
Управляемая анимация в AI Video: WanVideo + TTM Motion Control Workflow для ComfyUI#
Этот рабочий процесс от mickmumpitz приносит управляемую анимацию в AI Video в ComfyUI с использованием подхода, не требующего обучения и направленного движением. Он сочетает диффузию изображения в видео WanVideo с латентным управлением Time-to-Move (TTM) и масками, осведомленными о регионе, чтобы вы могли направлять, как объекты движутся, сохраняя идентичность, текстуру и непрерывность сцены.
Вы можете начать с видеопластины или с двух ключевых кадров, добавить маски региона, которые фокусируют движение там, где вы желаете, и управлять траекториями без какой-либо тонкой настройки. Результатом является точная, повторяемая управляемая анимация в AI Video, подходящая для направленных кадров, последовательности движения объектов и творческих пользовательских правок.
Ключевые модели в рабочем процессе Comfyui Управляемая анимация в AI Video#
- Wan2.2 I2V A14B (HIGH/LOW). Основная модель диффузии изображения в видео, которая синтезирует движение и временную согласованность из подсказок и визуальных ссылок. Две вариации балансируют четкость (HIGH) и маневренность (LOW) для различных интенсивностей движения. Файлы модели размещены в сообществе WanVideo на Hugging Face, например, в дистрибуциях Kijai’s WanVideo. Ссылки: Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA. Легкий адаптер, который улучшает структуру и согласованность движения при составлении управляемой анимации в AI Video с Wan2.2. Он помогает сохранить геометрию объекта при более сильных подсказках движения. Ссылка: Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE. Видеоавтокодировщик, используемый для кодирования кадров в латенты и декодирования выходов сэмплера обратно в изображения без потери деталей. Ссылка: Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- UMT5-XXL текстовый кодировщик. Обеспечивает богатые текстовые встраивания для управления на основе подсказок наряду с подсказками движения. Ссылки: google/umt5-xxl, Kijai/WanVideo_comfy – encoder weights
- Модели "Segment Anything" для видеомасок. SAM3 и SAM2 создают и распространяют маски региона по кадрам, обеспечивая зависимое от региона руководство, которое улучшает управляемую анимацию в AI Video там, где это важно. Ссылки: facebook/sam3, facebook/sam2
