
LTX-2 ControlNet: создание видео, управляемого структурой, с синхронизацией аудио в ComfyUI#
LTX-2 ControlNet — это управляемый рабочий процесс ComfyUI для расширения ComfyUI-LTXVideo, который позволяет вам управлять генерацией видео LTX-2 с помощью глубины, краев и поз, сохраняя синхронизацию аудио и визуальных эффектов. Он работает в едином аудио-визуальном латентном пространстве, так что речь, фоли и движение генерируются вместе и остаются выровненными от первого кадра до последнего.
Создан для текст-видео, изображение-видео и видео-видео, рабочий процесс добавляет кондиционирование ControlNet на основе IC LoRA для точного управления макетом и движением, инициализации первого кадра для непрерывности сцены и двухэтапного конвейера с латентным масштабированием для четких результатов без увеличения VRAM. LTX-2 ControlNet полностью открыт, быстр в итерации и ориентирован на производство для создателей, которым нужны повторяемые, высококачественные выходы.
Ключевые модели в рабочем процессе Comfyui LTX-2 ControlNet#
- LTX-2 19B (dev FP8 и дистиллированный). Основная аудио-визуальная генеративная модель, используемая для выборки видео и аудио в едином латентном пространстве. Семейство моделей
- Gemma 3 12B IT текстовый энкодер. Обеспечивает надежное понимание языка для подсказок и негативов через упакованный энкодер, используемый LTX-2. Файл энкодера
- LTX-2 Spatial Upscaler x2. Латентная модель масштабирования, используемая на втором этапе для уточнения пространственной детализации. Масштабатор
- LTX-2 Audio VAE. Специализированный аудио декодер-энкодер, который поддерживает выровненный звук с кадрами. Включено с контрольными точками LTX-2. Контрольные точки
- Семейство IC LoRA для LTX-2. Добавляет кондиционирование в стиле ControlNet:
- Контроль глубины LoRA: ltx-2-19b-IC-LoRA-Depth-Control
- Контроль краев LoRA: ltx-2-19b-IC-LoRA-Canny-Control
- Контроль позы LoRA: ltx-2-19b-IC-LoRA-Pose-Control
- Дистиллированная LoRA для компромиссов качества/эффективности: ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1. Оценщик глубины, используемый в пути контроля глубины. Модель
- SD VAE FT MSE (Stability AI). Изображение VAE, используемое для предварительной обработки глубины и декодирования с мозаикой. VAE
- Расширение ComfyUI-LTXVideo. Предоставляет семплеры LTX-2, AV латенты, аудио VAE и управляющие узлы, используемые повсюду. Репозиторий
Как использовать рабочий процесс Comfyui LTX-2 ControlNet#
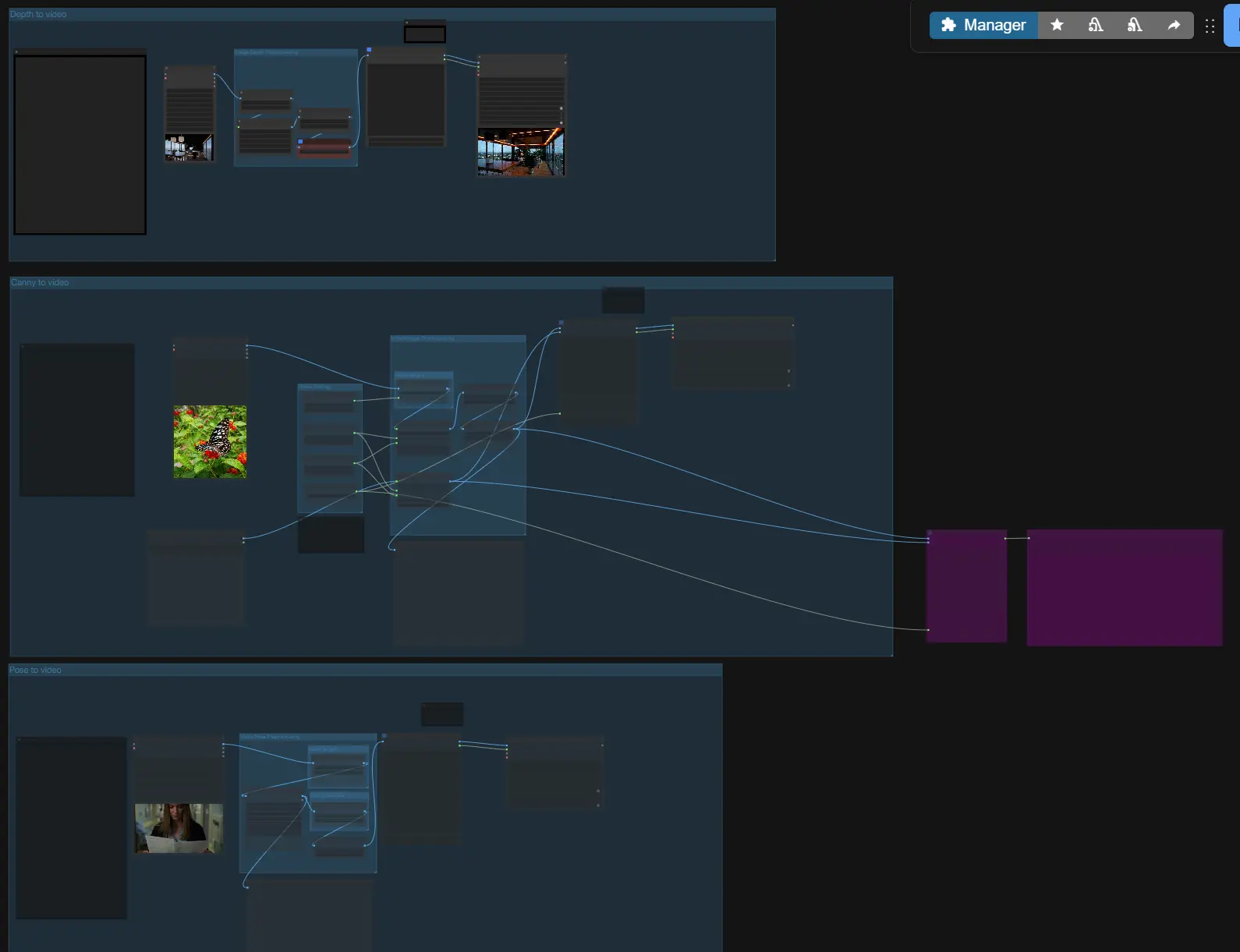
На высоком уровне, LTX-2 ControlNet принимает вашу подсказку и необязательные ссылки, строит аудио-визуальную латентность с руководством в стиле ControlNet, выполняет первую проходку, затем масштабирует латентность для четкого видео и синхронизированного аудио. Выберите один из трех направляемых путей (Глубина, Края, Поза) или используйте их независимо, затем установите длину и размер перед экспортом.
- Предварительная обработка изображений/видео
- Если вы выполняете преобразование изображения в видео или видео в видео, используйте загрузчики, чтобы добавить ваше эталонное медиа.
