






Виртуальная примерка в ComfyUI с Qwen Image Edit#
Этот рабочий процесс виртуальной примерки создает реалистичные визуальные образы человека, одетого в выбранную одежду, комбинируя фотографию объекта с одним или несколькими изображениями одежды. Он предназначен для модной индустрии, электронной коммерции и команд контента, которым нужны быстрые предварительные просмотры нарядов без ручного композитинга или фотосессий. Результат — чистый, хорошо сидящий рендер, который учитывает форму тела, позу, освещение и характеристики ткани.
Внутри, график условно задает Qwen Image Edit как вашими изображениями, так и естественным языковым запросом, затем направляет редактирование в сторону передачи одежды. Вы предоставляете изображение человека и до трёх изображений одежды; рабочий процесс размещает их в одной справочной панели и выполняет редактирование изображения, надежно размещая выбранную одежду на объекте. Встроенный выход "бок о бок" облегчает инспекцию и итерации.
Ключевые модели в рабочем процессе виртуальной примерки Comfyui#
- Qwen-Image-Edit. Основная модель диффузного редактирования, поддерживающая как семантические, так и внешние правки, позволяющая обмен одежды, который соответствует позе тела и освещению, сохраняя идентичность. Model card
- Qwen2.5-VL 7B. Энкодер визуального языка, используемый для следования инструкциям и визуального понимания, который помогает модели интерпретировать ваш запрос и справочную панель. Model card
- Qwen Image VAE. Вариационный автокодировщик, используемый для кодирования и декодирования латентов изображения, согласованный с семейством Qwen Image для стабильных результатов. Assets
- Virtual Try-On LoRA. Легкий адаптер, специализированный для передачи одежды, который улучшает размещение и динамику посадки одежды. Он смещает редактирование в сторону применения одежды, сохраняя объект.
Как использовать рабочий процесс виртуальной примерки Comfyui#
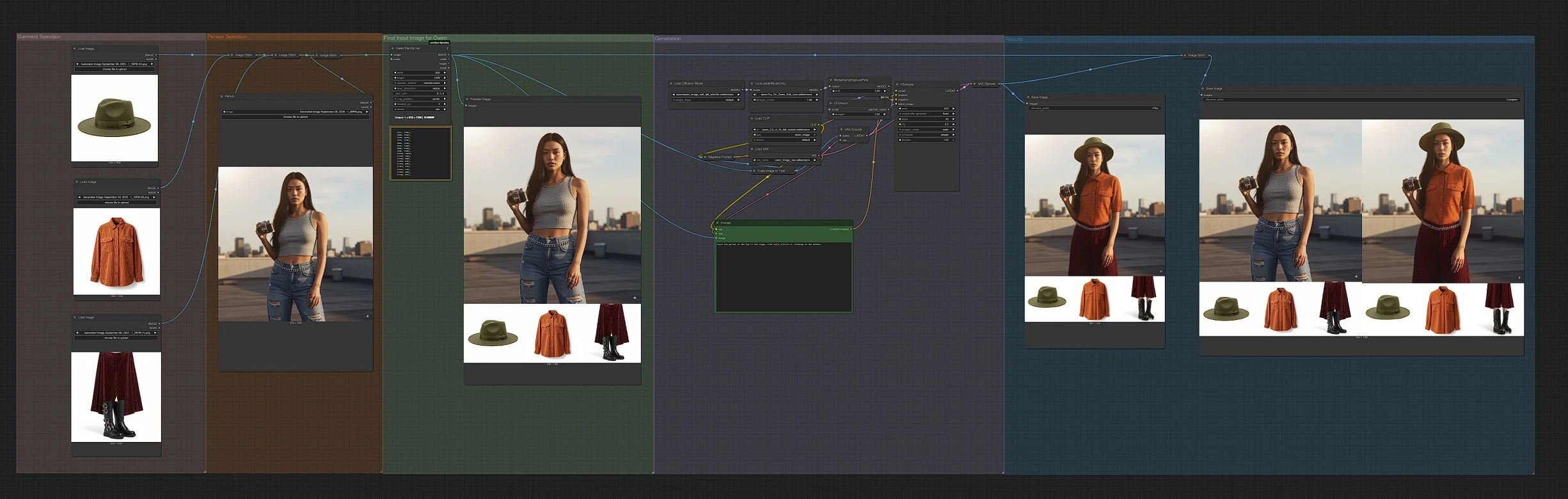
Взгляд на рабочий процесс: он размещает ваши входные данные в едином изображении, где человек находится наверху, а одежда появляется снизу, затем кодирует эту панель и запускает Qwen Image Edit для получения результата примерки. Группы работают последовательно слева направо: Выбор одежды, Выбор человека, Финальное входное изображение для Qwen, Генерация и Результаты.
Выбор одежды#
Загрузите до трех фотографий продуктов в узлы LoadImage одежды (LoadImage (#175), LoadImage (#177), LoadImage (#179)). Рабочий процесс компилирует их с помощью ImageStitch (#280) и ImageStitch (#282) для формирования чистой полосы одежды. Фотографии продуктов с фронтальным видом и чистым фоном работают лучше всего и делают виртуальную примерку более надежной. Используйте одну или несколько одежд, чтобы позволить запросу выбрать, и сохраняйте масштаб постоянным между изображениями.
Выбор человека#
Добавьте фотографию вашего объекта в LoadImage (#170). График складывает изображение человека над полосой одежды, используя ImageStitch (#284), чтобы макет соответствовал инструкции по умолчанию. Центрированный фронтальный вид с четким освещением повышает реализм. Стремитесь к совместимой позе с одеждой, которую вы хотите примерить.