- Qwen-Image-Edit 2509 (опционально). Фундамент для редактирования изображений и легкий LoRA для быстрой очистки начального/конечного кадра или удаления объектов перед анимацией. Ссылки: QuantStack/Qwen-Image-Edit-2509-GGUF, lightx2v/Qwen-Image-Lightning, Comfy-Org/Qwen-Image_ComfyUI
- Руководство Time-to-Move (TTM). Рабочий процесс интегрирует латенты TTM для внедрения управления траекторией без обучения для управляемой анимации в AI Video. Ссылка: time-to-move/TTM
Как использовать рабочий процесс Comfyui Управляемая анимация в AI Video#
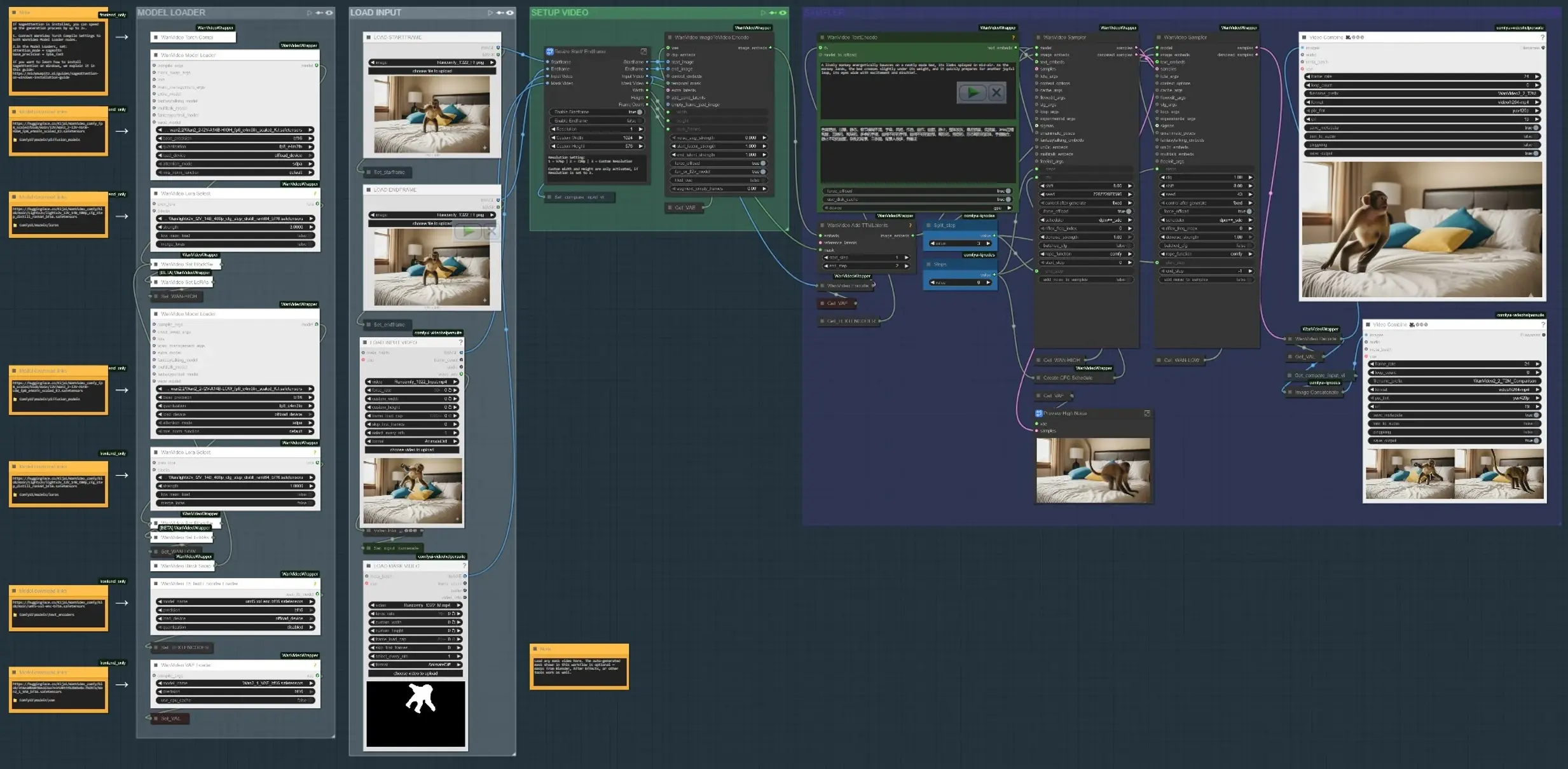
Рабочий процесс выполняется в четырех основных этапах: загрузка входных данных, определение, где должно происходить движение, кодирование текстовых и движущих подсказок, затем синтез и предварительный просмотр результата. Каждая группа ниже соответствует обозначенному разделу на графике.
- ЗАГРУЗКА ВХОДНЫХ ДАННЫХ Используйте группу "ЗАГРУЗКА ВХОДНОГО ВИДЕО", чтобы добавить пластину или эталонный клип, или загрузите начальные и конечные ключевые кадры, если вы создаете движение между двумя состояниями. Подграф "Изменение размера начального/конечного кадра" нормализует размеры и, по желанию, включает блокировку начального и конечного кадра. Сравнитель "бок о бок" создает выход, который показывает вход по сравнению с результатом для быстрого обзора (
VHS_VideoCombine(#613)). - ЗАГРУЗКА МОДЕЛИ Группа "ЗАГРУЗКА МОДЕЛИ" настраивает Wan2.2 I2V (HIGH/LOW) и применяет Lightx2v LoRA. Путь смены блока смешивает варианты для хорошего баланса между четкостью и движением перед сэмплированием. Wan VAE загружается один раз и делится между кодированием/декодированием. Кодирование текста использует UMT5-XXL для сильного управления подсказками в управляемой анимации в AI Video.
- SAM3/SAM2 МАСКА ОБЪЕКТА В "SAM3 МАСКА ОБЪЕКТА" или "SAM2 МАСКА ОБЪЕКТА" кликните по эталонному кадру, добавьте положительные и отрицательные точки, и распространяйте маски по клипу. Это дает временно согласованные маски, которые ограничивают редактирование движения до выбранного вами объекта или региона, что позволяет зависимое от региона руководство. Вы также можете обойти и загрузить свое собственное видео с маской; маски из Blender/After Effects работают нормально, когда вам нужно управление, нарисованное художником.
