
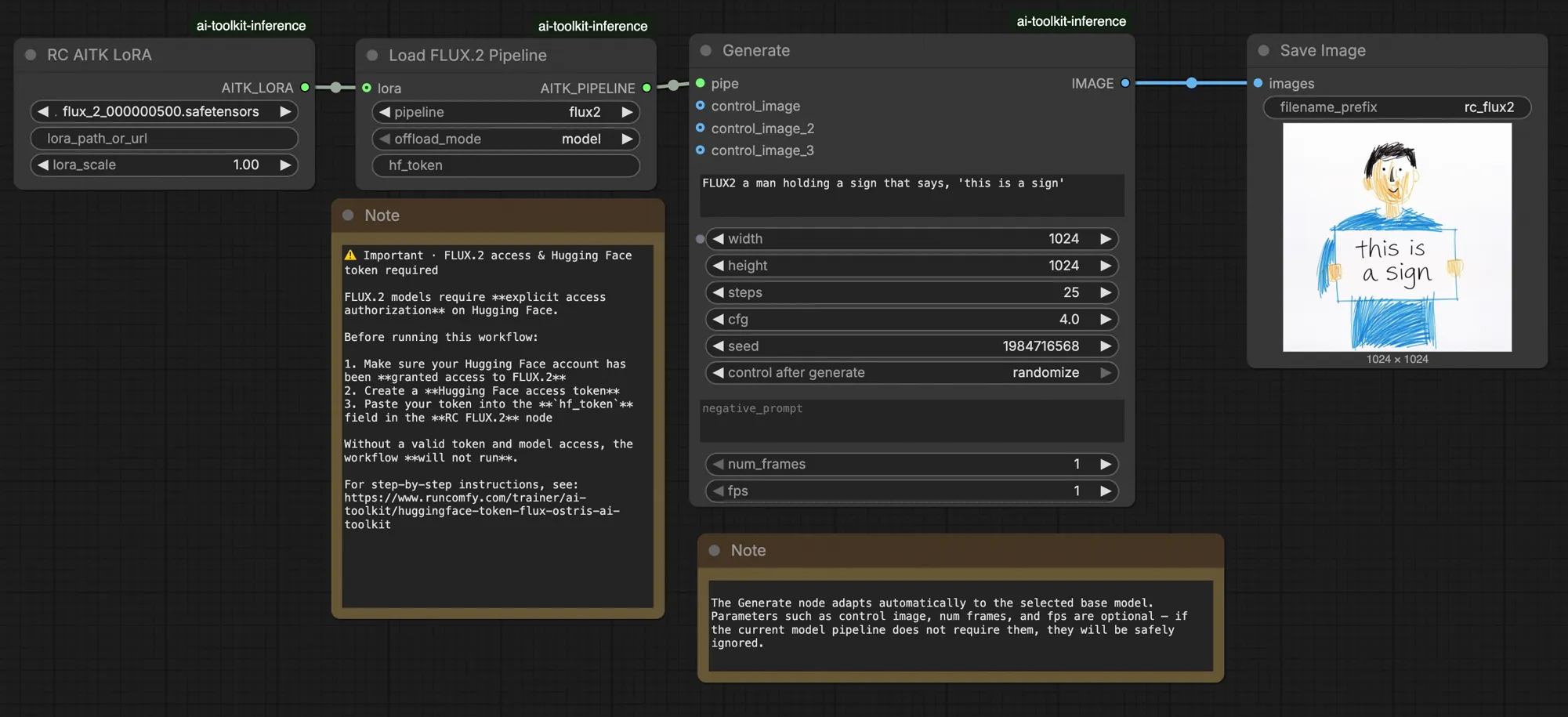
FLUX.2 LoRA ComfyUI Inference: вывод LoRA, соответствующий обучению AI Toolkit, с конвейером FLUX.2 Dev#
Этот готовый к производству рабочий процесс RunComfy выполняет вывод FLUX.2 Dev LoRA в ComfyUI через RC FLUX.2 Dev (Flux2Pipeline) (согласование на уровне конвейера, а не общий граф семплера). RunComfy создал и открыл этот пользовательский узел — смотрите репозитории runcomfy-com — и вы управляете применением адаптера с помощью lora_path и lora_scale.
Примечание: для выполнения этого рабочего процесса требуется машина 3XL.
Почему FLUX.2 LoRA ComfyUI Inference часто выглядит иначе в ComfyUI#
Предварительные просмотры обучения AI Toolkit рендерятся через специфический для модели конвейер FLUX.2, где кодирование текста, планирование и инъекция LoRA разработаны для совместной работы. В ComfyUI, перестройка FLUX.2 с другим графом (или другим путём загрузки LoRA) может изменить эти взаимодействия, так что копирование того же самого запроса, шагов, CFG и семени всё равно приводит к видимому дрейфу. Узлы конвейера RunComfy RC устраняют этот разрыв, выполняя FLUX.2 от начала до конца в Flux2Pipeline и применяя вашу LoRA внутри этого конвейера, поддерживая согласованность вывода с поведением предварительного просмотра. Источник: репозитории с открытым исходным кодом RunComfy.
