








Fluxo de trabalho do Z Image ControlNet para geração de imagens guiadas por estrutura no ComfyUI#
Este fluxo de trabalho traz o Z Image ControlNet para o ComfyUI para que você possa direcionar o Z‑Image Turbo com estrutura precisa a partir de imagens de referência. Ele combina três modos de orientação em um gráfico: profundidade, bordas canny e pose humana, e permite que você alterne entre eles para corresponder à sua tarefa. O resultado é uma geração rápida e de alta qualidade de texto ou imagem-para-imagem, onde layout, pose e composição permanecem sob controle enquanto você itera.
Projetado para artistas, designers conceituais e planejadores de layout, o gráfico suporta prompts bilíngues e estilização opcional de LoRA. Você obtém uma prévia limpa do sinal de controle escolhido, além de uma faixa de comparação automática para avaliar profundidade, canny ou pose em relação ao resultado final.
Modelos principais no fluxo de trabalho do Comfyui Z Image ControlNet#
- Modelo de difusão Z‑Image Turbo 6B parâmetros. Gerador principal que produz imagens fotorrealistas rapidamente a partir de prompts e sinais de controle. alibaba-pai/Z-Image-Turbo
- Patch de união Z Image ControlNet. Adiciona controle de múltiplas condições ao Z‑Image Turbo e permite orientação de profundidade, bordas e pose em um patch de modelo. alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2. Produz mapas de profundidade densos usados para orientação de estrutura no modo de profundidade. LiheYoung/Depth-Anything-V2 on GitHub
- DWPose. Estima pontos-chave humanos e pose corporal para geração guiada por pose. IDEA-Research/DWPose
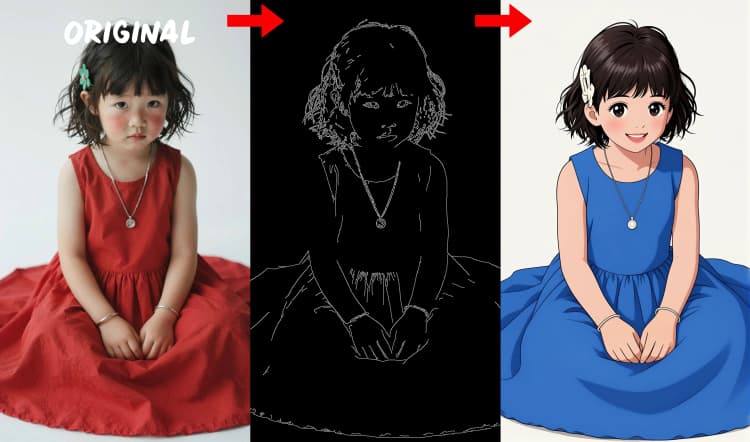
- Detector de bordas Canny. Extrai arte de linha limpa e limites para controle orientado por layout.
