
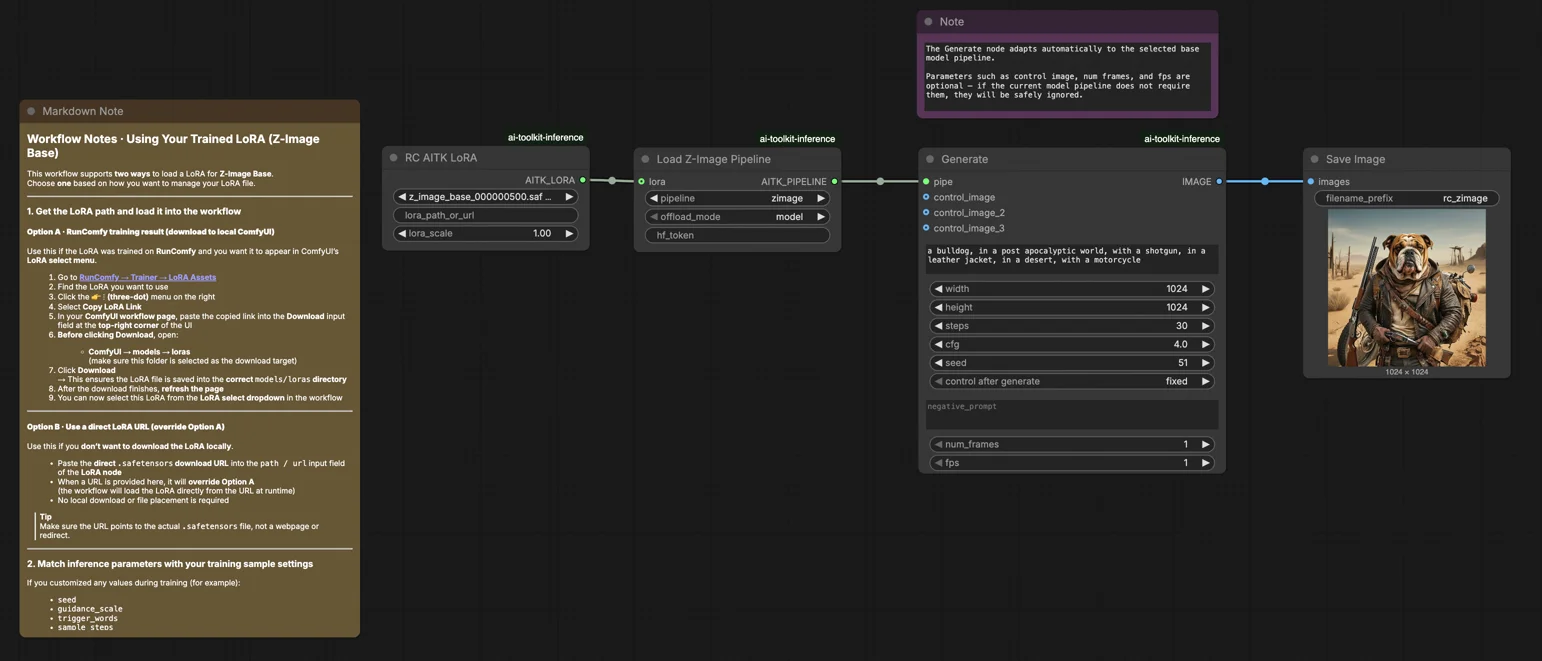
Inferência Z-Image Base LoRA ComfyUI: geração alinhada ao treinamento com LoRAs do AI Toolkit#
Este fluxo de trabalho pronto para produção do RunComfy permite que você execute adaptadores Z-Image LoRA treinados com o AI Toolkit no ComfyUI com resultados compatíveis com o treinamento. Construído em torno do RC Z-Image (RCZimage) — um nó personalizado em nível de pipeline de código aberto pelo RunComfy (fonte) — o fluxo de trabalho envolve o pipeline de inferência Tongyi-MAI/Z-Image em vez de depender de um gráfico de amostragem genérico. Seu adaptador é injetado via lora_path e lora_scale dentro desse pipeline, mantendo a aplicação de LoRA consistente com a forma como o AI Toolkit produz pré-visualizações de treinamento.
