
Character AI Ovi: изображение в видео с синхронизированной речью в ComfyUI#
Character AI Ovi - это аудиовизуальный workflow, который превращает одно изображение в говорящего, движущегося персонажа с координированным звуком. Основан на модели Wan и интегрирован через WanVideoWrapper, он генерирует видео и аудио за один проход, обеспечивая выразительную анимацию, понятную синхронизацию губ и контекстно-осведомленную атмосферу. Если вы создаете короткие истории, виртуальных ведущих или кинематографические социальные клипы, Character AI Ovi позволяет перейти от статического искусства к полному выступлению за считанные минуты.
Этот workflow ComfyUI принимает одно изображение плюс текстовый запрос, содержащий легкую разметку для речи и звукового дизайна. Он объединяет кадры и звуковую волну вместе, чтобы рот, ритм и аудио сцены естественно сочетались. Character AI Ovi разработан для создателей, которые хотят получить качественные результаты без сшивания отдельных TTS и видео инструментов.
Ключевые модели в Comfyui Character AI Ovi workflow#
- Ovi: Twin Backbone Cross-Modal Fusion для генерации аудио-видео. Основная модель, которая совместно производит видео и аудио из текстовых или текст+изображение запросов. character-ai/Ovi
- Wan 2.2 видео основа и VAE. Workflow использует высококомпрессионный видео VAE Wan для эффективного 720p, 24 fps генерации, сохраняя детализацию и временную согласованность. Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Google UMT5-XXL текстовый энкодер. Кодирует запрос, включая теги речи, в богатые многоязычные эмбеддинги, которые управляют обеими ветвями. google/umt5-xxl
- MMAudio VAE с BigVGAN вокодером. Декодирует аудио латенты модели в высококачественную речь и эффекты с естественным тембром. hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- ComfyUI-ready Ovi веса от Kijai. Курированные контрольные точки для видео ветви, аудио ветви и VAE в bf16 и fp8 масштабированных вариантах. Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- Узлы WanVideoWrapper для ComfyUI. Оболочка, которая предоставляет функции Wan и Ovi как составные узлы. kijai/ComfyUI-WanVideoWrapper
Как использовать Comfyui Character AI Ovi workflow#
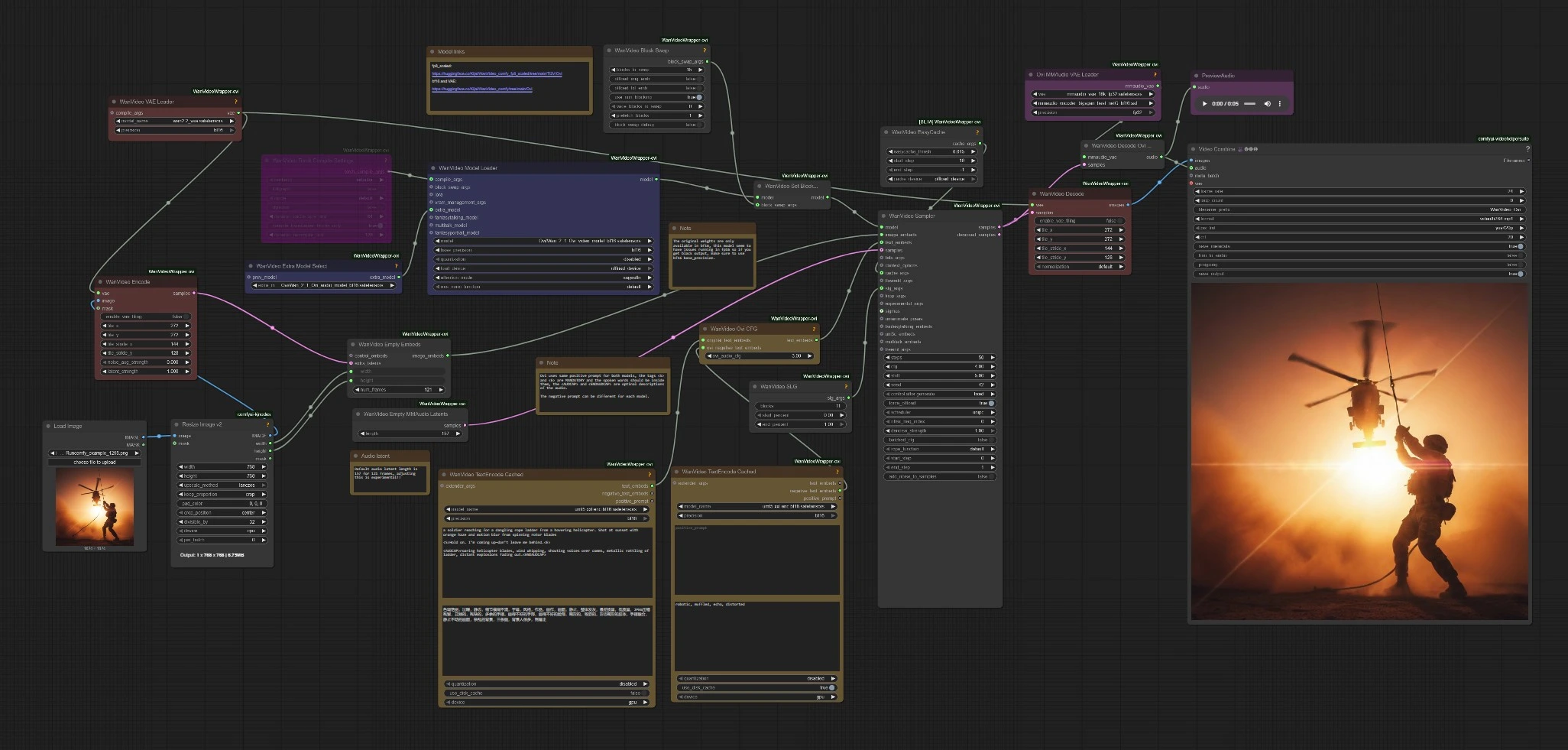