- Pré-processadores ControlNet Aux para ComfyUI. Fornece wrappers unificados para profundidade, bordas e pose usados por este gráfico. comfyui_controlnet_aux
Como usar o fluxo de trabalho do Comfyui Z Image ControlNet#
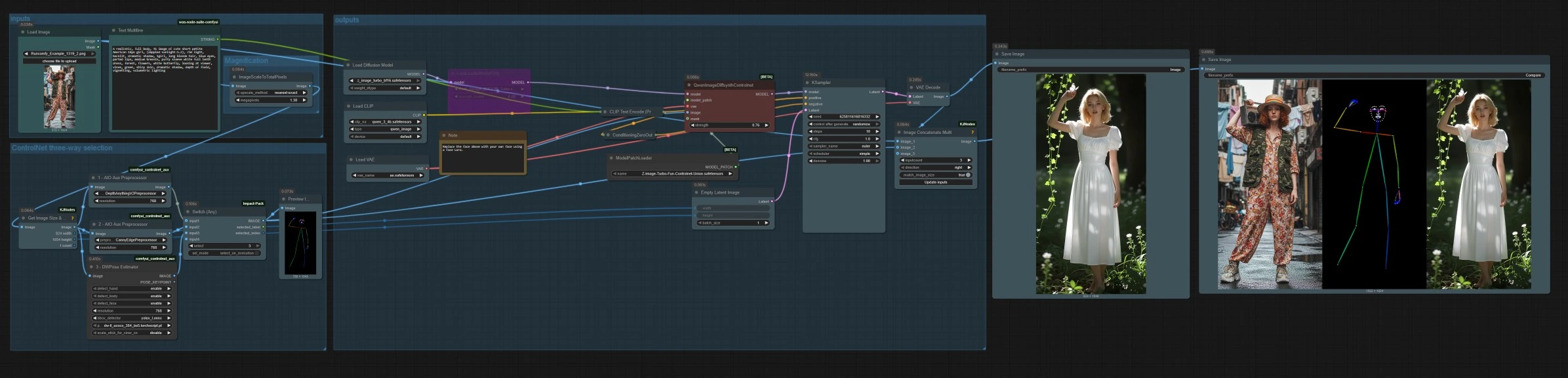
Em um nível alto, você carrega ou faz upload de uma imagem de referência, seleciona um modo de controle entre profundidade, canny ou pose, e então gera com um prompt de texto. O gráfico dimensiona a referência para amostragem eficiente, constrói um latente na proporção de aspecto correspondente e salva tanto a imagem final quanto uma faixa de comparação lado a lado.
entradas#
Use LoadImage (#14) para escolher uma imagem de referência. Insira seu prompt textual em Text Multiline (#17) a pilha Z‑Image suporta prompts bilíngues. O prompt é codificado por CLIPLoader (#2) e CLIPTextEncode (#4). Se preferir apenas imagem-para-imagem orientada por estrutura, você pode deixar o prompt mínimo e confiar no sinal de controle selecionado.
Seleção de três vias ControlNet#
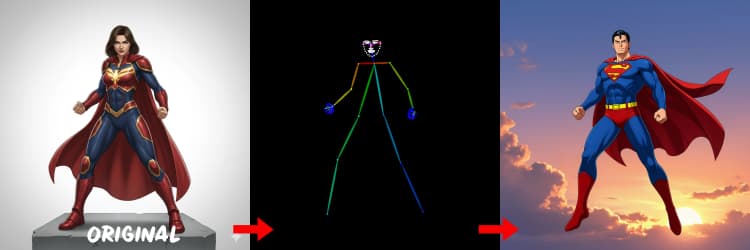
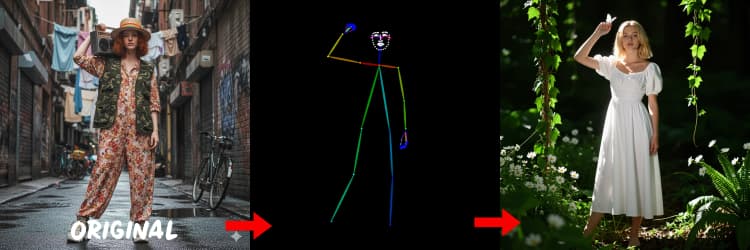
Três pré-processadores convertem sua referência em sinais de controle. AIO_Preprocessor (#45) produz profundidade com Depth Anything v2, AIO_Preprocessor (#46) extrai bordas canny, e DWPreprocessor (#56) estima pose de corpo inteiro. Use ImpactSwitch (#58) para selecionar qual sinal dirige o Z Image ControlNet, e verifique PreviewImage (#43) para confirmar o mapa de controle escolhido. Escolha profundidade quando quiser geometria de cena, canny para layout nítido ou fotos de produtos, e pose para trabalho de personagem.
Dicas para OpenPose: 1. Melhor para Corpo Inteiro: OpenPose funciona melhor (~70-90% de precisão) quando você inclui "corpo inteiro" no seu prompt. 2. Evite para Close-ups: A precisão cai significativamente em rostos. Use Depth ou Canny (força baixa/média) para close-ups. 3. Prompting Importa: Prompts influenciam fortemente o ControlNet. Evite prompts vazios para evitar resultados confusos.
