYoung/Depth-Anything-V2 на GitHub
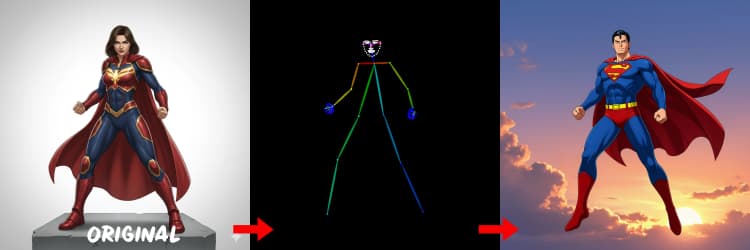
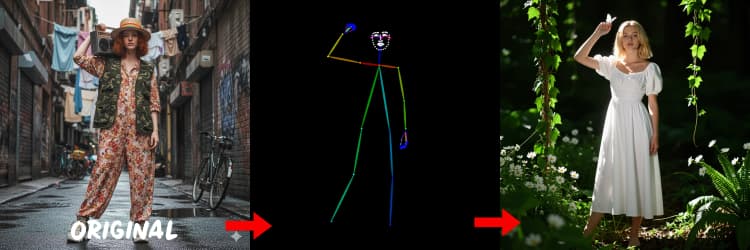
- DWPose. Оценивает ключевые точки человека и позу тела для генерации, управляемой позой. IDEA-Research/DWPose
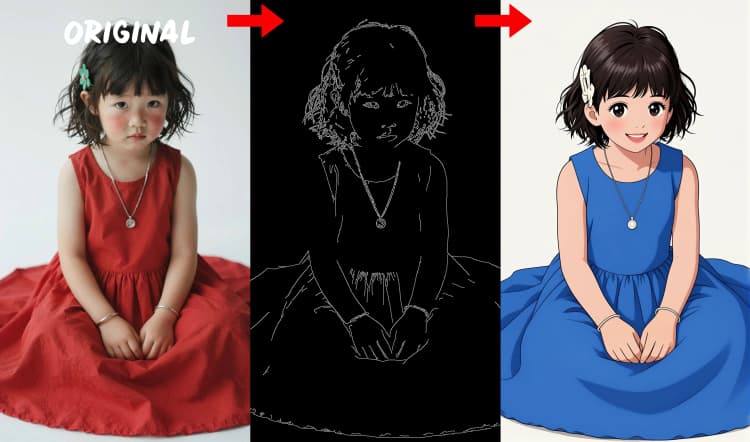
- Детектор краев Canny. Извлекает чистое линейное искусство и границы для управления, основанного на макете.
- Вспомогательные препроцессоры ControlNet для ComfyUI. Предоставляет унифицированные обертки для глубины, краев и поз, используемых в этом графике. comfyui_controlnet_aux
Как использовать рабочий процесс Comfyui Z Image ControlNet#
На высоком уровне вы загружаете или загружаете справочное изображение, выбираете один режим управления из глубины, canny или позы, затем генерируете с текстовой подсказкой. График масштабирует справочное изображение для эффективной выборки, создает латентное изображение с подходящим соотношением сторон и сохраняет как конечное изображение, так и полосу сравнения.
Входные данные#
Используйте LoadImage (#14) для выбора справочного изображения. Введите свою текстовую подсказку в Text Multiline (#17) стэк Z‑Image поддерживает двуязычные подсказки. Подсказка кодируется CLIPLoader (#2) и CLIPTextEncode (#4). Если вы предпочитаете полностью управление изображением в изображение, вы можете оставить подсказку минимальной и полагаться на выбранный управляющий сигнал.
Трехсторонний выбор ControlNet#
Три препроцессора преобразуют ваше справочное изображение в управляющие сигналы. AIO_Preprocessor (#45) создает глубину с Depth Anything v2, AIO_Preprocessor (#46) извлекает края canny, а DWPreprocessor (#56) оценивает полную позу тела. Используйте ImpactSwitch (#58), чтобы выбрать, какой сигнал управляет Z Image ControlNet, и проверьте PreviewImage (#43), чтобы подтвердить выбранную управляющую карту. Выберите глубину, когда вам нужна геометрия сцены, canny для четкого макета или продуктовых фото, а позу для работы с персонажами.
