
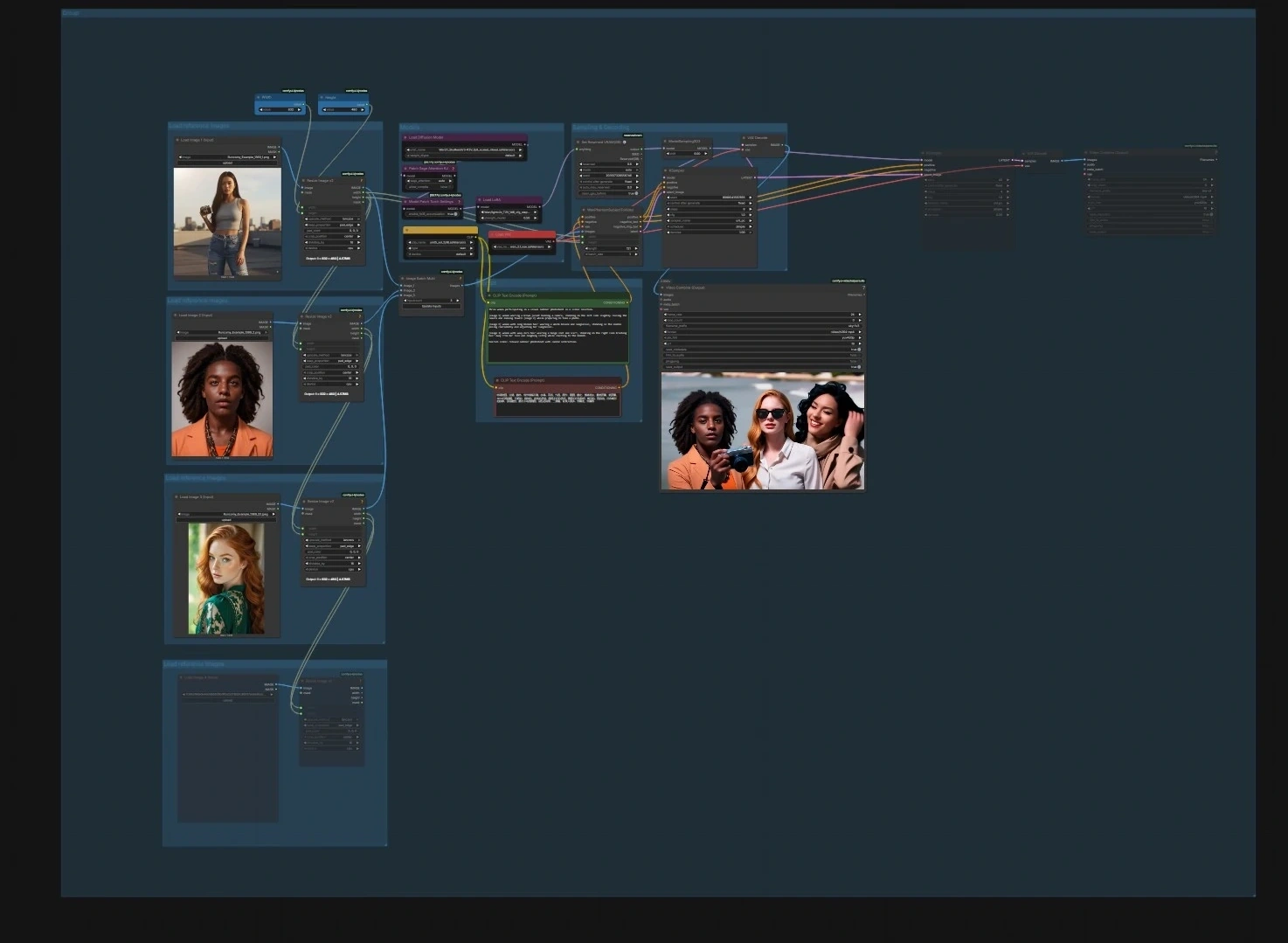
SkyReels V3 ComfyUI: идентично‑верное создание изображений, видео и аудио в видео#
SkyReels V3 ComfyUI — это готовый к производству рабочий процесс, который внедряет мультимодальную видеомодель SkyReels V3 в ComfyUI, чтобы вы могли анимировать неподвижные изображения, расширять существующие кадры и создавать аудио‑аватары с точным синхроном губ. Он разработан для создателей, которые хотят получить кинематографическое движение, сильную идентичность объекта и временную согласованность, оставаясь в гибкой схеме узлов.
