
LTX 2.3 Imagem para Vídeo para ComfyUI#
Este fluxo de trabalho transforma uma única imagem ou um prompt de texto puro em vídeo de IA suave e cinematográfico com LTX 2.3 Imagem para Vídeo. Foi construído para criadores que desejam alta coerência visual, forte consistência de cena e movimento polido sem cabeamento manual. Use-o no RunComfy ou em qualquer ambiente ComfyUI para gerar resultados dinâmicos e estilizados que permanecem fiéis ao seu prompt.
O gráfico suporta dois modos criativos: imagem para vídeo com seu primeiro quadro como âncora visual, ou texto para vídeo guiado inteiramente por linguagem. Inclui também aprimoramento automático de prompt, upscaling latente para detalhes mais nítidos e decodificação de áudio opcional para que o seu render final LTX 2.3 Imagem para Vídeo chegue pronto para publicação.
Modelos principais no fluxo de trabalho ComfyUI LTX 2.3 Imagem para Vídeo#
- Modelo de vídeo Lightricks LTX 2.3 22B. O transformador de difusão de vídeo central que sintetiza movimento e visuais temporalmente consistentes a partir de texto e orientação de imagem opcional. Arquivos de modelo e documentação estão disponíveis no Hugging Face e referências em nível de código no GitHub.
- LTX Audio VAE. O codificador auto-regressivo de áudio usado para decodificar o latente de áudio do modelo em uma faixa de áudio para muxing com quadros. Distribuído com o lançamento do LTX 2.3 no Hugging Face.
- LTX 2.3 Spatial Upscaler x2. Um modelo de super-resolução em espaço latente que melhora a nitidez e a fidelidade espacial antes da passagem final de amostragem em alta resolução. Disponível no repositório LTX 2.3 no Hugging Face.
- Codificador de texto Gemma 3 12B Instruct mais LoRA. Um codificador de texto compacto ajustado por instrução e LoRA usado aqui para melhorar a compreensão e a formulação de prompts para vídeo. O codificador empacotado e os pesos LoRA usados por este modelo estão disponíveis nos ativos Comfy-Org LTX-2 no Hugging Face.
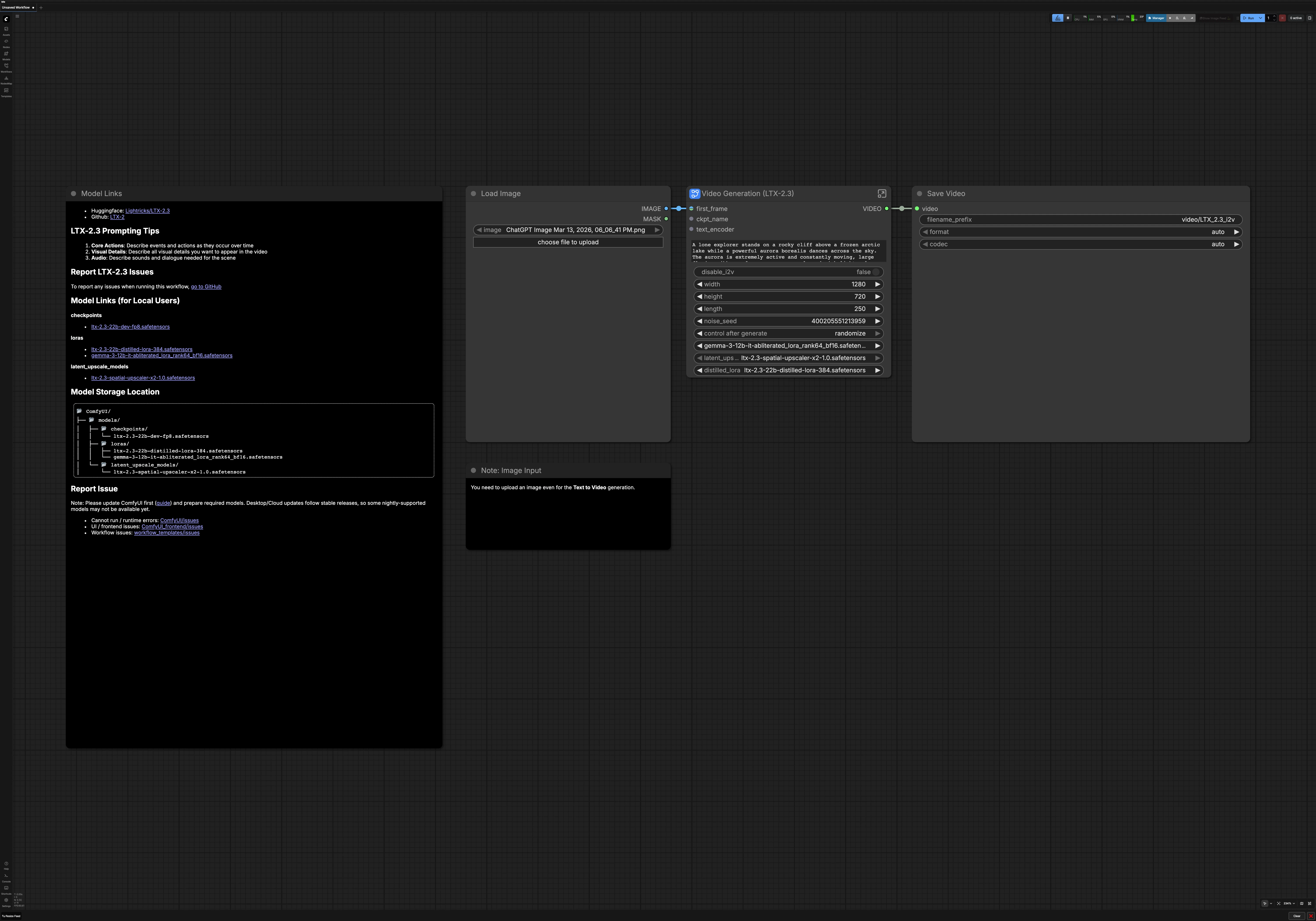
Como usar o fluxo de trabalho ComfyUI LTX 2.3 Imagem para Vídeo#
Em um nível alto, seu prompt e o primeiro quadro opcional são codificados, um vídeo latente de baixa resolução é amostrado, então aprimorado no espaço latente e refinado em resolução mais alta. O resultado é decodificado para quadros e áudio, então composto em um MP4 final. Você pode alternar entre imagem para vídeo e texto para vídeo a qualquer momento antes de executar.
- Modelo
- Este grupo carrega o checkpoint do LTX 2.3, o VAE de áudio e o codificador de texto. Ele também aplica o LTX 2.3 LoRA ao modelo base para melhorar o seguimento de instruções. Juntos, eles definem a base sobre a qual o restante do pipeline LTX 2.3 Imagem para Vídeo é construído. Normalmente, você não mudará nada aqui, a menos que troque variantes de modelo ou estilos de LoRA.