Советы для OpenPose: 1. Лучше для всего тела: OpenPose работает лучше (~70-90% точности), когда вы включаете "всё тело" в вашу подсказку. 2. Избегайте для крупного плана: Точность значительно падает на лицах. Используйте Depth или Canny (низкой/средней силы) для крупного плана вместо этого. 3. Подсказки важны: Подсказки сильно влияют на ControlNet. Избегайте пустых подсказок, чтобы предотвратить размытые результаты.
Увеличение#
ImageScaleToTotalPixels (#34) изменяет размер справочного изображения до практического рабочего разрешения для баланса качества и скорости. GetImageSizeAndCount (#35) считывает масштабированный размер и передает ширину и высоту вперед. EmptyLatentImage (#6) создает латентное изображение, соответствующее соотношению сторон вашего измененного входного изображения, чтобы композиция оставалась согласованной.
Выходные данные#
QwenImageDiffsynthControlnet (#39) объединяет базовую модель с патчем Z Image ControlNet union и выбранным управляющим изображением, затем KSampler (#7) генерирует результат, управляемый вашей положительной и отрицательной настройкой. VAEDecode (#8) преобразует латентное изображение в изображение. Рабочий процесс сохраняет два вывода: SaveImage (#31) записывает конечное изображение, а SaveImage (#42) записывает полосу сравнения через ImageConcatMulti (#38), которая включает источник, управляющую карту и результат для быстрой проверки качества.
Ключевые узлы в рабочем процессе Comfyui Z Image ControlNet#
ImpactSwitch (#58)#
Выбирает, какое управляющее изображение управляет генерацией глубины, краев или позы. Переключайте режимы, чтобы сравнить, как каждое ограничение формирует композицию и детали. Используйте его при итерации макетов, чтобы быстро протестировать, какое руководство лучше всего соответствует вашей цели.
QwenImageDiffsynthControlnet (#39)#
Соединяет базовую модель, патч Z Image ControlNet union, VAE и выбранный управляющий сигнал. Параметр strength определяет, насколько строго модель следует управляющему вводу по сравнению с подсказкой. Для точного соответствия макету увеличьте силу для более творческих вариаций, уменьшите её.
AIO_Preprocessor (#45)#
Запускает конвейер Depth Anything v2 для создания плотных карт глубины. Увеличьте разрешение для более детализированной структуры или уменьшите для более быстрых предварительных просмотров. Хорошо сочетается с архитектурными сценами, продуктовыми фото и пейзажами, где важна геометрия.
DWPreprocessor (#56)#
Создает карты поз, подходящие для людей и персонажей. Лучше всего работает, когда конечности видны и не сильно скрыты. Если руки или ноги отсутствуют, попробуйте более четкую справочную или другой кадр с более полной видимостью тела.
LoraLoaderModelOnly (#54)#
Применяет необязательный LoRA к базовой модели для стиля или идентификационных сигналов. Настройте strength_model, чтобы плавно или сильно смешать LoRA. Вы можете заменить лицо LoRA, чтобы персонализировать объекты, или использовать стиль LoRA, чтобы закрепить определенный вид.
KSampler (#7)#
Выполняет диффузионную выборку, используя вашу подсказку и управление. Настройте seed для воспроизводимости, steps для бюджета уточнения, cfg для соответствия подсказке и denoise для того, насколько вывод может отклоняться от начального латентного. Для редактирования изображения в изображение уменьшите denoise для сохранения структуры, более высокие значения позволяют более крупные изменения.
Необязательные дополнения#
- Чтобы ужесточить композицию, используйте режим глубины с чистым, равномерно освещенным справочным изображением; canny предпочитает сильный контраст, а поза предпочитает полные снимки тела.
- Для тонких правок из исходного изображения держите denoise умеренным и увеличьте силу ControlNet для верной структуры.
- Увеличьте целевые пиксели в группе увеличения, когда вам нужно больше деталей, затем снова уменьшите для быстрого черновика.
- Используйте выход сравнения для быстрого A/B тестирования глубины против canny против позы и выберите наиболее надежное управление для вашего объекта.
- Замените пример LoRA на своё собственное лицо или стиль LoRA, чтобы включить идентичность или художественное направление без повторного обучения.
Благодарности#
Этот рабочий процесс реализует и строится на следующих работах и ресурсах. Мы с благодарностью признаем Alibaba PAI за Z Image ControlNet за их вклад и поддержку. Для получения авторитетной информации, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведенным ниже.
Ресурсы#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.


