
LTX-2 ComfyUI: texto, imagem, profundidade e pose para vídeo em tempo real com áudio sincronizado#
Este fluxo de trabalho LTX-2 ComfyUI tudo-em-um permite que você gere e itere em vídeos curtos com áudio em segundos. Ele vem com rotas para texto para vídeo (T2V), imagem para vídeo (I2V), profundidade para vídeo, pose para vídeo e canny para vídeo, para que você possa começar a partir de um prompt, uma imagem fixa ou orientação estruturada e manter o mesmo ciclo criativo.
Construído em torno do pipeline AV de baixa latência do LTX-2 e do paralelismo de sequência multi-GPU, o gráfico enfatiza o feedback rápido. Descreva movimento, câmera, aparência e som uma vez, depois ajuste largura, altura, contagem de quadros ou controle LoRAs para refinar o resultado sem reconfigurar nada.
Nota: Nota sobre a Compatibilidade do Fluxo de Trabalho LTX-2 — O LTX-2 inclui 5 fluxos de trabalho: Texto para Vídeo e Imagem para Vídeo rodam em todos os tipos de máquinas, enquanto Profundidade para Vídeo, Canny para Vídeo e Pose para Vídeo requerem uma máquina 2X-Large ou maior; executar esses fluxos de trabalho ControlNet em máquinas menores pode resultar em erros.
Modelos principais no fluxo de trabalho LTX-2 ComfyUI#
- LTX-2 19B (dev FP8) checkpoint. Modelo gerativo audiovisual principal que produz quadros de vídeo e áudio sincronizado a partir de condicionamento multimodal. Lightricks/LTX-2
- LTX-2 19B Distilled checkpoint. Variante mais leve e rápida útil para rascunhos rápidos ou execuções controladas por canny. Lightricks/LTX-2
- Gemma 3 12B IT text encoder. Backbone primário de compreensão de texto usado pelos codificadores de prompt do fluxo de trabalho. Comfy-Org/ltx-2 split files
- LTX-2 Spatial Upscaler x2. Upsampler latente que dobra o detalhe espacial no meio do gráfico para saídas mais limpas. Lightricks/LTX-2
- LTX-2 Audio VAE. Codifica e decodifica latentes de áudio para que o som possa ser gerado e muxado juntamente com o vídeo. Incluído com o lançamento do LTX-2 acima.
- Lotus Depth D v1‑1. Depth UNet usado para derivar mapas de profundidade robustos a partir de imagens antes da geração de vídeo guiada por profundidade. Comfy‑Org/lotus
- SD VAE (MSE, EMA pruned). VAE usado no ramo do pré-processador de profundidade. stabilityai/sd-vae-ft-mse-original
- Control LoRAs para LTX‑2. LoRAs opcionais, plug‑and‑play para direcionar movimento e estrutura:
Como usar o fluxo de trabalho LTX-2 ComfyUI#
O gráfico contém cinco rotas que você pode executar de forma independente. Todas as rotas compartilham o mesmo caminho de exportação e usam a mesma lógica de prompt para condicionamento, então uma vez que você aprende uma, as outras parecem familiares.
T2V: gerar vídeo e áudio a partir de um prompt#
O caminho T2V começa com CLIP Text Encode (Prompt) (#3) e um opcional negativo em CLIP Text Encode (Prompt) (#4). LTXVConditioning (#22) vincula seu texto e a taxa de quadros escolhida ao modelo. EmptyLTXVLatentVideo (#43) e LTX LTXV Empty Latent Audio (#26) criam latentes de vídeo e áudio que são fundidos por LTX LTXV Concat AV Latent (#28). O loop de remoção de ruído passa por LTXVScheduler (#9) e SamplerCustomAdvanced (#41), após o qual VAE Decode (#12) e LTX LTXV Audio VAE Decode (#14) produzem quadros e áudio. Video Combine 🎥🅥🅗🅢 (#15) salva um H.264 MP4 com som sincronizado.