Рабочий процесс включает четыре целенаправленных конвейера, которые можно запускать независимо или связывать: анимация персонажей из изображений в видео, продолжение видео в видео, говорящие аватары из аудио в видео и генерация следующего кадра для потока истории. Каждый путь включает чёткие точки ввода и разумные значения по умолчанию, чтобы вы могли быстро вставить свои активы и рендерить высококачественные результаты SkyReels V3.
Примечание для машин 2X Large и больше (R2V workflow): Установите
Patch Sage Attention KJ(#240)sage_attentionвdisabledперед запуском. Если оставить включённым, это может вызвать ошибкиSM90 kernel is not available.
Ключевые модели в рабочем процессе Comfyui SkyReels V3 ComfyUI#
- SkyReels V3 видео‑основы (R2V, V2V Shot, A2V) из пакета WanVideo FP8. Это основные генераторы, которые обрабатывают идентично‑осознающее движение, продолжение видео и аудио‑условленный синхрон губ. См. веса SkyReels V3 в пакете WanVideo на Hugging Face здесь.
- OpenCLIP Vision ViT модели для руководства изображением и встраивания ссылок. Они предоставляют надёжные визуальные функции, которые помогают сохранить внешний вид и стиль на всех кадрах. Страница проекта: open_clip.
- UMT5 текстовый кодировщик для понимания подсказок. Он обеспечивает богатое языковое кондиционирование для управления стилем, сценой и действиями. Репозиторий: umt5.
- Функции речи Wav2Vec2 для синхрона губ и анализа аудио. Китайский базовый вариант поддерживается из коробки, а аналогичные английские варианты также работают. Карта модели: TencentGameMate/chinese-wav2vec2-base.
- Qwen3‑ASR‑1.7B для преобразования речи в текст. Используется для транскрибирования эталонного аудио и начальной загрузки голосовых подсказок TTS. Карта модели: Qwen/Qwen3-ASR-1.7B.
- MelBandRoFormer для разделения вокала. Полезно, когда вам нужны чистые речевые треки перед встраиванием синхрона губ. Карта модели: Kijai/MelBandRoFormer_comfy.
- MiniCPM‑V для генерации подсказок с учётом кадра. Он анализирует предыдущие кадры и предлагает следующий кадр для непрерывности истории. Хаб модели: OpenBMB/MiniCPM-V.
Как использовать рабочий процесс Comfyui SkyReels V3 ComfyUI#
Граф организован в четыре конвейера. Вы можете запустить любой из них отдельно или последовательно, чтобы создавать более длинные редактирования.
Анимация персонажа из изображения в видео#
- Модели. Загрузите UNet, CLIP и VAE в группу моделей с помощью
UNETLoader(#241),CLIPLoader(#242) иVAELoader(#194). Узлы патча моделиPathchSageAttentionKJ(#240) иModelPatchTorchSettings(#239) оптимизируют настройки внимания и математики, в то время какLoraLoaderModelOnly(#250) позволяет вам опционально смешивать стиль или движение LoRA в модель SkyReels. - Загрузите эталонные изображения. Используйте три группы “Load reference images” для импорта 1–3 портретов или поз. Помощники по изменению размера
ImageResizeKJv2(#291, #298, #299, #304) выравнивают соотношение сторон и пакетируют их; более чистые фотографии идентичности дают более стабильные результаты. - Подсказка. Введите текст сцены и действия в группу Подсказок с
CLIPTextEncode(#6) и опциональным отрицательным текстовым кодировщикомCLIPTextEncode(#7), чтобы отодвинуть нежелательные черты. Держите язык лаконичным и конкретным для движения и кадрирования. - Выборка и декодирование.
WanPhantomSubjectToVideo(#249) объединяет ваши эталонные изображения и подсказки в идентично‑осознающий латент, который питаетKSampler(#149) черезModelSamplingSD3(#48). Декодированные кадры изVAEDecode(#264) упаковываются в фильм сVHS_VideoCombine(#280); установите целевую частоту кадров и формат файла там.