VHS_LoadVideo(#196, #197, #198) разбивает кадры для анализа, в то время какLoadImage(#189) обрабатывает статические изображения. Группа предоставляет удобное масштабирование, чтобы нижестоящие руководства видели согласованные размеры кадров. - Изображение "первого кадра" может быть передано вперед для инициализации сцены; вы включите это позже в группе генерации.
- Если вы выполняете преобразование изображения в видео или видео в видео, используйте загрузчики, чтобы добавить ваше эталонное медиа.
- Предварительная обработка глубины изображения
- Для руководства по глубине подграф "Изображение в карту глубины (Lotus)" преобразует ваш вход в нормализованную карту глубины с использованием Lotus Depth. Это подготавливает однокадровое или многокадровое представление глубины, которое LTX-2 может следовать.
- Путь включает в себя необязательное изменение размера и управления интенсивностью, чтобы руководство кодировало общую структуру без излишней подгонки к мелким артефактам.
- Предварительная обработка позы видео
- Для руководства по позе
DWPreprocessor(#158) обнаруживает ключевые точки всего тела из входного видео и масштабирует их для стабильного кондиционирования. Это дает чистую последовательность изображений позы, подчеркивающую ориентацию скелета и конечностей. - Узлы предварительного просмотра помогают быстро проверить, что обнаружения и соотношения сторон выглядят правильно перед генерацией.
- Для руководства по позе
- Края к видео
- Этот путь контроля извлекает края с помощью
Canny(#169), затем строит AV латентность с последовательностью управляющих изображений. Используйте его, когда хотите сохранить силуэты, основные контуры или края типографики из ссылки. - Входное изображение первого кадра доступно для согласованной инициализации; включайте его только когда хотите, чтобы открывающий кадр соответствовал определенному статическому изображению.
- Этот путь контроля извлекает края с помощью
- Глубина к видео
- Этот путь подает карты глубины Lotus в качестве управляющих изображений. Контроль глубины идеален для обеспечения геометрии камеры, крупномасштабного макета и расстояния до объекта, позволяя генератору выбирать текстуры и освещение.
- Вы можете предоставить первый кадр, чтобы зафиксировать начальную композицию, а затем позволить движению развиваться, руководствуясь подсказками глубины.
- Поза к видео
- Путь позы использует рендеринг ключевых точек из препроцессора, управляя ориентацией тела и синхронизацией движений. Он особенно эффективен для блокировки персонажей, синхронизации поднятия рук и циклов ходьбы.
- Как и в других режимах, вы можете сочетать синхронизацию подсказок с необязательной кондиционированием первого кадра для непрерывности.
- Настройки видео и длина
- Установите рабочую ширину, высоту и количество кадров в группах "Настройки видео" и "длина видео". Рабочий процесс автоматически корректирует недопустимые значения до ближайших совместимых размеров для латентной сетки и шага LTX-2, чтобы вы могли безопасно итеративно работать.