Por que a Inferência Z-Image Base LoRA ComfyUI muitas vezes parece diferente no ComfyUI#
As pré-visualizações de treinamento do AI Toolkit são renderizadas por um pipeline de inferência específico do modelo — configuração do agendador, fluxo de condicionamento e injeção de LoRA ocorrem todos dentro desse pipeline. Um gráfico de amostragem padrão do ComfyUI monta essas peças de forma diferente, então mesmo prompts, sementes e contagens de etapas idênticas podem gerar resultados visivelmente diferentes. A diferença não é causada por um único parâmetro errado; é um desajuste em nível de pipeline. O RCZimage recupera o comportamento alinhado ao treinamento ao envolver diretamente o pipeline Z-Image e aplicar seu LoRA dentro dele. Referência de implementação: `src/pipelines/z_image.py`.
Como usar o fluxo de trabalho de Inferência Z-Image Base LoRA ComfyUI#
Etapa 1: Obtenha o caminho do LoRA e carregue-o no fluxo de trabalho (2 opções)#
Opção A — Resultado de treinamento RunComfy → download para ComfyUI local:
- Vá para Trainer → LoRA Assets
- Encontre o LoRA que deseja usar
- Clique no menu ⋮ (três pontos) à direita → selecione Copiar Link do LoRA
- Na página de fluxo de trabalho do ComfyUI, cole o link copiado no campo de entrada Download no canto superior direito da interface
- Antes de clicar em Download, certifique-se de que a pasta de destino esteja definida como ComfyUI → models → loras (esta pasta deve ser selecionada como destino do download)
- Clique em Download — isso salva o arquivo LoRA no diretório
models/lorascorreto - Após o término do download, atualize a página
- O LoRA agora aparece no menu suspenso de seleção de LoRA no fluxo de trabalho — selecione-o

Opção B — URL Direto do LoRA (sobrepõe a Opção A):
- Cole o URL direto de download
.safetensorsno campo de entradapath / urldo nó LoRA - Quando um URL é fornecido aqui, ele sobrepõe a Opção A — o fluxo de trabalho carrega o LoRA diretamente do URL em tempo de execução
- Nenhum download local ou colocação de arquivo é necessário
Dica: o URL deve apontar para o arquivo .safetensors real, não uma página da web ou redirecionamento.

Etapa 2: Combine os parâmetros de inferência com suas configurações de amostra de treinamento#
Defina lora_scale no nó LoRA — comece com a mesma força que você usou durante as pré-visualizações de treinamento, depois ajuste conforme necessário.
Os parâmetros restantes estão no nó Generate:
prompt— seu prompt de texto; inclua qualquer palavra de ativação que você tenha usado durante o treinamentonegative_prompt— deixe vazio, a menos que seu YAML de treinamento inclua negativoswidth/height— resolução de saída; combine o tamanho da sua pré-visualização para comparação direta (múltiplos de 32)sample_steps— número de etapas de inferência; a base Z-Image padrão é 30 (use a mesma contagem da sua configuração de pré-visualização)guidance_scale— força do CFG; o padrão é 4.0 (espelhe o valor de pré-visualização do seu treinamento primeiro)seed— fixe uma semente para reproduzir resultados específicos; altere para explorar variaçõesseed_mode— escolhafixedourandomizehf_token— token do Hugging Face; necessário apenas se o modelo base ou repositório LoRA for restrito/privado
Dica de alinhamento de treinamento: se você personalizou quaisquer valores de amostragem durante o treinamento, copie esses valores exatos para os campos correspondentes. Se você treinou no RunComfy, abra Trainer → LoRA Assets → Config para ver o YAML resolvido e copiar as configurações de pré-visualização/amostra para o nó.

Etapa 3: Execute a Inferência Z-Image Base LoRA ComfyUI#
Clique em Queue/Run — o nó SaveImage grava os resultados automaticamente na pasta de saída do seu ComfyUI.
Lista de verificação rápida:
- ✅ LoRA é: baixado em
ComfyUI/models/loras(Opção A), ou carregado via um URL direto.safetensors(Opção B) - ✅ Página atualizada após o download local (somente Opção A)
- ✅ Os parâmetros de inferência correspondem à configuração de
samplede treinamento (se personalizado)
Se tudo acima estiver correto, os resultados da inferência aqui devem corresponder de perto às suas pré-visualizações de treinamento.
Solução de problemas de Inferência Z-Image Base LoRA ComfyUI#
A maioria das diferenças "pré-visualização de treinamento vs inferência ComfyUI" para Z-Image Base (Tongyi-MAI/Z-Image) vem de diferenças em nível de pipeline (como o modelo é carregado, quais padrões/agendador são usados, e onde/como o LoRA é injetado). Para LoRAs Z-Image Base treinadas com o AI Toolkit, a maneira mais confiável de retornar ao comportamento alinhado ao treinamento no ComfyUI é executar a geração através do RCZimage (o wrapper de pipeline do RunComfy) e injetar o LoRA via lora_path / lora_scale dentro desse pipeline.