Этот workflow следует простому пути: закодируйте ваш запрос и изображение, загрузите контрольные точки Ovi, выберите совместные аудио+видео латенты, затем декодируйте и объедините в MP4. Подразделы ниже соответствуют видимым кластерам узлов, чтобы вы знали, где взаимодействовать и какие изменения влияют на результаты.
Написание запроса для речи и звука#
Напишите один позитивный запрос для сцены и произносимой реплики. Используйте теги Ovi точно так, как показано: оберните слова для произнесения в <S> и <E>, и по желанию опишите не речевые аудио с <AUDCAP> и <ENDAUDCAP>. Один и тот же позитивный запрос условливает как видео, так и аудио ветви, чтобы движение губ и время совпадали. Вы можете использовать разные негативные запросы для видео и аудио, чтобы независимо подавить артефакты. Character AI Ovi хорошо реагирует на краткие сценические указания плюс одну четкую строку диалога.
Загрузка и кондиционирование изображения#
Загрузите один портрет или изображение персонажа, затем workflow изменяет размер и кодирует его в латенты. Это устанавливает личность, позу и начальное кадрирование для выборщика. Ширина и высота на этапе изменения размера задают аспект видео; выберите квадрат для аватаров или вертикаль для короткометражек. Закодированные латенты и эмбеддинги, полученные из изображения, направляют выборщик, чтобы движение казалось привязанным к оригинальному лицу.
Загрузка модели и помощники по производительности#
Character AI Ovi загружает три основных компонента: видео модель Ovi, Wan 2.2 VAE для кадров и MMAudio VAE плюс BigVGAN для аудио. Torch компиляция и легкий кэш включены для ускорения холодных запусков. Помощник по замене блоков подключен для снижения использования VRAM путем выгрузки блоков трансформера при необходимости. Если вы ограничены в VRAM, увеличьте выгрузку блоков в узле замены блоков и держите кэш включенным для повторных запусков.
Совместная выборка с руководством#
Выборщик запускает двойные основы Ovi вместе, чтобы звуковая дорожка и кадры соразвивались. Помощник по руководству слоем пропуска улучшает стабильность и детализацию без ущерба для движения. Workflow также направляет ваши оригинальные текстовые эмбеддинги через Ovi-специфический CFG миксер, чтобы вы могли изменить баланс между строгим соблюдением запроса и более свободной анимацией. Character AI Ovi, как правило, производит лучшее движение губ, когда произносимая строка короткая, буквальная и заключена только в теги <S> и <E>.