Финальное входное изображение для Qwen#
Составная панель стандартизирована с Qwen friendly res (ImageResizeKJv2 (#196)) до разрешения, предпочтительного для моделей Qwen Image, и опционально масштабируется через ImageScaleToTotalPixels (#115) для скорости или детализации. PreviewImage (#240) показывает, что именно увидит модель. Используйте Prompt (TextEncodeQwenImageEdit (#121)), чтобы описать наряд, который вы хотите на человеке, например: "Стилизуйте человека в верхней части изображения, используя показанные ниже жакет и рубашку". При необходимости добавьте ограничения в Negative Prompt (TextEncodeQwenImageEdit (#114)), чтобы избежать артефактов, таких как лишние рукава или несовпадающие узоры.
Генерация#
Диффузионная основа загружает Qwen-Image-Edit и применяет try-on LoRA, используя LoraLoaderModelOnly (#233), затем запускает сэмплер KSampler (#122) для выполнения редактирования. Модель получает два согласованных сигнала: визуальную семантику от панели и запроса, и внешний вид от закодированных латентов изображения, дизайн, который Qwen Image Edit использует для балансировки идентичности и достоверности. Это производит реалистичный рендер виртуальной примерки, который соответствует позе и освещению объекта.
Результаты#
VAEDecode (#119) преобразует латент в изображение, которое сохраняется как основной выход виртуальной примерки с помощью SaveImage (#116). Для быстрой оценки ImageStitch (#250) создает панель "Сравнить" с видом ввода модели и окончательным результатом, затем SaveImage (#251) записывает его на диск. Используйте вид сравнения, чтобы уточнить запросы, обменять одежду или изменить входные данные, пока посадка не будет выглядеть правильно.
Ключевые узлы в рабочем процессе виртуальной примерки Comfyui#
Prompt (#121)#
Создает условие, которое говорит Qwen Image Edit, как одеть объект, используя показанную ниже одежду. Пишите четкие инструкции, которые ссылаются на положение и тип одежды, например "Наденьте черный пиджак и белую футболку на человека, оставьте украшения и волосы без изменений". Если предоставлено несколько предметов одежды, вы можете указать, какие использовать, или позволить модели выбрать. Небольшие изменения формулировок могут улучшить согласованность и уменьшить чрезмерное редактирование.
Negative Prompt (#114)#
Предоставляет ограничивающие условия, чтобы избежать нежелательных правок. Добавьте краткие термины, такие как "нет лишних рукавов, нет изменений логотипа, без изменения фона", чтобы сохранить контекст сцены и детали продукта. Используйте это, когда вы видите артефакты, такие как дублированные воротники, искаженные узоры или непреднамеренные изменения цвета.
Qwen friendly res (#196)#
Унифицирует составную панель до Qwen-дружественных размеров для стабильной геометрии и лучшего выравнивания одежды. Выберите аспект, который соответствует кадрированию вашего объекта, и оставьте место для полосы одежды снизу. Если вы измените ориентацию, обновите запрос, чтобы он все еще описывал "человек сверху, одежда снизу".
LoraLoaderModelOnly (#233)#
Применяет Virtual Try-On LoRA, который усиливает поведение передачи одежды. Если результаты выглядят чрезмерно стилизованными или идентичность смещается, уменьшите вес LoRA. Если одежда не передается уверенно, увеличьте его немного. Перезапустите с тем же семенем, чтобы надежно сравнить изменения.
KSampler (#122)#
Контролирует детализацию и соблюдение ваших инструкций. Увеличьте шаги умеренно для большей достоверности или уменьшите их для более быстрых предварительных просмотрев. Настройте шкалу руководства, если редактирование слишком слабое или слишком агрессивное, и установите фиксированное семя, когда хотите воспроизводимые результаты виртуальной примерки.
Дополнительные возможности#
- Пишите запросы, которые отражают макет: "Стилизуйте человека в верхней части изображения с одеждой, показанной внизу".
- Фотографии продуктов с чистым фоном и фронтальным видом наиболее надежно переносятся в виртуальной примерке.
- Рекомендуемые размеры, дружелюбные к Qwen, которые хорошо работают: 832 x 1248, 1024 x 1024, 1248 x 832, 944 x 1104, 1184 x 880, 1328 x 800.
- Для более быстрых предварительных просмотров уменьшите общее количество пикселей в
ImageScaleToTotalPixels(#115), затем увеличьте его для вашего финального прохода. - Если посадка близка, но текстуры не совпадают, попробуйте небольшое изменение в запросе, например "убедитесь, что рукава совпадают с руками" или "сохраните естественное драпирование ткани".
- Для сохранения фона добавьте отрицательные условия, такие как "не изменять фон" и избегайте терминов стиля, которые подразумевают изменение сцены.
Полезные ссылки о базовых моделях:
- Qwen-Image-Edit модельная карта: Hugging Face
- Qwen2.5-VL 7B модельная карта: Hugging Face
- Активы Qwen Image для ComfyUI: Hugging Face
- Обзор проекта Qwen Image: GitHub
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы выражаем благодарность @BenjisAIPlayground из Virtual Try-On Demo за демонстрационный рабочий процесс. Для получения авторитетной информации, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- YouTube/Virtual Try-On Demo
- Документы / Примечания к выпуску @BenjisAIPlayground: Virtual Try-On Demo
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими организациями.