Как использовать рабочий процесс FLUX.2 LoRA ComfyUI Inference#
Шаг 1: Получите путь LoRA и загрузите его в рабочий процесс (2 варианта)#
⚠️ Важно · Требуется доступ к FLUX.2 и токен Hugging Face#
Модели FLUX.2 Dev требуют явного разрешения на доступ на Hugging Face.
Перед запуском этого рабочего процесса:
- Убедитесь, что вашему аккаунту Hugging Face был предоставлен доступ к FLUX.2 (Dev)
- Создайте токен доступа Hugging Face
- Вставьте ваш токен в поле
hf_tokenна узле Load Pipeline
Без действительного токена и надлежащего доступа к модели рабочий процесс не будет выполнен. Для пошаговых инструкций смотрите токен Hugging Face для FLUX.2.
Вариант A — Результат обучения RunComfy → загрузить на локальный ComfyUI:
- Перейдите в Trainer → LoRA Assets
- Найдите LoRA, которую хотите использовать
- Нажмите ⋮ (три точки) в меню справа → выберите Копировать ссылку LoRA
- На странице рабочего процесса ComfyUI, вставьте скопированную ссылку в поле ввода Download в правом верхнем углу интерфейса
- Перед нажатием на Загрузить, убедитесь, что целевая папка установлена на ComfyUI > models > loras (эта папка должна быть выбрана в качестве цели загрузки)
- Нажмите Загрузить — это гарантирует, что файл LoRA сохранён в правильном каталоге
models/loras - После завершения загрузки обновите страницу
- Теперь LoRA появляется в выпадающем списке выбора LoRA в рабочем процессе — выберите её

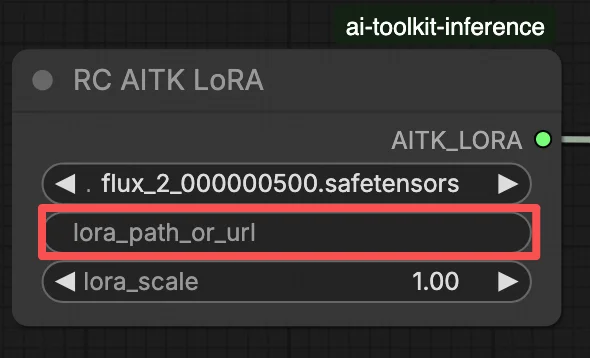
Вариант B — Прямая ссылка на LoRA (перекрывает Вариант A):
- Вставьте прямой URL загрузки
.safetensorsв поле вводаpath / urlузла LoRA - Когда URL предоставлен здесь, он перекрывает Вариант A — рабочий процесс загружает LoRA непосредственно из URL во время выполнения
- Локальная загрузка или размещение файлов не требуется
Совет: убедитесь, что URL ведёт к фактическому файлу .safetensors (а не на страницу приземления или перенаправления).
Шаг 2: Сопоставьте параметры вывода с настройками образцов обучения#
В узле LoRA выберите ваш адаптер в lora_path (Вариант A), или вставьте прямую ссылку .safetensors в path / url (Вариант B перекрывает выпадающий список). Затем установите lora_scale на ту же силу, которую вы использовали во время предварительных просмотров обучения и отрегулируйте оттуда.
Оставшиеся параметры находятся на узле Generate (и, в зависимости от графа, на узле Load Pipeline):
prompt: ваш текстовый запрос (включите триггерные слова, если вы обучали с ними)width/height: разрешение вывода; сопоставьте с размером предварительного просмотра обучения для наиболее чистого сравнения (рекомендуются кратные 16 для FLUX.2)sample_steps: количество шагов вывода (25 является обычным значением по умолчанию)guidance_scale: значение CFG/направления (4.0 является обычным значением по умолчанию)seed: фиксированное семя для воспроизведения; измените его для исследования вариацийseed_mode(только если присутствует): выберитеfixedилиrandomizenegative_prompt(только если присутствует): FLUX.2 в этом рабочем процессе дистиллирован по направлению, поэтому отрицательные запросы игнорируютсяhf_token: токен доступа Hugging Face; необходим для загрузки модели FLUX.2 Dev (вставьте его на узле Load Pipeline)
Совет по согласованию обучения: если вы настраивали значения семплирования во время обучения (seed, guidance_scale, sample_steps, триггерные слова, разрешение), отразите эти значения здесь. Если вы обучали на RunComfy, откройте Trainer → LoRA Assets > Config, чтобы просмотреть разрешённый YAML и скопировать настройки предварительного просмотра/образца в узлы рабочего процесса.

Шаг 3: Запуск FLUX.2 LoRA ComfyUI Inference#
Нажмите Queue/Run — узел SaveImage записывает результаты в вашу выходную папку ComfyUI.