Декодирование, предварительный просмотр и экспорт#
После выборки видео латенты декодируются через Wan VAE, а аудио латенты декодируются через MMAudio с BigVGAN. Видео-комбайнер объединяет кадры и аудио в MP4 на 24 fps, готовый к распространению. Вы также можете предварительно просмотреть аудио, чтобы проверить понятность речи перед сохранением. Стандартный путь Character AI Ovi нацелен на 5 секунд; расширяйте осторожно, чтобы сохранить синхронизацию губ и ритма.
Ключевые узлы в Comfyui Character AI Ovi workflow#
WanVideoTextEncodeCached(#85)
Кодирует основной позитивный запрос и негативный запрос видео в эмбеддинги, используемые обеими ветвями. Держите диалог внутри <S>…<E> и размещайте звуковой дизайн внутри <AUDCAP>…<ENDAUDCAP>. Для лучшей согласованности избегайте нескольких предложений в одном теге речи и держите строку краткой.
WanVideoTextEncodeCached(#96)
Предоставляет отдельное негативное текстовое эмбеддинг для аудио. Используйте его для подавления артефактов, таких как роботизированный тон или сильное эхо, не затрагивая визуальные элементы. Начните с коротких описаний и расширяйте только если проблема остается.
WanVideoOviCFG(#94)
Смешивает оригинальные текстовые эмбеддинги с аудио-специфическими негативами через Ovi-осведомленный классификатор-бесплатное руководство. Повышайте его, когда содержание речи отклоняется от написанной строки или движения губ кажутся неверными. Понижайте его слегка, если движение становится жестким или излишне ограниченным.
WanVideoSampler(#80)
Сердце Character AI Ovi. Он потребляет эмбеддинги изображений, совместные текстовые эмбеддинги и опциональное руководство для выборки единственного латента, содержащего как видео, так и аудио. Больше шагов увеличивает точность, но также и время выполнения. Если вы видите нагрузку на память или задержки, сочетайте более высокую замену блоков с включенным кэшем и рассмотрите возможность отключения компиляции torch для быстрой диагностики.
WanVideoEmptyMMAudioLatents(#125)
Инициализирует временную шкалу аудио латентов. Стандартная длина настроена для клипа в 121 кадр, 24 fps. Изменение этого для изменения продолжительности является экспериментальным; изменяйте это только если понимаете, как оно должно отслеживать количество кадров.
VHS_VideoCombine(#88)
Объединяет декодированные кадры и аудио в MP4. Установите частоту кадров в соответствии с вашей целью выборки и включите обрезку по аудио, если хотите, чтобы финальная версия следовала за сгенерированной звуковой волной. Используйте контроль CRF для баланса между размером файла и качеством.
Дополнительные опции#
- Используйте bf16 для видео Ovi и Wan 2.2 VAE. Если вы сталкиваетесь с черными кадрами, переключите базовую точность на
bf16для загрузчиков моделей и текстового энкодера. - Держите речи короткими. Character AI Ovi наиболее надежно синхронизирует губы с короткими, односложными диалогами внутри
<S>и<E>. - Отдельные негативы. Поместите визуальные артефакты в негативный запрос видео, а тональные артефакты в негативный запрос аудио, чтобы избежать непреднамеренных компромиссов.
- Предварительный просмотр сначала. Используйте предварительный просмотр аудио для подтверждения ясности и темпа перед экспортом финального MP4.
- Получите точные веса, используемые. Workflow ожидает контрольные точки видео и аудио Ovi плюс Wan 2.2 VAE из зеркал моделей Kijai. WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
С этими элементами на месте, Character AI Ovi становится компактным, ориентированным на создателей пайплайном для выразительных говорящих аватаров и повествовательных сцен, которые звучат так же хорошо, как и выглядят.
Благодарности#
Этот workflow реализует и основывается на следующих работах и ресурсах. Мы искренне благодарим kijai и Character AI за Ovi за их вклад и поддержку. Для получения авторитетной информации, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Character AI Ovi Source
- Workflow: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
Примечание: Использование указанных моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими лицами.