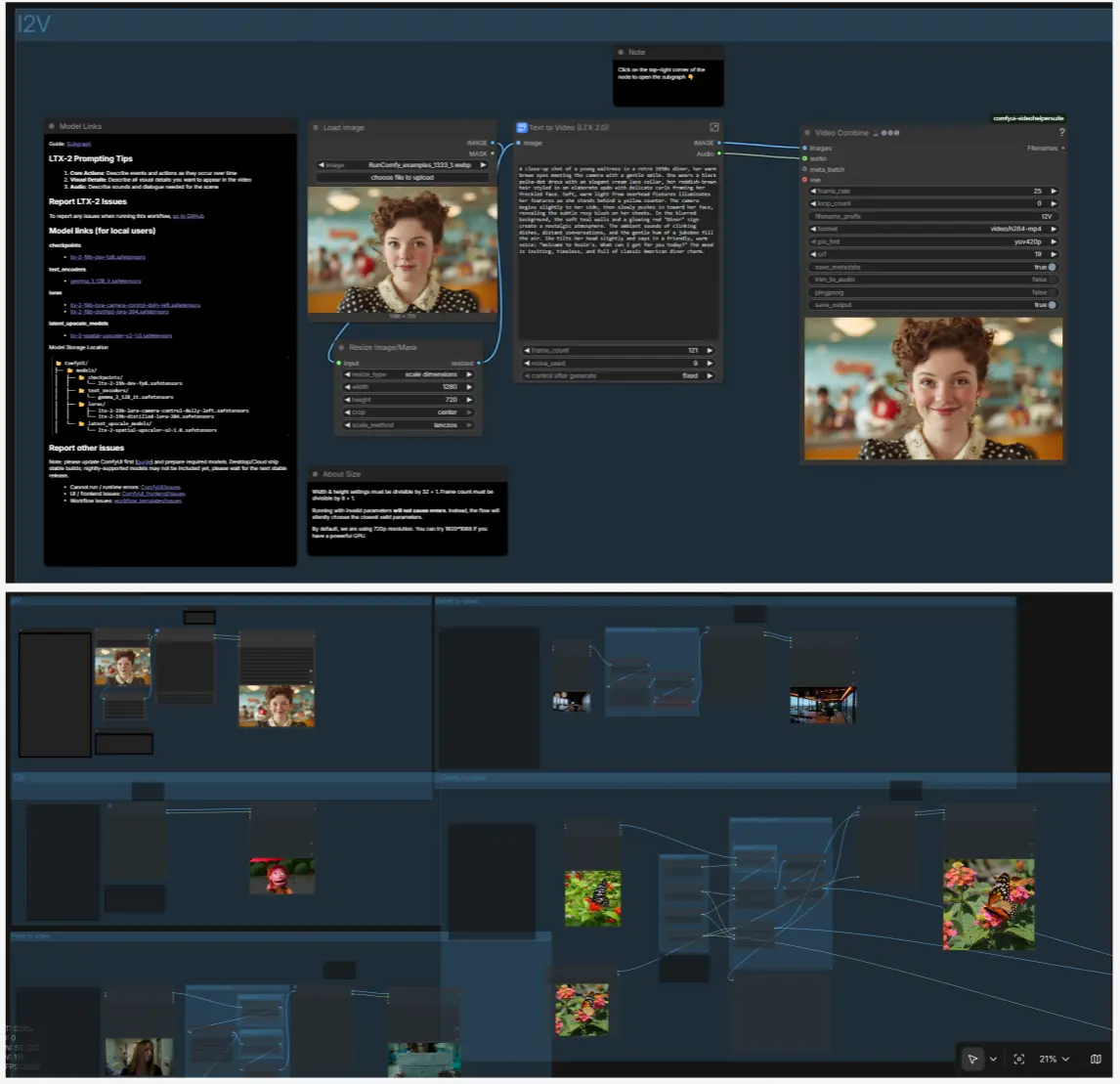
I2V: animar uma imagem fixa#
Carregue uma imagem fixa com LoadImage (#98) e redimensione com ResizeImageMaskNode (#99). Dentro do subgráfico T2V, LTX LTXV Img To Video Inplace injeta o primeiro quadro na sequência latente para que o movimento se construa a partir da sua imagem fixa em vez de puro ruído. Mantenha seu prompt textual focado em movimento, câmera e ambiente; o conteúdo vem da imagem.
Profundidade para vídeo: movimento consciente da estrutura a partir de mapas de profundidade#
Use o pré-processador “Image to Depth Map (Lotus)” para transformar uma entrada em uma imagem de profundidade, decodificada por VAEDecode e opcionalmente invertida para polaridade correta. A rota “Depth to Video (LTX 2.0)” então alimenta a orientação de profundidade através de LTX LTXV Add Guide para que o modelo respeite a estrutura global da cena enquanto anima. O caminho reutiliza os mesmos estágios de agendador, amostrador e upscaler, e termina com decodificação em mosaico para imagens e áudio muxado para exportação.
Pose para vídeo: dirigir movimento a partir da pose humana#
Importe um clipe com VHS_LoadVideo (#198); DWPreprocessor (#158) estima a pose humana de forma confiável através dos quadros. O subgráfico “Pose to Video (LTX 2.0)” combina seu prompt, o condicionamento de pose e um opcional Pose Control LoRA para manter membros, orientação e batidas consistentes enquanto permite que estilo e fundo fluam a partir do texto. Use isso para dança, acrobacias simples ou gravações de fala para câmera onde o tempo corporal importa.
Canny para vídeo: animação fiel às bordas e modo de velocidade destilada#
Alimente quadros para Canny (#169) para obter um mapa de bordas estável. O ramo “Canny to Video (LTX 2.0)” aceita as bordas mais um opcional Canny Control LoRA para alta fidelidade às silhuetas, enquanto “Canny to Video (LTX 2.0 Distilled)” oferece um checkpoint destilado mais rápido para iterações rápidas. Ambas as variantes permitem que você injete opcionalmente o primeiro quadro e escolha a força da imagem, depois exporte via CreateVideo ou VHS_VideoCombine.
