
ComfyUI F5 TTS: клонирование голоса и преобразование текста в речь в одном рабочем процессе#
Этот рабочий процесс ComfyUI F5 TTS позволяет генерировать естественную речь из текста и клонировать голоса непосредственно в ComfyUI. Он поддерживается пользовательскими узлами ComfyUI-F5-TTS и включает полный путь для клонирования на основе ссылок: предоставьте короткий WAV плюс соответствующую расшифровку, чтобы настроить модель, затем синтезируйте новые строки, которые следуют тембру и стилю референтного говорящего. Граф также содержит готовые тесты для нескольких вариантов моделей, языков и вокодеров, чтобы вы могли быстро сравнить результаты и решить, что лучше всего подходит для повествования, озвучки, диалогов персонажей или демонстраций продуктов.
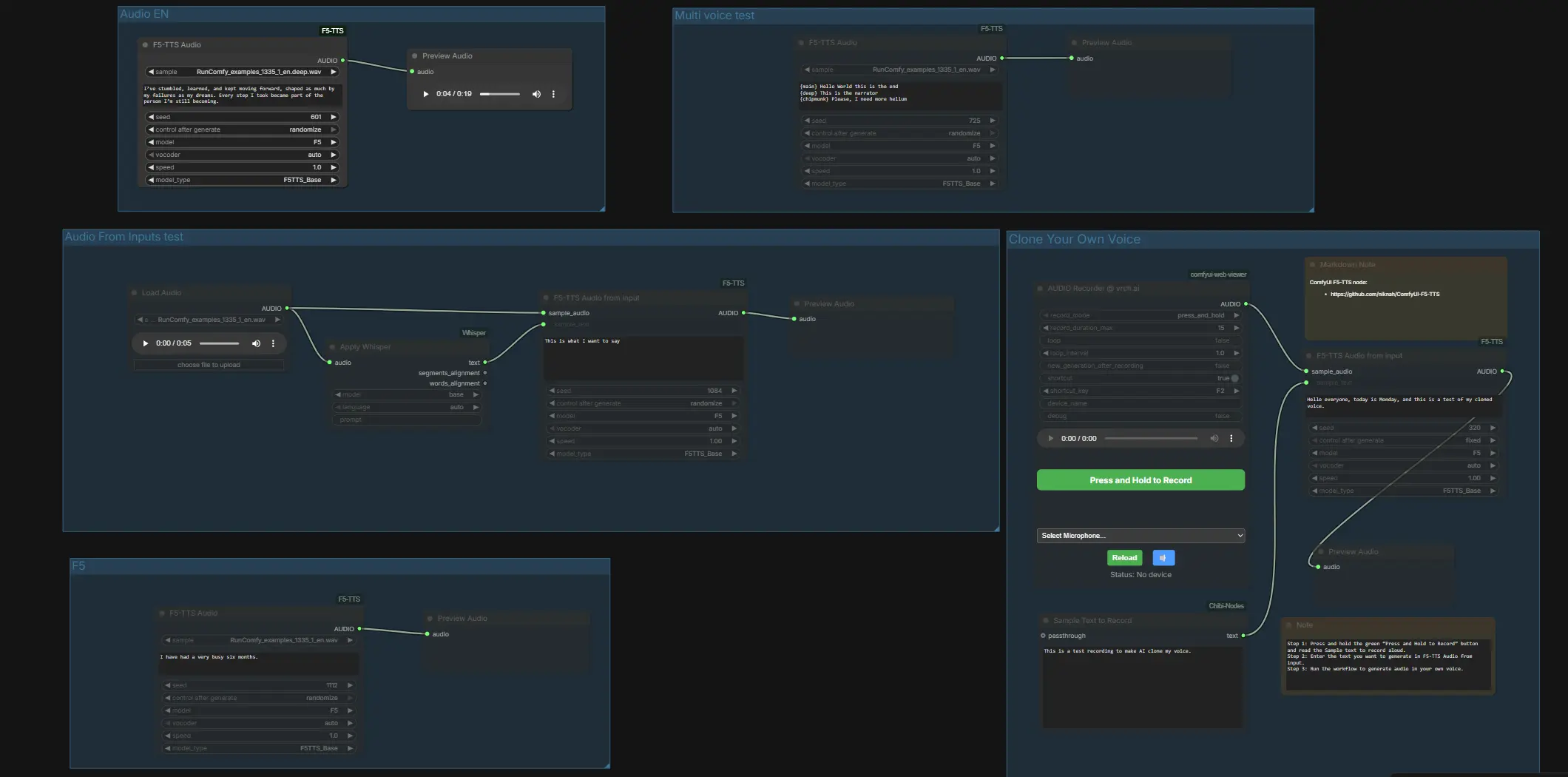
Все организовано в четкие группы, чтобы вы могли использовать ComfyUI F5 TTS двумя способами: быстрое преобразование текста в речь одним нажатием на английском, французском, немецком и японском языках или клонирование голосов через встроенный рекордер или парные файлы. Включен компактный путь транскрипции Whisper, чтобы помочь вам получить точную расшифровку образца, если у вас уже есть чистая запись.