- ПОДГОТОВКА НАЧАЛЬНОГО/КОНЕЧНОГО КАДРА (опционально) Группы "НАЧАЛЬНЫЙ КАДР – УДАЛЕНИЕ QWEN" и "КОНЕЧНЫЙ КАДР – УДАЛЕНИЕ QWEN" предоставляют опциональный проход очистки на конкретных кадрах с использованием Qwen-Image-Edit. Используйте их для удаления каркасов, палочек или артефактов пластины, которые иначе загрязняли бы подсказки движения. Маскирование обрезает и сшивает правку обратно в полный кадр для чистой основы.
- КОДИРОВАНИЕ ТЕКСТА + ДВИЖЕНИЯ Подсказки кодируются с помощью UMT5-XXL в
WanVideoTextEncode(#605). Изображения начального/конечного кадра преобразуются в видеолатенты вWanVideoImageToVideoEncode(#89). Латенты движения TTM и опциональная временная маска сливаются черезWanVideoAddTTMLatents(#104), чтобы сэмплер получал как семантические (текстовые), так и траекторные подсказки, что является центральным для управляемой анимации в AI Video. - СЭМПЛЕР И ПРЕДПРОСМОТР Сэмплер Wan (
WanVideoSampler(#27) иWanVideoSampler(#90)) снижает шум латентов, используя двухчасовую настройку: один путь управляет глобальной динамикой, в то время как другой сохраняет локальное появление. Шаги и настраиваемый график CFG формируют интенсивность движения по сравнению с четкостью. Результат декодируется в кадры и сохраняется как видео; выход сравнения помогает оценить, соответствует ли ваша управляемая анимация в AI Video заданию.
Ключевые узлы в рабочем процессе Comfyui Управляемая анимация в AI Video#
WanVideoImageToVideoEncode(#89) Кодирует изображения начального/конечного кадра в видеолатенты, которые являются основой для синтеза движения. Настраивайте только при изменении базового разрешения или количества кадров; держите их в соответствии с вашим входом, чтобы избежать растяжения. Если вы используете видео с маской, убедитесь, что его размеры соответствуют размеру закодированного латента.WanVideoAddTTMLatents(#104) Объединяет латенты движения TTM и временные маски в поток управления. Переключите вход маски, чтобы ограничить движение вашим объектом; оставляя его пустым, применяется движение глобально. Используйте это, когда вы хотите траекторно-специфическую управляемую анимацию в AI Video без влияния на фон.SAM3VideoSegmentation(#687) Соберите несколько положительных и отрицательных точек, выберите кадр трека, затем распространяйте по клипу. Используйте визуализацию для проверки дрейфа маски перед сэмплированием. Для конфиденциальных или автономных рабочих процессов переключитесь на группу SAM2, которая не требует модели.WanVideoSampler(#27) Деноизер, который балансирует движение и идентичность. Соедините "Шаги" со списком графика CFG, чтобы усилить или ослабить силу движения; чрезмерная сила может затмить внешний вид, в то время как слишком малая не обеспечивает движение. Когда маски активны, сэмплер концентрирует обновления внутри региона, улучшая стабильность для управляемой анимации в AI Video.
Опциональные дополнения#
- Для быстрых итераций начните с модели LOW Wan2.2, настройте движение с TTM, затем переключитесь на HIGH для финального прохода, чтобы восстановить текстуру.
- Используйте видео с масками, нарисованные художниками, для сложных силуэтов; загрузчик принимает внешние маски и изменит их размер для соответствия.
- Переключатели "начальный/конечный кадр" позволяют визуально закрепить первый или последний кадр, полезно для бесшовных переходов в более длительных редакциях.
- Если в вашей среде доступно, включение оптимизированного внимания (например, SageAttention) может значительно ускорить сэмплирование.
- Соответствуйте частоту кадров вывода источнику в узле комбинирования, чтобы избежать восприятия временных различий в управляемой анимации в AI Video.
Этот рабочий процесс обеспечивает управление движением, не требующее обучения и осведомленное о регионе, комбинируя текстовые подсказки, латенты TTM и надежную сегментацию. С несколькими целевыми входами вы можете управлять нюансированной, готовой к производству управляемой анимацией в AI Video, сохраняя объекты в модели и сцены согласованными.
Благодарности#
Этот рабочий процесс реализует и расширяет следующие работы и ресурсы. Мы искренне благодарим Mickmumpitz, который является создателем управляемой анимации в AI Video для учебного пособия/поста, и команду time-to-move за TTM за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Patreon/Управляемая анимация в AI Video
- Документы / Примечания к выпуску: Mickmumpitz Patreon post
- time-to-move/TTM
- GitHub: time-to-move/TTM
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