Configurações de vídeo e exportação#
Defina largura e altura via Width (#175) e height (#173), o total de quadros com Frame Count (#176), e ative Enable First Frame (#177) se você quiser bloquear uma referência inicial. Use os nós VHS_VideoCombine no final de cada rota para controlar crf, frame_rate, pix_fmt e salvamento de metadados. Um SaveVideo (#180) dedicado é fornecido para a rota canny destilada quando você prefere saída de VÍDEO direta.
Desempenho e multi-GPU#
O gráfico aplica LTXVSequenceParallelMultiGPUPatcher (#44) com torch_compile ativado para dividir sequências através de GPUs para menor latência. KSamplerSelect (#8) permite que você escolha entre amostradores, incluindo estilos de Euler e estimativa de gradiente; contagens de quadros menores e etapas mais baixas reduzem o tempo de resposta para que você possa iterar rapidamente e escalar quando estiver satisfeito.
Nós principais no fluxo de trabalho LTX-2 ComfyUI#
LTX Multimodal Guider(#17). Coordena como o condicionamento de texto direciona os ramos de vídeo e áudio. AjustecfgemodalitynosLTX Guider Parametersvinculados (#18 para VÍDEO, #19 para ÁUDIO) para balancear fidelidade versus criatividade; aumentecfgpara maior aderência ao prompt e aumentemodality_scalepara enfatizar um ramo específico.LTXVScheduler(#9). Constrói um cronograma de sigma adaptado ao espaço latente do LTX‑2. Usestepspara trocar velocidade por qualidade; ao prototipar, menos etapas reduzem a latência, depois aumente as etapas para renderizações finais.SamplerCustomAdvanced(#41). O denoiser que uneRandomNoise, o amostrador escolhido deKSamplerSelect(#8), os sigmas do agendador e o latente AV. Troque amostradores para diferentes texturas de movimento e comportamento de convergência.LTX LTXV Img To Video Inplace(veja ramos I2V, por exemplo, #107). Injeta uma imagem em um latente de vídeo para que o primeiro quadro ancore o conteúdo enquanto o modelo sintetiza o movimento. Ajustestrengthpara quão estritamente o primeiro quadro é preservado.LTX LTXV Add Guide(em rotas guiadas, por exemplo, profundidade/pose/canny). Adiciona um guia estrutural (imagem, pose ou bordas) diretamente no espaço latente. Usestrengthpara balancear fidelidade ao guia com liberdade gerativa e ative o primeiro quadro apenas quando quiser ancoragem temporal.Video Combine 🎥🅥🅗🅢(#15 e similares). Empacota quadros decodificados e o áudio gerado em MP4. Para pré-visualizações, aumentecrf(mais compressão); para finais, reduzacrfe confirme queframe_ratecoincide com o que você configurou no condicionamento.LTXVSequenceParallelMultiGPUPatcher(#44). Habilita inferência em sequência paralela com otimizações de compilação. Deixe ativado para melhor rendimento; desative apenas ao depurar posicionamento de dispositivo.
Extras opcionais#
- Dicas de prompt para LTX-2 ComfyUI
- Descreva ações principais ao longo do tempo, não apenas aparência estática.
- Especifique detalhes visuais importantes que você deve ver no vídeo.
- Escreva a trilha sonora: ambiente, efeitos sonoros, música e qualquer diálogo.
- Regras de dimensionamento e taxa de quadros
- Use largura e altura que sejam múltiplos de 32 (por exemplo, 1280×720).
- Use contagens de quadros que sejam múltiplos de 8 (121 neste modelo é um bom comprimento).
- Mantenha a taxa de quadros consistente onde aparece; o gráfico inclui caixas de float e int e elas devem coincidir.
- Orientação LoRA
- LoRAs de câmera, profundidade, pose e canny são integradas; comece com força 1 para movimentos de câmera, depois adicione um segundo LoRA apenas quando necessário. Navegue pela coleção oficial em Lightricks/LTX‑2.
- Iterações mais rápidas
- Reduza a contagem de quadros, reduza as etapas em
LTXVSchedulere experimente o checkpoint destilado para a rota canny. Quando o movimento funcionar, escale a resolução e as etapas para os finais.
- Reduza a contagem de quadros, reduza as etapas em
- Reprodutibilidade
- Bloqueie
noise_seednos nós de Ruído Aleatório para obter resultados repetíveis enquanto ajusta prompts, tamanhos e LoRAs.
- Bloqueie
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos sinceramente à Lightricks pelo modelo de geração de vídeo multimodal LTX-2 e à base de código de pesquisa LTX-Video, e à Comfy Org pelos nós/parceiros de integração LTX-2 ComfyUI, por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Comfy Org/LTX-2 Agora Disponível no ComfyUI!
- GitHub: Lightricks/LTX-Video
- Hugging Face: Lightricks/LTX-Video-ICLoRA-detailer-13b-0.9.8
- arXiv: 2501.00103
- Docs / Release Notes: LTX-2 Now Available in ComfyUI!
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.