Ключевые модели в рабочем процессе ComfyUI F5 TTS#
- Fish Audio F5-TTS. Преобразование текста в речь без предварительного обучения, изучающее характеристики говорящего из короткой ссылки и производящее высококачественную речь на нескольких языках. Подробности о модели и обучении смотрите в проекте. GitHub
- OpenAI Whisper. Распознавание речи, используемое здесь для автоматической транскрипции вашего референсного клипа, чтобы текст образца точно соответствовал, что улучшает качество клонирования. GitHub
- BigVGAN. Высококачественный нейронный вокодер, доступный в качестве опции декодирования для более четкого, кристального вывода. GitHub
- Vocos. Быстрая, легковесная альтернатива нейронному вокодеру, ориентированная на скорость и низкую задержку. GitHub
- ComfyUI-F5-TTS custom nodes. Интеграция ComfyUI, которая подключает F5-TTS и совместимые бэкенды к узлам, используемым в этом графе. GitHub
Как использовать рабочий процесс ComfyUI F5 TTS#
На высоком уровне рабочий процесс предлагает независимые группы для быстрых сравнений моделей и выделенный канал клонирования. Начните с прослушивания предварительно настроенных групп, чтобы подтвердить предпочтительный голос и вокодер, затем переходите к клонированию с вашим собственным образцом. Каждая подгруппа ниже объясняет, что делает группа и какие немногие входы имеют значение.
Тест аудио из входных данных#
Этот канал демонстрирует транскрипцию ссылок плюс настройку. LoadAudio (#4) загружает WAV, Apply Whisper (#13) транскрибирует его, и F5TTSAudioInputs (#26) использует как образец аудио, так и текст Whisper для настройки голоса перед предварительным просмотром. Предоставьте чистый, произнесенный образец и позвольте Whisper заполнить порт транскрипта, чтобы пара точно совпадала. Если вы хотите предоставить файлы напрямую, поместите парный .wav и .txt с одним и тем же именем файла в папку ComfyUI/input, затем перезапустите ComfyUI, чтобы граф мог их увидеть.
Тест нескольких голосов#
Эта группа показывает стилистическое переключение в одной строке, используя один узел синтеза. F5TTSAudio (#17) читает сценарий с помеченными сегментами, чтобы вы могли прослушать несколько стилей персонажей или изменения акцентов в одном проходе. Это быстрый способ услышать, как ComfyUI F5 TTS справляется с контрастными тембрами или темпами повествования по сравнению с персонажем.
Аудио EN#
Используйте F5TTSAudio (#15) для простого преобразования текста в речь на английском языке. Введите ваш сценарий и прослушайте, чтобы оценить базовое произношение и темп с настройками по умолчанию F5. Этот канал идеален для быстрой итерации перед тем, как вы решите клонировать или смешивать несколько голосов.
F5v1#
Этот путь запускает узел F5TTSAudio (#33) против варианта F5 v1, чтобы вы могли сравнить тон и просодию с основной настройкой F5. Используйте тот же текст, что и в канале EN, чтобы различия было легко оценить. Это полезно при выборе модели по умолчанию для более длительного проекта.
Аудио FR#
Этот канал нацелен на синтез на французском языке с использованием F5TTSAudio (#27), настроенного для французского пресета. Предоставьте французский сценарий и прослушайте выходные данные, чтобы проверить носовые гласные и обработку связок. Переключайтесь между каналами EN и FR, чтобы сравнить четкость и скорость.
