
⚠️ Nota importante: Esta implementação ComfyUI do MultiTalk atualmente suporta apenas geração de UMA ÚNICA PESSOA. Recursos de conversação multi-pessoa estarão disponíveis em breve.
1. O que é MultiTalk?#
MultiTalk é um framework revolucionário para geração de vídeos conversacionais multi-pessoa baseados em áudio, desenvolvido pela MeiGen-AI. Diferente dos métodos tradicionais de geração de cabeças falantes que apenas animam movimentos faciais, a tecnologia MultiTalk pode gerar vídeos realistas de pessoas falando, cantando e interagindo, mantendo sincronização labial perfeita com a entrada de áudio. O MultiTalk transforma fotos estáticas em vídeos falantes dinâmicos, fazendo a pessoa falar ou cantar exatamente o que você deseja.
2. Como o MultiTalk funciona#
O MultiTalk utiliza tecnologia avançada de IA para compreender tanto sinais de áudio quanto informações visuais. A implementação ComfyUI do MultiTalk combina MultiTalk + Wan2.1 + Uni3C para resultados ideais:
Análise de áudio: O MultiTalk usa um poderoso codificador de áudio (Wav2Vec) para entender as nuances da fala, incluindo ritmo, tom e padrões de pronúncia.
Compreensão visual: Construído sobre o robusto modelo de difusão de vídeo Wan2.1, o MultiTalk compreende anatomia humana, expressões faciais e movimentos corporais (você pode visitar nosso workflow Wan2.1 para geração t2v/i2v).
Controle de câmera: O MultiTalk com Uni3C controlnet permite movimentos sutis de câmera e controle de cena, tornando o vídeo mais dinâmico e profissional. Confira nosso workflow Uni3C para criar belas transferências de movimento de câmera.
Sincronização perfeita: Através de mecanismos de atenção sofisticados, o MultiTalk aprende a alinhar perfeitamente os movimentos labiais com o áudio, mantendo expressões faciais e linguagem corporal naturais.
Seguir instruções: Diferente de métodos mais simples, o MultiTalk pode seguir prompts de texto para controlar a cena, pose e comportamento geral, mantendo a sincronização de áudio.
3. Benefícios do ComfyUI MultiTalk#
- Sincronização labial de alta qualidade: O MultiTalk alcança precisão de milissegundos na sincronização labial, especialmente impressionante para cenários de canto
- Criação de conteúdo versátil: O MultiTalk suporta geração de fala e canto com vários tipos de personagens, incluindo personagens de desenho animado
- Resolução flexível: O MultiTalk gera vídeos em 480P ou 720P em proporções arbitrárias
- Suporte a vídeos longos: O MultiTalk cria vídeos de até 15 segundos de duração
- Seguir instruções: O MultiTalk controla ações de personagens e configurações de cena através de prompts de texto
4. Como usar o workflow ComfyUI MultiTalk#
Guia passo a passo do MultiTalk#
Passo 1: Preparar as entradas do MultiTalk
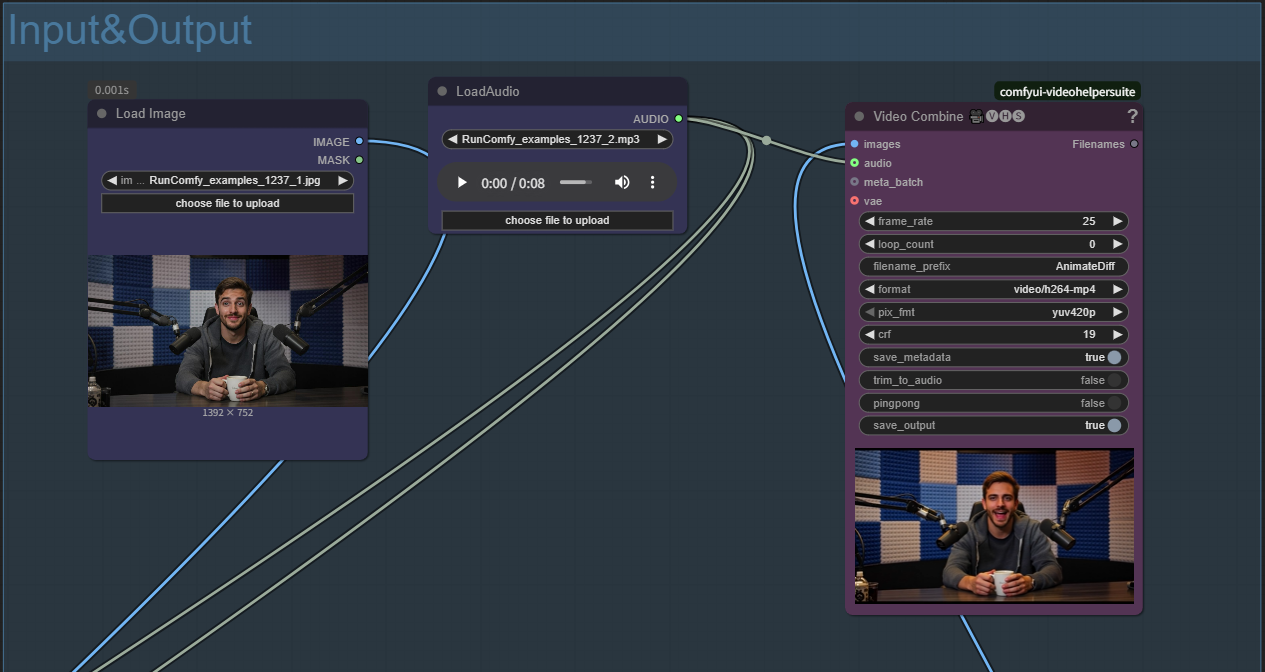
- Carregar imagem de referência: Clique em "choose file to upload" no nó Load Image
- Use fotos nítidas e frontais para melhores resultados do MultiTalk
- A imagem será automaticamente redimensionada para dimensões ideais (832px recomendado)
- Carregar arquivo de áudio: Clique em "choose file to upload" no nó LoadAudio
- O MultiTalk suporta vários formatos de áudio (WAV, MP3, etc.)