Продление цикла видео в видео#
- Входное видео и настройки. Принесите свой исходный клип с
VHS_LoadVideo(#329). Установите, сколько дополнительных сегментов генерировать и сколько перекрытия между сегментами, используя целочисленные помощники “Number of Extend” (#342) и “Overlapping Frames” (#341).ImageResizeKJv2(#327) стандартизирует разрешение для выборщика. - Цикл выборки продлевает видео. Пара цикла
easy forLoopStart(#331) иeasy forLoopEnd(#332) проходит по клипу в окнах, чтобы стабилизировать переходы. Каждое окно кодируется с помощьюWanVideoEncode(#326), получает нейтральные или контрольные встраивания черезWanVideoEmptyEmbeds(#328), и очищается с помощьюWanVideoSampler(#320) изWanVideoModelLoader(#319). Кадры декодируются с помощьюWanVideoDecode(#321) и предварительно просматриваются или сохраняются с помощьюVHS_VideoCombine(#322, #335). - Помощники по производительности.
WanVideoTorchCompileSettings(#323) иWanVideoBlockSwap(#325) позволяют использовать трюки компиляции и памяти для более длинных или более высоких разрешений.
Говорящий аватар из аудио в видео#
- 1 – Создайте аудио. Вы можете сгенерировать голосовой трек с клонированным голосом с помощью
FB_Qwen3TTSVoiceClonePrompt(#416) иFB_Qwen3TTSVoiceClone(#412), или загрузить любой предварительно записанный голос с помощьюLoadAudio(#417).Qwen3ASRLoader(#414) плюсQwen3ASRTranscribe(#413) помогают извлечь текст из эталонного клипа, чтобы засеять подсказку TTS, если это необходимо. - 2 – Аудиофункции.
DownloadAndLoadWav2VecModel(#348) подаётMultiTalkWav2VecEmbeds(#350) для создания встраиваний движения губ из вашей речи; длина синхронизирована с аудио и предварительно просматривается с помощьюPreviewAudio(#422). ИспользуйтеAny Switch (rgthree)(#435), чтобы выбрать выход TTS или ваш импортированный файл в качестве управляющего трека. - 3 – Входное изображение. Загрузите говорящее лицо в группу “3 - Input image” и определите размер с помощью
ImageResizeKJv2(#370). Чистые, лицевые портреты с постоянным освещением работают лучше всего. - Генерация эталонного видео. Сначала создайте короткий визуальный якорь из неподвижного изображения с помощью
WanVideoImageToVideoEncode(#392). Функции CLIP‑Vision изCLIPVisionLoader(#352) иWanVideoClipVisionEncode(#351) стабилизируют идентичность на следующем этапе; планировщикWanVideoSchedulerv2(#385) подготовлен в группе Настройки выборки. - Генерация синхрона губ с аудио.
WanVideoImageToVideoSkyreelsv3_audio(#383) сочетает начальное изображение, опциональные эталонные кадры и встраивания CLIP‑Vision в условие изображения.WanVideoSamplerv2(#384) затем очищает с помощью модели SkyReels A2V, в то время какWanVideoSamplerExtraArgs(#386) вводит встраиванияMultiTalkдля точных форм рта.WanVideoPassImagesFromSamples(#381) передаёт декодированные кадры вVHS_VideoCombine(#346), где финальное видео соединяется с вашим аудио.
Генерация следующего кадра из видео в видео#
- Предварительная обработка кадров видео. Импортируйте предыдущий кадр с помощью
VHS_LoadVideo(#443) и измените его размер с помощьюImageResizeKJv2(#441).GetImageRangeFromBatch(#445) выбирает контекстный срез, которыйWanVideoEncode(#440) превращает в латенты;WanVideoEmptyEmbeds(#442) подготавливает окно условия. - Автоматическая видеоподсказка.
CreateVideo(#450) собирает компактный прокси‑клип из контекстных кадров, которыеAILab_MiniCPM_V_Advanced(#449) анализирует, чтобы составить черновик следующей подсказки. Проверьте или уточните черновик вShowText|pysssss(#447) и внедрите его с помощьюWanVideoTextEncodeCached(#444) перед выборкой. - Модели и выборка. Загрузите модель V2V Shot с помощью
WanVideoModelLoader(#436) иWanVideoVAELoader(#438); опциональныйWanVideoBlockSwap(#439) обрабатывает VRAM.WanVideoSampler(#451) генерирует продолжение,WanVideoDecode(#437) рендерит кадры, иVHS_VideoCombine(#446) выводит финальный кадр. Этот путь SkyReels V3 ComfyUI идеально подходит для раскадровок и предварительных визуализаций, где каждый новый кадр должен уважать предыдущий.