(1) Ao usar Z-Image LoRA com ComfyUI, a mensagem "lora key not loaded" aparece.#
Por que isso acontece Isso geralmente significa que seu LoRA foi treinado contra um layout de módulo/chave diferente do que o carregador atual do Z-Image do ComfyUI espera. Com o Z-Image, o “mesmo nome de modelo” ainda pode envolver diferentes convenções de chave (por exemplo, original/estilo diffusers vs nomenclatura específica do Comfy), e isso é suficiente para acionar “key not loaded”.
Como corrigir (recomendado)
- Execute a inferência através do RCZimage (o wrapper de pipeline do fluxo de trabalho) e carregue seu adaptador via
lora_pathno RCAITKLoRA / caminho RCZimage, em vez de injetá-lo através de um carregador LoRA Z-Image genérico separado. - Mantenha o fluxo de trabalho consistente em formato: Z-Image Base LoRA treinado com AI Toolkit → inferir com o pipeline RCZimage alinhado ao AI Toolkit, para que você não dependa de remapeamento/conversores de chave do lado do ComfyUI.
(2) Erros ocorreram durante a fase VAE ao usar o carregador ZIMAGE LORA (somente modelo).#
Por que isso acontece Alguns usuários relatam que adicionar o carregador ZIMAGE LoRA (somente modelo) pode causar grandes lentidões e falhas posteriores na fase final de decodificação VAE, mesmo quando o fluxo de trabalho padrão Z-Image funciona bem sem o carregador.
Como corrigir (confirmado pelo usuário)
- Remova o carregador ZIMAGE LORA (somente modelo) e execute novamente o caminho padrão do fluxo de trabalho Z-Image.
- Neste fluxo de trabalho RunComfy, a “base segura” equivalente é: use RCZimage +
lora_path/lora_scalepara que a aplicação de LoRA permaneça dentro do pipeline, evitando o caminho problemático “carregador de modelo apenas LoRA”.
(3) O formato Comfy do Z-Image não corresponde ao código original#
Por que isso acontece O Z-Image no ComfyUI pode envolver um formato específico do Comfy (incluindo diferenças de nomenclatura de chave em relação às convenções “originais”). Se seu LoRA foi treinado com o AI Toolkit em uma convenção de nomenclatura/layout e você tentar aplicá-lo no ComfyUI esperando outra, você verá aplicação parcial/falha e comportamento de “funciona mas parece errado”.
Como corrigir (recomendado)
- Não misture formatos quando estiver tentando corresponder às pré-visualizações de treinamento. Use RCZimage para que a inferência execute o pipeline Z-Image na mesma “família” que as pré-visualizações do AI Toolkit usam, e injete o LoRA dentro dele via
lora_path/lora_scale. - Se você precisar usar uma pilha Z-Image no formato Comfy, certifique-se de que seu LoRA esteja no mesmo formato esperado por essa pilha (caso contrário, as chaves não se alinharão).
(4) Z-Image oom usando lora#
Por que isso acontece Z-Image + LoRA pode levar o VRAM ao limite dependendo da precisão/quantização, resolução e caminho do carregador. Alguns relatórios mencionam OOM em configurações de 12GB VRAM ao combinar LoRA com modos de menor precisão.
Como corrigir (base segura)
- Valide sua base primeiro: execute Z-Image Base sem LoRA na sua resolução alvo.
- Em seguida, adicione o LoRA via RCZimage (
lora_path/lora_scale) e mantenha as comparações controladas (mesmawidth/height,sample_steps,guidance_scale,seed). - Se ainda assim ocorrer OOM, reduza primeiro a resolução (Z-Image é sensível à contagem de pixels), depois considere diminuir
sample_steps, e só então reintroduza configurações mais altas após a estabilidade ser confirmada. No RunComfy, você também pode mudar para uma máquina maior.
Execute agora a Inferência Z-Image Base LoRA ComfyUI#
Abra o fluxo de trabalho RunComfy Z-Image Base LoRA ComfyUI Inference, defina seu lora_path, e deixe o RCZimage manter a saída do ComfyUI alinhada com suas pré-visualizações de treinamento do AI Toolkit.