- Prompt
- Insira a descrição da sua cena e negativos opcionais. O texto é codificado para condicionamento positivo e negativo e emparelhado com sua taxa de quadros selecionada para que o planejamento do movimento se alinhe com o tempo. Mantenha a linguagem consciente do tempo com verbos que descrevem mudanças, por exemplo, "câmera avança" ou "folhas giram no vento". Prompts negativos ajudam a evitar artefatos indesejados, como marcas d'água ou simplificações cartunescas.
- Aprimoramento de Prompt
- O gráfico inclui um assistente que analisa sua imagem e texto, gerando um rascunho de prompt mais forte e consciente do tempo que você pode adotar ou editar. Isso facilita direcionar o LTX 2.3 Imagem para Vídeo para descrições cinematográficas e orientadas por ação. É especialmente útil quando você começa com uma imagem estática e deseja um movimento que pareça intencional. O nó de visualização permite que você inspecione o texto aprimorado antes da geração.
- Configurações de Vídeo
- Escolha se deseja executar imagem para vídeo ou alternar para texto para vídeo com uma simples alternância. Defina largura, altura, duração e taxa de quadros para se ajustar à sua plataforma de destino. Essas configurações direcionam a alocação latente e a decodificação a jusante, então mantenha-as em sincronia com sua intenção criativa. Se você planeja publicar amplamente, favoreça dimensões e tempos que sejam compatíveis com codecs.
- Pré-processamento de Imagem
- Seu primeiro quadro é redimensionado e normalizado para um aspecto amigável ao modelo enquanto preserva a composição. Um pré-filtro leve ajuda a estabilizar bordas e reduzir ruído de compressão que pode causar tremulação durante o movimento. Esta etapa é importante mesmo quando você usa a imagem apenas para sugerir layout e cor.
- Latente Vazio
- O fluxo de trabalho aloca latentes de vídeo e áudio vazios com base em suas dimensões, duração e taxa de quadros. Isso fornece uma tela limpa para o sampler e garante que áudio e vídeo permaneçam alinhados em comprimento. O ruído é gerado de forma determinística quando você deseja reprodutibilidade ou aleatorizado para variação entre execuções.
- Gerar Baixa Resolução
- Uma primeira passagem de amostragem esculpe movimento e estrutura em um vídeo latente compacto. Se você estiver usando imagem para vídeo,
LTXVImgToVideoInplace(#249) injeta seu primeiro quadro como uma âncora visual para que o movimento evolua a partir de um ponto de partida coerente. O condicionamento do seu texto positivo e negativo guia o conteúdo e o estilo, enquantoManualSigmas(#252) eKSamplerSelectdefinem quão agressivamente o ruído é removido ao longo do tempo.LTXVCropGuides(#212) ajuda a manter o enquadramento que corresponde ao seu prompt. O latente de áudio-vídeo resultante é então dividido para processamento separado.