- Fala/canto nítido funciona melhor com o MultiTalk
- Para criar músicas personalizadas, considere usar nosso workflow de geração musical Ace-Step, que produz música de alta qualidade com letras sincronizadas.
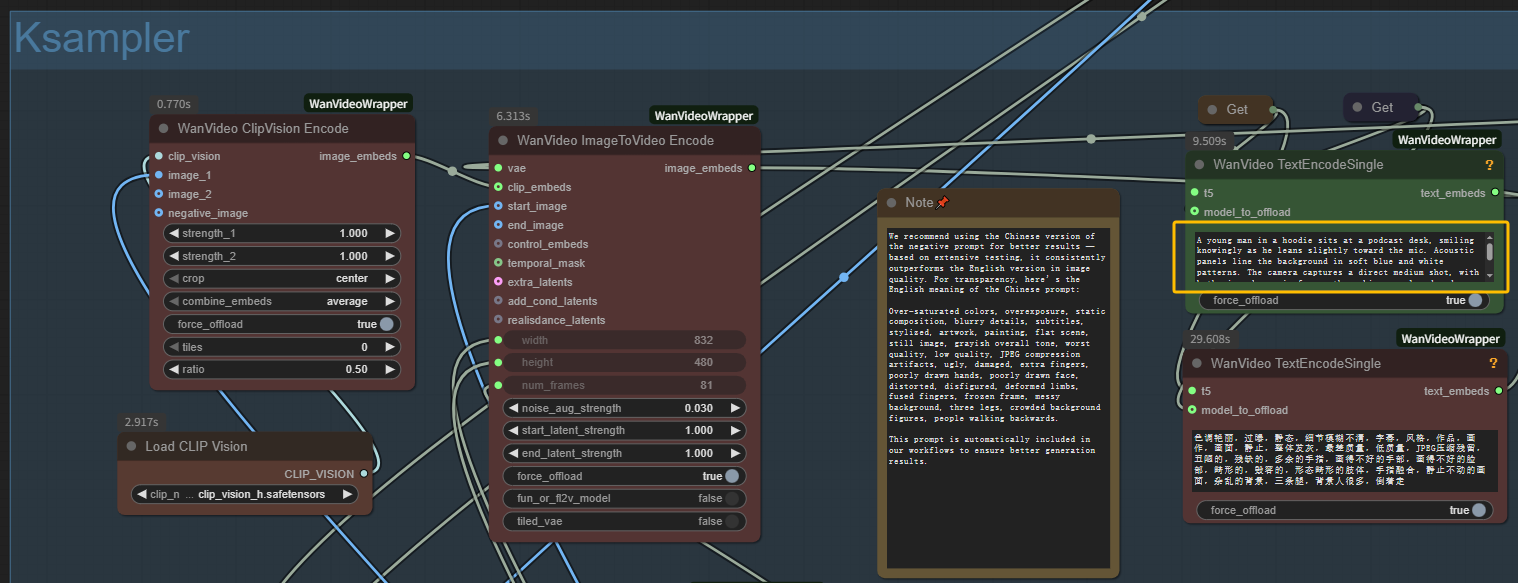
- Escrever prompt de texto: Descreva a cena desejada nos nós de codificação de texto para geração MultiTalk
Passo 2: Configurar as definições de geração do MultiTalk
- Passos de amostragem: 20-40 passos (maior = melhor qualidade MultiTalk, geração mais lenta)
- Audio Scale: Manter em 1.0 para sincronização labial MultiTalk ideal
- Embed Cond Scale: 2.0 para condicionamento de áudio MultiTalk equilibrado
- Controle de câmera: Ativar Uni3C para movimentos sutis, ou desativar para tomadas MultiTalk estáticas
Passo 3: Aprimoramentos opcionais do MultiTalk
- Aceleração LoRA: Ativar para geração MultiTalk mais rápida com perda mínima de qualidade
- Aprimoramento de vídeo: Usar nós de aprimoramento para melhorias de pós-processamento MultiTalk
- Prompts negativos: Adicionar elementos indesejados a evitar na saída MultiTalk (embaçado, distorcido, etc.)
Passo 4: Gerar com MultiTalk
- Colocar o prompt na fila e aguardar a geração MultiTalk
- Monitorar uso de VRAM (48GB recomendado para MultiTalk)
- Tempo de geração MultiTalk: 7-15 minutos dependendo das configurações e hardware
5. Agradecimentos#
Pesquisa original: O MultiTalk é desenvolvido pela MeiGen-AI com colaboração de pesquisadores líderes na área. O artigo original "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" apresenta a pesquisa inovadora por trás desta tecnologia.
Integração ComfyUI: A implementação ComfyUI é fornecida por Kijai através do repositório ComfyUI-WanVideoWrapper, tornando esta tecnologia avançada acessível à comunidade criativa mais ampla.
Tecnologia base: Construído sobre o modelo de difusão de vídeo Wan2.1 e incorpora técnicas de processamento de áudio do Wav2Vec, representando uma síntese de pesquisa de IA de ponta.
6. Links e recursos#
- Pesquisa original: MeiGen-AI MultiTalk Repository
- Página do projeto: https://meigen-ai.github.io/multi-talk/
- Integração ComfyUI: ComfyUI-WanVideoWrapper

