
Hunyuan Video — это инновационная модель с открытым исходным кодом для создания видео, предлагающая производительность, сравнимую или даже превосходящую лучшие закрытые модели, разработанная компанией Tencent, ведущей технологической компанией. Hunyuan Video использует передовые технологии для обучения модели, такие как курирование данных, совместное обучение изображений и видео, а также эффективная инфраструктура для обучения и вывода моделей в большом масштабе. Hunyuan Video является крупнейшей моделью генерации видео с открытым исходным кодом, содержащей более 13 миллиардов параметров.
Основные особенности Hunyuan Video включают#
- Hunyuan Video предлагает унифицированную архитектуру для генерации как изображений, так и видео. Она использует специальный дизайн модели Transformer под названием "Dual-stream to Single-stream". Это означает, что модель сначала обрабатывает видео и текстовую информацию отдельно, а затем объединяет их для создания окончательного результата. Это помогает модели лучше понимать связь между визуальными элементами и текстовым описанием.
- Текстовый энкодер в Hunyuan Video основан на мультимодальной модели большого языка (MLLM). По сравнению с другими популярными текстовыми энкодерами, такими как CLIP и T5-XXL, MLLM лучше выравнивает текст с изображениями. Он также может предоставлять более детальные описания и рассуждения о содержании. Это помогает Hunyuan Video создавать видео, которые более точно соответствуют входному тексту.
- Для эффективной обработки видео с высоким разрешением и высокой частотой кадров Hunyuan Video использует 3D вариационный автокодер (VAE) с CausalConv3D. Этот компонент сжимает видео и изображения в более компактное представление, называемое латентным пространством. Работая в этом сжатом пространстве, Hunyuan Video может обучаться и генерировать видео в их оригинальном разрешении и частоте кадров без использования слишком больших вычислительных ресурсов.
- Hunyuan Video включает модель переписывания подсказок, которая может автоматически адаптировать вводимый пользователем текст для лучшего соответствия предпочтениям модели. Доступны два режима: Normal и Master. Режим Normal сосредоточен на улучшении понимания моделью инструкций пользователя, в то время как режим Master подчеркивает создание видео с более высоким визуальным качеством. Однако режим Master может иногда упускать некоторые детали текста в пользу улучшения визуального качества видео.
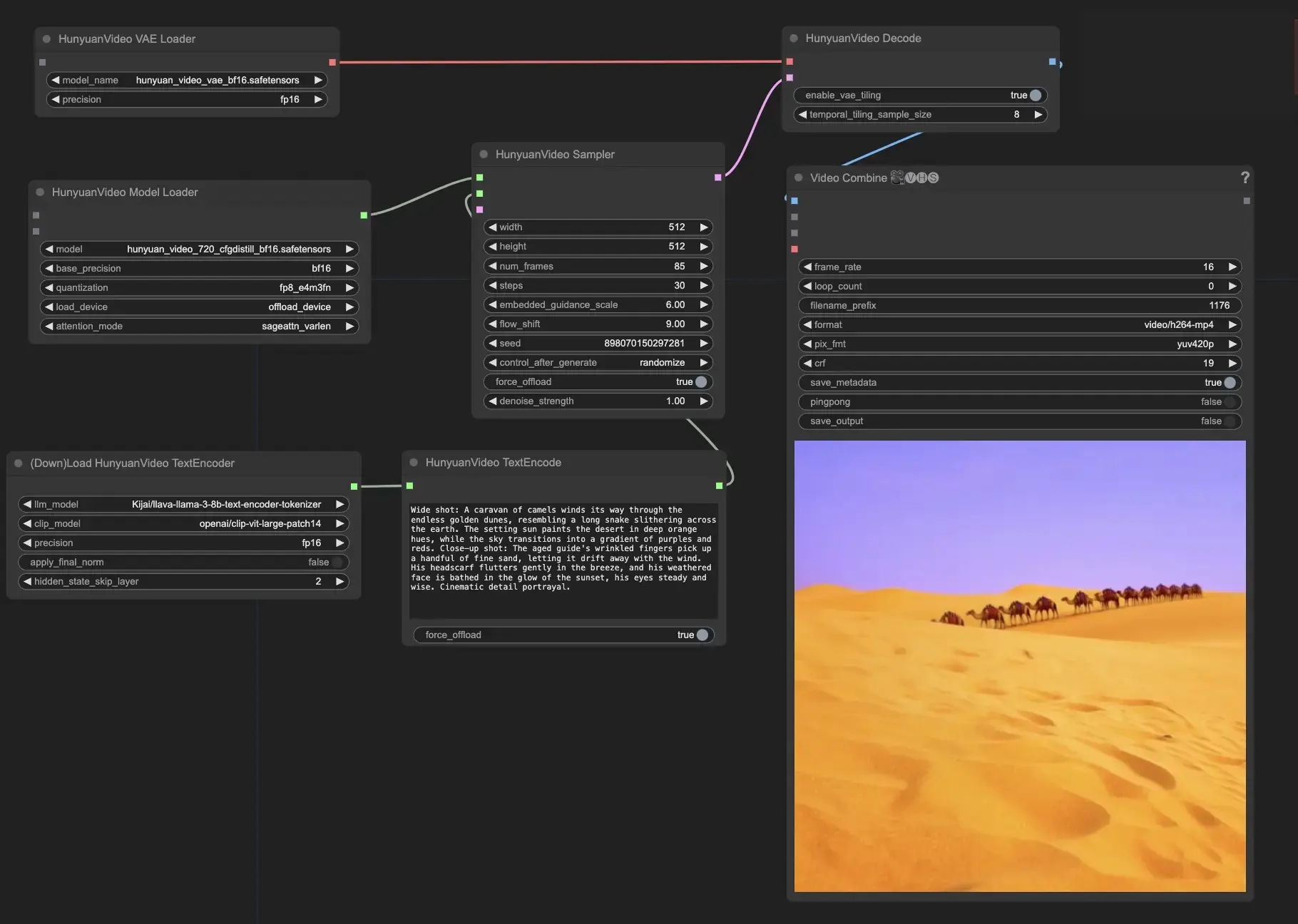
Используйте Hunyuan Video в ComfyUI#
Эти ComfyUI-HunyuanVideoWrapper узлы и связанные рабочие процессы были разработаны Kijai. Мы отдаем должное Kijai за эту инновационную работу. На платформе RunComfy мы просто представляем его вклад в сообщество.
- Укажите вашу текстовую подсказку: В узле HunyuanVideoTextEncode введите желаемую текстовую подсказку в поле "prompt". Здесь приведены некоторые примеры подсказок для вашего ознакомления.
- Настройте параметры выходного видео в узле HunyuanVideoSampler:
- Установите "width" и "height" на предпочитаемое разрешение
- Установите "num_frames" на желаемую длину видео в кадрах
- "steps" контролирует количество шагов денойзинга/семплирования (по умолчанию: 30)
- "embedded_guidance_scale" определяет силу направляющей подсказки (по умолчанию: 6.0)
- "flow_shift" влияет на длину видео (большие значения приводят к более коротким видео, по умолчанию: 9.0)