
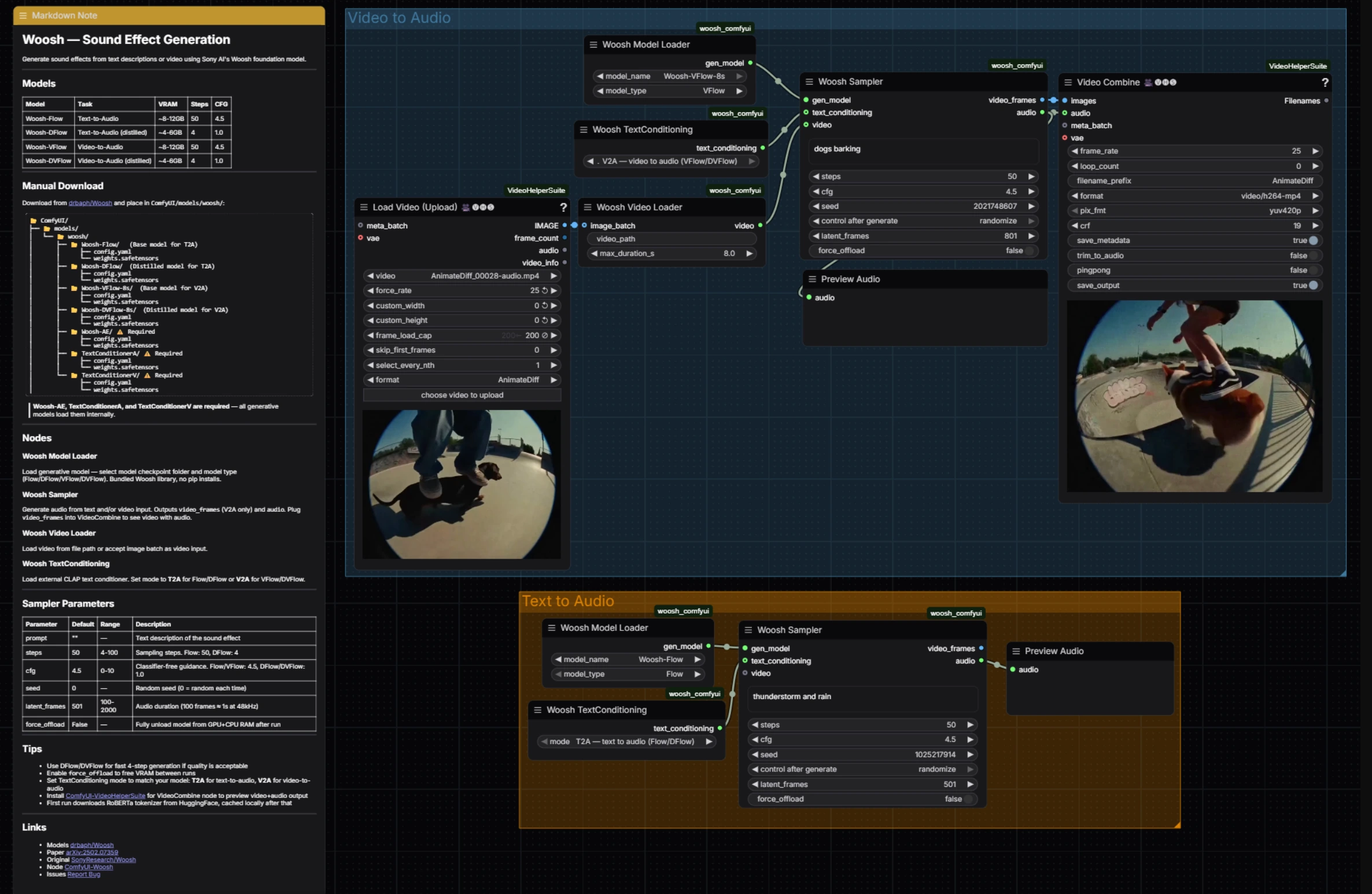
Geração de Efeito Sonoro Woosh: áudio condicionado por prompt e vídeo no ComfyUI#
A Geração de Efeito Sonoro Woosh é um fluxo de trabalho do ComfyUI que transforma prompts de texto ou clipes de vídeo em efeitos sonoros polidos usando o modelo Woosh da Sony Research. É construído para criadores que precisam de um lugar para Foley baseado em prompt, design de som estreitamente combinado com vídeo e troca rápida entre variantes destiladas de alta qualidade e rápidas.