Аудио DE bigvgan#
Здесь F5TTSAudio (#30) использует немецкий пресет и вокодер BigVGAN для более яркого, кристального декодирования. Используйте этот канал, когда вы хотите больше присутствия или студийного блеска. Если вы предпочитаете более мягкую интерпретацию, сравните с каналом Vocos.
Аудио JP#
Этот путь использует F5TTSAudio (#25) с японским пресетом. Вставьте японский сценарий, чтобы оценить акцент и временные параметры мора. Это хорошая отправная точка для аниме-стилей или продуктовых линий, предназначенных для японской аудитории.
Тест E2#
Эта группа использует F5TTSAudio (#29) с совместимым пресетом E2 и вокодером Vocos для прослушивания альтернативного бэкенда. Используйте его, чтобы сравнить задержку и характеристики тембра с вашими запусками F5.
Клонируйте ваш собственный голос#
Записывайте, соединяйте и клонируйте напрямую в ComfyUI. Нажмите на микрофон в VrchAudioRecorderNode (#43) и прочитайте подсказку, отображаемую в поле "Sample Text to Record" Textbox (#42). Рекордер направляет ваш WAV в F5TTSAudioInputs (#44) вместе с точным текстом, который вы произнесли, что настраивает модель на ваш тембр и стиль перед предварительным просмотром в PreviewAudio (#45). Для получения наилучших результатов говорите в тихой комнате и убедитесь, что текст ссылки точно соответствует тому, что вы сказали дословно; затем введите любые новые строки, которые вы хотите, чтобы клонированный голос произнес, и запустите граф.
Ключевые узлы в рабочем процессе ComfyUI F5 TTS#
F5TTSAudio (#15)#
Основной узел для преобразования текста в речь в один проход, используемый в группах EN, FR, DE, JP, F5v1 и E2. Предоставьте ваш сценарий и выберите модельный пресет и вокодер, которые подходят вашему языку и подаче. Если вы хотите воспроизводимые дубли, держите семя фиксированным; если хотите разнообразия, рандомизируйте между запусками. Реализация предоставлена расширением ComfyUI-F5-TTS. GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
Точка входа для клонирования, которая использует референсный WAV и его соответствующую расшифровку для создания представления говорящего, а затем синтезирует новые строки в этом голосе. Используйте чистый образец с постоянной громкостью и убедитесь, что расшифровка точна, чтобы максимизировать сходство и уменьшить артефакты. Переключайте пресеты моделей или вокодеры здесь, если вам нужен более яркий или более нейтральный декод. GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
Автоматическая транскрипция для вашего референсного образца. Выберите размер Whisper, который балансирует скорость и точность для вашего оборудования и языка, затем передайте его выходной текст в узел клонирования, чтобы аудио и текст были идеально согласованы. Это предотвращает ошибки настройки, которые могут возникнуть, когда текст образца отличается от того, что было фактически сказано. GitHub
VrchAudioRecorderNode (#43)#
Встроенный рекордер, который захватывает короткую произнесенную подсказку для клонирования, устраняя необходимость во внешних инструментах. Удерживайте для записи, отпустите для остановки и сразу услышите, как ComfyUI F5 TTS звучит в вашем собственном голосе. Держите микрофон близко и снижайте шум в комнате для получения наилучшего результата.
Дополнительные опции#
- Используйте от 5 до 15 секунд чистой речи для референса, без музыки или эффектов.
- Убедитесь, что текст образца точно соответствует записи; даже небольшие несоответствия могут снизить точность клонирования.
- Сравните Vocos и BigVGAN на одной линии, чтобы выбрать между скоростью и детализацией.
- Держите фиксированное семя, когда вам нужны согласованные дубли; рандомизируйте при изучении стиля.
- Для многоязычных проектов сначала прослушайте каналы EN, FR, DE и JP, затем завершите клонирование, когда вы будете довольны произношением и темпом.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы благодарны niknah за узел ComfyUI-F5-TTS, niknah за пример рабочего процесса F5TTS-test-all.json и сообществу r/StableDiffusion за руководство "Клонирование голосов с F5-TTS в ComfyUI" за их вклад и поддержку. Для получения авторитетной информации, пожалуйста, обращайтесь к оригинальной документации и репозиториям, перечисленным ниже.
Ресурсы#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Пример рабочего процесса: F5TTS-test-all.json)
- r/StableDiffusion/Community Guide (Клонирование голосов с F5-TTS в ComfyUI)
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.