- Держите вашу целевую частоту кадров согласованной между узлами; узлы кондиционирования и финальный мукс уважают её для плавной синхронизации аудио и видео.
- Генерация, масштабирование и экспорт
- Во время семплирования
LTXVAddGuideинтегрирует ваше положительное/отрицательное кондиционирование с выбранными управляющими изображениями, затемSamplerCustomAdvancedвыполняет расписание отLTXVSchedulerкак для видео, так и для аудио латентов. Необязательный первый кадр вводится с помощьюLTXVImgToVideoInplace, где это включено. - На втором этапе
LTXVLatentUpsamplerуточняет детали с помощью x2 латентного масштабатора. Финальное декодирование происходит с помощью мозаичногоVAEDecodeTiledдля кадров иLTXVAudioVAEDecodeдля аудио, затем видео записывается сVHS_VideoCombineилиCreateVideoв зависимости от выбранной ветви.
- Во время семплирования
Ключевые узлы в рабочем процессе Comfyui LTX-2 ControlNet#
LTXVAddGuide(#132)- Объединяет текстовое кондиционирование и IC LoRA контролы в AV латент, действуя как сердце руководства LTX-2 ControlNet. Настройте только те немногие контролы, которые имеют значение: выберите контроль LoRA, соответствующий вашему пути (глубина, края или поза), и, когда доступно,
image_strength, который настраивает, насколько плотно модель следует за руководствами. Реализация ссылки и поведение узла предоставлены расширением LTXVideo. Документация/Код
- Объединяет текстовое кондиционирование и IC LoRA контролы в AV латент, действуя как сердце руководства LTX-2 ControlNet. Настройте только те немногие контролы, которые имеют значение: выберите контроль LoRA, соответствующий вашему пути (глубина, края или поза), и, когда доступно,
LTXVImgToVideoInplace(#149, #155)- Вставляет изображение первого кадра в AV латент для согласованной инициализации сцены. Используйте
strength, чтобы сбалансировать верность первому кадру и свободу развиваться; держите его ниже для большего движения и выше для более жестких якорей. Пропустите его, когда хотите чисто текстовые или управляемые открывающие кадры. Документация/Код
- Вставляет изображение первого кадра в AV латент для согласованной инициализации сцены. Используйте
LTXVScheduler(#95)- Управляет траекторией снижения шума для единой латентности, чтобы как аудио, так и видео сходились вместе. Увеличьте шаги для сложных сцен и тонких деталей; сократите для черновиков и быстрой итерации. Настройки расписания взаимодействуют с силой руководства, поэтому избегайте экстремальных значений, когда руководство сильно. Документация/Код
LTXVLatentUpsampler(#112)- Выполняет вторую стадию латентного масштабирования с помощью пространственного масштабатора LTX-2 x2, улучшая резкость с минимальным ростом VRAM. Используйте это после первого прохода, а не увеличивая базовое разрешение, чтобы итерации оставались отзывчивыми. Модель масштабатора
DWPreprocessor(#158)- Генерирует чистые ключевые точки человеческой позы для пути контроля позы. Проверьте обнаружения с предварительным просмотром; если руки или мелкие конечности шумные, масштабируйте входные данные до умеренного максимального размера перед предварительной обработкой. Предоставлено вспомогательным набором ControlNet. Репо
VHS_VideoCombine/CreateVideo(#195, #106)- Объединяет декодированные кадры и аудио в MP4 с выбранной частотой кадров и форматом пикселей. Используйте их только после подтверждения, что ваше аудио-декодирование выглядит выровненным в предварительном просмотре. Предоставлено Video Helper Suite. Репо
Дополнительные возможности#
- Подсказки для LTX-2 ControlNet
- Описывайте действия во времени, а не только статические атрибуты.
- Включайте необходимые звуковые подсказки или диалоги, чтобы аудио генерировалось в такт.
- Используйте краткую негативную подсказку, чтобы подавить артефакты, которые вы видите неоднократно.
- Размеры и длины
- Используйте размеры изображений вида 32k + 1 для ширины/высоты; граф автоматически корректирует, если вы ошиблись, но точные значения ускоряют итерацию.
- Количество кадров вида 8k + 1, как правило, наиболее устойчиво для планирования.
- Согласованность первого кадра
- Включайте первый кадр только когда вам нужна зафиксированная начальная композиция; сочетайте его с умеренной
image_strength, чтобы избежать излишнего ограничения.
- Включайте первый кадр только когда вам нужна зафиксированная начальная композиция; сочетайте его с умеренной
- VRAM и пропускная способность
- Рабочий процесс включает последовательные и компиляционные опции torch в патчере LTXVideo для многоядерных или ограниченных по памяти настроек. Держите их включенными для длинных клипов, выключайте при отладке поведения узлов. Расширение
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью признаем вклад и поддержку Lightricks за ComfyUI-LTXVideo. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Репозиторий ComfyUI-LTXVideo на GitHub: https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub: Lightricks/ComfyUI-LTXVideo
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