- Uma primeira passagem de amostragem esculpe movimento e estrutura em um vídeo latente compacto. Se você estiver usando imagem para vídeo,
- Aprimorar Latente
- Antes de se comprometer com o refinamento em alta resolução,
LTXVLatentUpsampler(#253) aplica o aprimorador espacial x2 ao latente de baixa resolução. Fazer isso no espaço latente é rápido e preserva o movimento aprendido enquanto aumenta a capacidade de detalhes. É uma maneira segura de adicionar nitidez sem introduzir artefatos.
- Antes de se comprometer com o refinamento em alta resolução,
- Gerar Alta Resolução
- Um segundo sampler refina o latente aprimorado em tamanho espacial maior para fixar texturas, iluminação e pequenos movimentos. Ao executar texto para vídeo, a etapa anterior de imagem para vídeo pode ser ignorada e
LTXVImgToVideoInplace(#230) simplesmente passa o latente.VAEDecodeTiled(#251) então decodifica o vídeo latente para quadros de maneira eficiente. Em paralelo, o latente de áudio é decodificado com o LTX Audio VAE para que ambas as streams terminem precisas em quadros.
- Um segundo sampler refina o latente aprimorado em tamanho espacial maior para fixar texturas, iluminação e pequenos movimentos. Ao executar texto para vídeo, a etapa anterior de imagem para vídeo pode ser ignorada e
- Exportar
CreateVideo(#242) combina quadros e áudio decodificado em um único vídeo na taxa de quadros escolhida. O nó de nível superiorSaveVideograva o arquivo final na saída do ComfyUI para que você possa baixá-lo imediatamente. Seu render LTX 2.3 Imagem para Vídeo agora está pronto para visualização ou publicação.
Nós principais no fluxo de trabalho ComfyUI LTX 2.3 Imagem para Vídeo#
LTXVImgToVideoInplace(#249 e #230)- Converte uma imagem estática em um latente de vídeo ou passa o latente quando desativado. Use-o quando você quiser que o primeiro quadro defina layout, paleta e colocação de personagens. Altere a chave de texto para vídeo se você preferir que o movimento surja apenas do prompt. A documentação para a família de operadores é mantida na integração ComfyUI no GitHub.
LTXVConditioning(#239)- Combina texto codificado positivo e negativo com sua taxa de quadros para produzir condicionamento que direciona tanto o conteúdo quanto o ritmo do movimento. Prefira frases curtas e claras que descrevam a mudança ao longo do tempo e reserve negativos para artefatos que você vê consistentemente e deseja suprimir. Este nó é o lugar mais eficaz para ajustar estilo e comportamento de cena sem tocar nos samplers.
ManualSigmas(#252) comKSamplerSelect- O cronograma de ruído e o sampler trabalham juntos para equilibrar movimento amplo versus detalhe fino. Ruído inicial mais alto encoraja movimento mais amplo enquanto etapas posteriores consolidam textura. Ajuste isso apenas depois de ter bons prompts e orientação de imagem no lugar. Os controles de amostragem subjacentes seguem a semântica padrão do ComfyUI, veja implementações de referência no repositório LTX no GitHub.
LTXVLatentUpsampler(#253)- Aplica o aprimorador espacial LTX 2.3 no espaço latente para que você possa refinar em resolução mais alta na próxima etapa. Use-o quando precisar de nitidez extra ou planejar entregar formatos maiores. O modelo x2 é distribuído com LTX 2.3 no Hugging Face.
VAEDecodeTiled(#251) eCreateVideo(#242)- A decodificação em mosaico previne picos de memória em resoluções mais altas e garante qualidade consistente de quadros.
CreateVideoentão monta quadros e a faixa de áudio decodificada em um MP4 final na fps selecionada. Mantenha sua fps consistente com o valor usado durante o condicionamento para evitar desvio de reprodução.
- A decodificação em mosaico previne picos de memória em resoluções mais altas e garante qualidade consistente de quadros.
Extras opcionais#
- Você ainda deve carregar uma imagem do primeiro quadro mesmo ao usar texto para vídeo. O alternador irá ignorá-lo durante a geração, mas a UI requer uma imagem de espaço reservado.
- Para prompts de LTX 2.3 Imagem para Vídeo, comece com a ação principal, depois os detalhes visuais, depois a atmosfera. Palavras de tempo como "lentamente", "de repente", e "continua" ajudam o modelo a planejar o movimento.
- Use prompts negativos para evitar sobreposições e artefatos de UI como "marca d'água", "legendas" ou "quadro estático".
- Se o estilo parecer muito forte ou muito fraco, experimente um LoRA diferente ou ajuste seu peso no carregador LoRA. Você também pode remover o LoRA para se apoiar no visual do modelo base.
- Reutilize uma semente de ruído fixa para reprodutibilidade ao iterar no texto, depois aleatorize para variação uma vez que você travar a cena.
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos profundamente à Lightricks pelo LTX-2.3 e EyeForAILabs pelo EyeForAILabs YouTube Tutorial por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
Nota: O uso dos modelos, conjuntos de dados e códigos referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.