Ampliação#
ImageScaleToTotalPixels (#34) redimensiona a referência para uma resolução de trabalho prática para equilibrar qualidade e velocidade. GetImageSizeAndCount (#35) lê o tamanho escalado e passa largura e altura para frente. EmptyLatentImage (#6) cria uma tela latente que corresponde ao aspecto do seu input redimensionado, para que a composição permaneça consistente.
saídas#
QwenImageDiffsynthControlnet (#39) funde o modelo base com o patch de união Z Image ControlNet e a imagem de controle selecionada, então KSampler (#7) gera o resultado guiado por seu condicionamento positivo e negativo. VAEDecode (#8) converte o latente em uma imagem. O fluxo de trabalho salva duas saídas SaveImage (#31) grava a imagem final, e SaveImage (#42) grava uma faixa de comparação via ImageConcatMulti (#38) que inclui a fonte, o mapa de controle e o resultado para QA rápido.
Nós principais no fluxo de trabalho do Comfyui Z Image ControlNet#
ImpactSwitch (#58)#
Escolhe qual imagem de controle dirige a geração: profundidade, canny ou pose. Altere modos para comparar como cada restrição molda composição e detalhe. Use-o ao iterar layouts para testar rapidamente qual orientação melhor se adapta ao seu objetivo.
QwenImageDiffsynthControlnet (#39)#
Conecta o modelo base, o patch de união Z Image ControlNet, o VAE e o sinal de controle selecionado. O parâmetro strength determina quão estritamente o modelo segue o input de controle versus o prompt. Para correspondência de layout rigorosa, aumente a força para mais variação criativa, reduza-a.
AIO_Preprocessor (#45)#
Executa o pipeline Depth Anything v2 para criar mapas de profundidade densos. Aumente a resolução para estrutura mais detalhada ou reduza para pré-visualizações mais rápidas. Combina bem com cenas arquitetônicas, fotos de produtos e paisagens onde a geometria importa.
DWPreprocessor (#56)#
Gera mapas de pose adequados para pessoas e personagens. Funciona melhor quando os membros estão visíveis e não estão fortemente ocultos. Se mãos ou pernas estiverem faltando, tente uma referência mais clara ou um quadro diferente com mais visibilidade do corpo completo.
LoraLoaderModelOnly (#54)#
Aplica um LoRA opcional ao modelo base para dicas de estilo ou identidade. Ajuste strength_model para misturar o LoRA suavemente ou fortemente. Você pode trocar um LoRA de rosto para personalizar sujeitos ou usar um LoRA de estilo para fixar um visual específico.
KSampler (#7)#
Realiza amostragem de difusão usando seu prompt e controle. Ajuste seed para reprodutibilidade, steps para orçamento de refinamento, cfg para adesão ao prompt, e denoise para quanto o resultado pode se desviar do latente inicial. Para edições de imagem-para-imagem, reduza denoise para preservar a estrutura; valores mais altos permitem mudanças maiores.
Extras opcionais#
- Para apertar a composição, use o modo de profundidade com uma referência limpa e bem iluminada; canny favorece forte contraste, e pose favorece fotos de corpo inteiro.
- Para edições sutis a partir de uma imagem de origem, mantenha o denoise modesto e aumente a força do ControlNet para estrutura fiel.
- Aumente os pixels alvo no grupo de Ampliação quando precisar de mais detalhes, depois reduza novamente para rascunhos rápidos.
- Use a saída de comparação para testar rapidamente A/B entre profundidade vs canny vs pose e escolher o controle mais confiável para seu assunto.
- Substitua o LoRA de exemplo por seu próprio LoRA de rosto ou estilo para incorporar identidade ou direção de arte sem retreinamento.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos a Alibaba PAI pelo Z Image ControlNet por suas contribuições e manutenção. Para detalhes autoritários, consulte a documentação e repositórios originais vinculados abaixo.
Recursos#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.