Быстрый список проверок:
- ✓ LoRA либо: загружена в
ComfyUI/models/loras(Вариант A), либо загружена через прямой URL.safetensors(Вариант B) - ✓ Страница обновлена после локальной загрузки (только Вариант A)
- ✓ Параметры вывода соответствуют конфигурации
sampleобучения (если настроено)
Если всё вышеуказанное корректно, результаты вывода здесь должны почти соответствовать вашим предварительным просмотрам обучения.
Устранение неполадок FLUX.2 LoRA ComfyUI Inference#
Большинство расхождений между "предварительным просмотром обучения и выводом ComfyUI" FLUX.2 вызваны различиями на уровне конвейера (как модель загружена, планируется и как LoRA объединяется), а не одной неправильной настройкой. Этот рабочий процесс RunComfy восстанавливает наиболее близкий "базовый уровень, соответствующий обучению", выполняя вывод через RC FLUX.2 Dev (Flux2Pipeline) от начала до конца и применяя вашу LoRA внутри этого конвейера через lora_path / lora_scale (вместо наложения общих узлов загрузчика/семплера).
(1) Flux.2 с ошибкой Lora: "mul_cuda" не реализован для 'Float8_e4m3fn'#
Почему это происходит Это обычно происходит, когда FLUX.2 загружается с весами Float8/FP8 (или с квантованием смешанной точности), а LoRA применяется через общий путь LoRA ComfyUI. Объединение LoRA может вызвать неподдерживаемые операции Float8 (или смешанные повышения Float8 + BF16), что вызывает ошибку времени выполнения mul_cuda Float8.
Как исправить (рекомендуется)
- Выполните вывод через RC FLUX.2 Dev (Flux2Pipeline) и загружайте адаптер только через
lora_path/lora_scale, чтобы объединение LoRA происходило в согласованном с AI Toolkit конвейере, а не через общий загрузчик LoRA, наложенный сверху. - Если вы отлаживаете в не-RC графе: избегайте применения LoRA поверх весов диффузии Float8/FP8. Используйте путь загрузки, совместимый с BF16/FP16 для FLUX.2 перед добавлением LoRA.
(2) Несоответствия формы LoRA должны быстро завершаться, вместо того чтобы повреждать состояние GPU и вызывать OOM/нестабильность системы#
Почему это происходит Это почти всегда несоответствие базы: LoRA была обучена для другой семейства моделей (например, FLUX.1), но применяется к FLUX.2 Dev. Вы часто увидите множество строк lora key not loaded и затем несоответствия формы; в худшем случае сессия может стать нестабильной и закончиться OOM.
Как исправить (рекомендуется)
- Убедитесь, что LoRA была обучена специально для
black-forest-labs/FLUX.2-devс AI Toolkit (варианты FLUX.1 / FLUX.2 / Klein не взаимозаменяемы). - Держите граф "однопутевым" для LoRA: загружайте адаптер только через вход
lora_pathрабочего процесса и дайте Flux2Pipeline обработать объединение. Не накладывайте дополнительный общий загрузчик LoRA параллельно. - Если вы уже столкнулись с несоответствием и ComfyUI начинает производить несвязанные ошибки CUDA/OOM после этого, перезапустите процесс ComfyUI, чтобы полностью сбросить состояние GPU + модели, затем повторите попытку с совместимой LoRA.
(3) Flux.2 Dev - Использование LoRAs более чем удваивает время вывода#
Почему это происходит LoRA может значительно замедлить FLUX.2 Dev, когда путь LoRA вызывает дополнительную работу по патчингу/деквантованию или применяет веса в более медленном пути кода, чем базовая модель в одиночку.
Как исправить (рекомендуется)
- Используйте путь RC FLUX.2 Dev (Flux2Pipeline) этого рабочего процесса и передайте ваш адаптер через
lora_path/lora_scale. В этой настройке LoRA объединяется один раз во время загрузки конвейера (в стиле AI Toolkit), так что стоимость семплирования на шаг остаётся близкой к базовой модели. - Когда вы стремитесь к поведению, соответствующему предварительному просмотру, избегайте наложения нескольких загрузчиков LoRA или смешивания путей загрузки. Держите это на одном
lora_path+ одномlora_scale, пока базовый уровень не совпадёт.
Примечание В этом рабочем процессе FLUX.2 Dev, FLUX.2 дистиллирован по направлению, поэтому negative_prompt может игнорироваться конвейером, даже если поле UI существует — сначала сопоставьте предварительные просмотры, используя формулировку запроса + guidance_scale + lora_scale.
Запустите FLUX.2 LoRA ComfyUI Inference сейчас#
Откройте рабочий процесс, установите lora_path и нажмите Queue/Run, чтобы получить результаты FLUX.2 Dev LoRA, которые остаются близкими к вашим предварительным просмотрам обучения AI Toolkit.