Ключевые узлы в рабочем процессе Comfyui SkyReels V3 ComfyUI#
WanPhantomSubjectToVideo(#249). Создаёт идентично‑осознающий латент из ваших пакетированных эталонных изображений и текстовых подсказок, который затем управляет выборщиком. Настройте количество и разнообразие эталонов для балансировки фиксации сходства и креативного движения; держите узлы изменения размера, которые его питают, последовательными, чтобы избежать дрейфа. Ссылка: WanVideo Wrapper на GitHub содержит заметки по реализации и ожидаемые входы ComfyUI‑WanVideoWrapper.WanVideoImageToVideoEncode(#392). Кодирует неподвижное изображение в стабильное семя кадра и опционально смешивает руководство CLIP‑Vision для позы и кадрирования. Используйте его для создания якорных кадров перед этапом, управляемым аудио, чтобы идентичность и установка камеры оставались последовательными через конвейеры. Документы обёртки: ComfyUI‑WanVideoWrapper.WanVideoImageToVideoSkyreelsv3_audio(#383). Подготавливает встраивания изображений, адаптированные для выборщика A2V, и объединяет опциональные эталонные кадры видео. Убедитесь, что его ширина и высота соответствуют пути выборщика; соедините его сWanVideoSamplerv2иMultiTalkWav2VecEmbedsдля точного синхрона губ.WanVideoSamplerv2(#384, #387). Основной очиститель для SkyReels V3, который принимает встраивания изображений и текста плюс настройки планировщика. УзлыWanVideoSamplerExtraArgs(#386, #409) — это то место, где вводятся функции синхрона губ, цикла или контекста; держите их подключёнными при переключении между моделями A2V и I2V. Детали реализации: ComfyUI‑WanVideoWrapper.MultiTalkWav2VecEmbeds(#350). Преобразует речь во временно выровненные встраивания, которые управляют движением рта. Соответствие запланированного бюджета кадров и обеспечение чистых вокалов значительно улучшает точность фонем. Справочная модель Wav2Vec: TencentGameMate/chinese-wav2vec2-base.AILab_MiniCPM_V_Advanced(#449). Анализирует предыдущий кадр и составляет структурированную подсказку для персонажа, фона, действий, настроения и освещения. Используйте это, чтобы сохранить непрерывность повествования при использовании пути V2V следующего кадра; полученный текст передаётся вWanVideoTextEncodeCached. Семейство моделей: OpenBMB/MiniCPM-V.
Дополнительные возможности#
- Держите разрешения изображений, видео и выборщика последовательными на всех подключённых узлах, чтобы избежать искажений аспектов и мерцания идентичности.
- Для более длинных расширений увеличьте перекрытие окон в цикле продления V2V, чтобы сгладить переходы между сегментами.
- Если память GPU ограничена, оставьте узлы Reserved VRAM (
ReservedVRAMSetter(#312, #448)) включёнными и используйте блоки настроек компиляции перед выборкой. - Когда говорящие аватары сбиваются с ритма, отдавайте приоритет чистой речи или разделяйте вокалы с помощью MelBandRoFormer перед созданием встраиваний
MultiTalk. - Финальные настройки доставки, такие как частота кадров, формат пикселей и CRF, контролируются в выходных узлах
VHS_VideoCombine; сопоставьте частоту кадров с вашим источником для бесшовного редактирования.
Этот README охватывает полный граф SkyReels V3 ComfyUI, чтобы вы могли выбрать путь, который подходит вашему проекту, комбинировать их при необходимости и рендерить последовательное, готовое к истории видео с минимальными пробами и ошибками.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью признаём @Benji’s AI Playground и SkyReels за их вклад и поддержку в SkyReels V3 ComfyUI workflow. За авторитетной информацией обращайтесь к оригинальной документации и репозиториям, связанным ниже.
Ресурсы#
- SkyReels/V3 ComfyUI Source
- Документы / Примечания к выпуску: SkyReels V3 ComfyUI Source from @Benji’s AI Playground
Примечание: использование указанных моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими сторонами.