O fluxo de trabalho expõe ambas as famílias de modelos Woosh: Flow/DFlow para texto-para-áudio e VFlow/DVFlow para vídeo-para-áudio. Um sampler compartilhado impulsiona a geração em ambos os caminhos, gerando áudio para pré-visualização imediata e, no caminho do vídeo, pré-visualizações de quadros que são recombinadas para dailies rápidas. Sob o capô, ele depende dos nós oficiais do ComfyUI Woosh e do VideoHelperSuite para IO de vídeo contínuo, então a Geração de Efeito Sonoro Woosh permanece rápida e simples enquanto continua flexível. Referências: SonyResearch/Woosh, drbaph/Woosh on Hugging Face, paper, ComfyUI-Woosh, ComfyUI-VideoHelperSuite.
Modelos principais no fluxo de trabalho Comfyui Woosh Sound Effect Generation#
- Sony Research Woosh — Flow: gerador de texto-para-áudio central usado para Foley de alta fidelidade e ambiente, treinado com objetivos de correspondência de fluxo. Veja SonyResearch/Woosh e o paper.
- Sony Research Woosh — DFlow: modelo de texto-para-áudio destilado otimizado para velocidade com muito menos etapas de amostragem, ideal para iteração rápida. Os pesos estão disponíveis via drbaph/Woosh.
- Sony Research Woosh — VFlow‑8s: gerador condicionado por vídeo que sincroniza inícios e texturas de áudio com dicas de movimento visual para vídeo-para-áudio. Veja SonyResearch/Woosh.
- Sony Research Woosh — DVFlow‑8s: modelo de vídeo-para-áudio destilado para fluxos de trabalho em tempo real e pré-visualizações rápidas. Pesos: drbaph/Woosh.
- Woosh‑AE: o autoencoder de áudio usado para reconstruir formas de onda a partir de latentes do modelo; necessário por todos os geradores. Pesos: drbaph/Woosh.
- TextConditionerA e TextConditionerV: módulos de condicionamento de texto que incorporam prompts adequadamente para execuções de texto-para-áudio ou vídeo-para-áudio. Detalhes e uso estão documentados em ComfyUI-Woosh e o paper.
Como usar o fluxo de trabalho Comfyui Woosh Sound Effect Generation#
Este fluxo de trabalho tem dois grupos paralelos que você pode executar de forma independente: Vídeo para Áudio para design de som combinado visualmente e Texto para Áudio para Foley puramente baseado em prompt. Ambos convergem na mesma lógica de sampler e pré-visualização rápida de áudio, tornando a Geração de Efeito Sonoro Woosh consistente para operar independentemente da entrada.
Vídeo para Áudio#
O grupo Vídeo para Áudio carrega um clipe, alinha quadros e condicionamento, e depois gera som sincronizado. Comece alimentando seu clipe em VHS_LoadVideo (#34); ele extrai quadros na taxa escolhida para que os nós a jusante vejam uma sequência limpa e delimitada. Esses quadros são empacotados como um fluxo de condicionamento de vídeo por WooshLoadVideo (#37), que padroniza a duração para que o gerador receba janelas estáveis.
Escolha um modelo condicionado por vídeo em WooshLoadFlow (#7), tipicamente VFlow para fidelidade ou DVFlow para velocidade. Forneça um prompt descritivo curto no sampler (para estilo ou intenção) e defina WooshTextEncode (#19) para V2A para que o texto seja incorporado com o ramo de condicionamento correto. Execute WooshSample (#38) para sintetizar áudio; ele gera tanto audio para PreviewAudio (#9) quanto video_frames que fluem para VHS_VideoCombine (#33) para uma pré-visualização rápida costurada, mantendo a Geração de Efeito Sonoro Woosh apertada para revisão editorial.
Texto para Áudio#
O grupo Texto para Áudio foca na geração limpa dirigida por prompt. Selecione um modelo em WooshLoadFlow (#40), usando Flow quando você quiser máxima qualidade e DFlow quando precisar de passagens muito rápidas e iterativas. Defina WooshTextEncode (#41) para T2A para que seu prompt seja incorporado para geração apenas de texto. Insira sua descrição em WooshSample (#39) e execute; o resultado é enviado para PreviewAudio (#43) para audição instantânea. Este caminho mantém a Geração de Efeito Sonoro Woosh leve quando você está criando bibliotecas ou camadas de efeitos sem imagem.
Nós principais no fluxo de trabalho Comfyui Woosh Sound Effect Generation#
WooshSample (#38)#
Sampler central para geração condicionada por vídeo. Ajuste o prompt para direcionar o estilo e os inícios, depois ajuste steps para o trade-off qualidade-velocidade (use menos etapas ao executar DVFlow). cfg controla a aderência ao prompt, e latent_frames determina o comprimento da saída para que corresponda ou intencionalmente desloque o clipe. Defina seed para reproduzir takes, e ative force_offload quando precisar limpar a memória entre execuções longas. A implementação e o comportamento do nó seguem o oficial ComfyUI-Woosh.
WooshSample (#39)#
Sampler para texto-para-áudio com os mesmos controles e comportamento, menos o fluxo de vídeo. Para ideação rápida, escolha DFlow e baixos steps; para finais, mude para Flow e aumente steps para detalhes. Mantenha cfg moderado para texturas naturais, aumente para resultados estilizados, bloqueados por prompt. Use latent_frames para definir a duração precisamente ao construir ativos para bibliotecas ou cronogramas DAW.
WooshLoadFlow (#7)#
Seletor de modelo para o caminho Vídeo para Áudio. Escolha VFlow para o alinhamento de maior fidelidade ao movimento, ou DVFlow quando precisar de pré-visualizações quase em tempo real. Certifique-se de que WooshTextEncode esteja definido para V2A para que as incorporações correspondam à família de modelos escolhida. Veja drbaph/Woosh para variantes do modelo.
WooshLoadFlow (#40)#
Seletor de modelo para o caminho Texto para Áudio. Escolha Flow para detalhes ricos e maior variedade de texturas, ou DFlow para iteração rápida com etapas mínimas. Emparelhe com WooshTextEncode no modo T2A para evitar incompatibilidades de condicionamento. O comportamento e as opções do nó acompanham o oficial ComfyUI-Woosh.
VHS_VideoCombine (#33)#
Utilitário para montar o audio gerado com a pré-visualização de video_frames do sampler para produzir um clipe revisável. Use-o para verificar a sincronização, avaliar transições e compartilhar dailies sem sair do ComfyUI. Parte do ComfyUI-VideoHelperSuite.
Extras opcionais#
- Use DVFlow/DFlow para passagens de reconhecimento rápido, depois mude para VFlow/Flow para finais quando a Geração de Efeito Sonoro Woosh deve brilhar.
- Mantenha seu clipe de entrada dentro da janela do modelo selecionado (por exemplo, as variantes VFlow de 8 segundos) e processe cenas mais longas em pedaços sobrepostos que você pode fundir gradualmente.
- Mantenha uma taxa de quadros consistente de
VHS_LoadVideoatravés deVHS_VideoCombinepara reduzir o desvio entre áudio e imagem. - Para prompts, combine palavras de ação com textura e contexto acústico (por exemplo, "whoosh metálico rápido em uma escada de concreto") para obter resultados previsíveis.
- Ative
force_offloadno sampler entre execuções pesadas se a memória GPU estiver apertada.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos sinceramente à Sony Research pelo Woosh (projeto e artigo), Saganaki22 pelo ComfyUI-Woosh (nó ComfyUI), e Kosinkadink pelo ComfyUI-VideoHelperSuite por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (paper)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.