
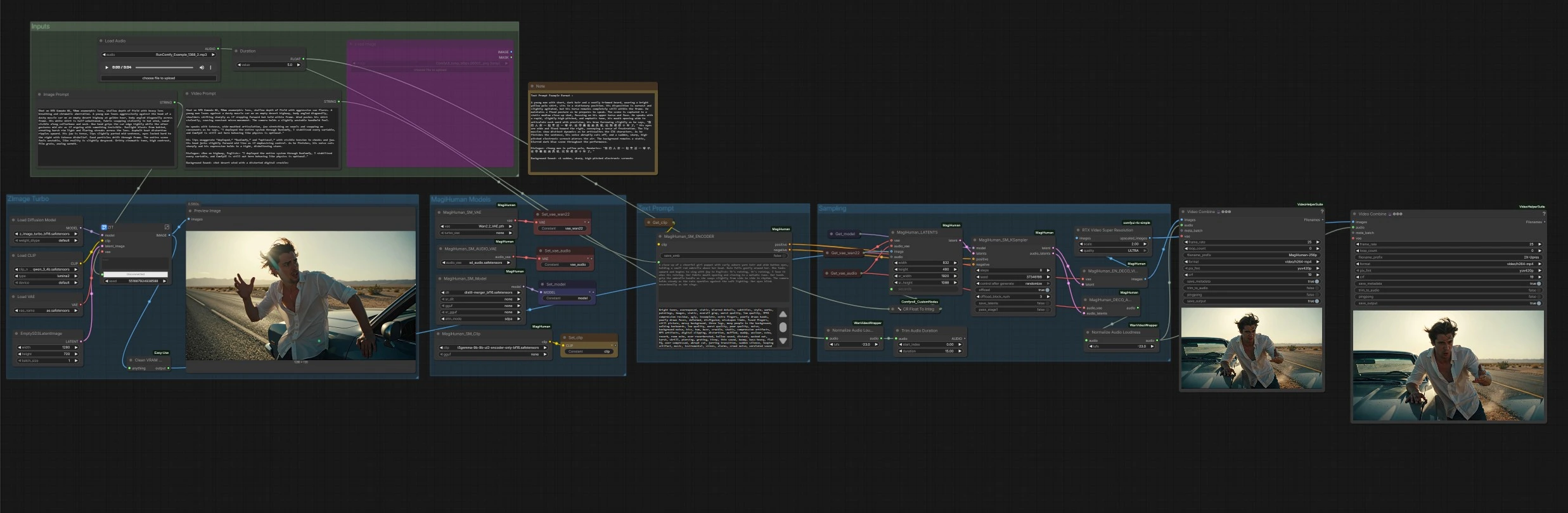
Workflow de humanos digitais falantes daVinci-MagiHuman para ComfyUI#
Este workflow ComfyUI constrói um pipeline completo de texto para vídeo em torno do daVinci-MagiHuman para gerar humanos digitais falantes realistas com fala sincronizada, movimento labial, expressão e micro-movimento corporal. É projetado para criadores que desejam um caminho rápido e de um clique de um prompt descritivo para um MP4 com áudio limpo. O gráfico pode animar um retrato recém-gerado ou qualquer imagem de referência fornecida, renderizando vídeo e fala juntos, finalizando com upscaling opcional e normalização automática de volume de áudio.
O núcleo daVinci-MagiHuman usa um Transformer de fluxo único para co-gerar vídeo e áudio a partir de um prompt, o que ajuda a preservar a temporização e a fidelidade da sincronia labial mesmo em clipes curtos. Esta implementação ComfyUI mantém os controles simples: escreva um Image Prompt para definir a aparência, um Video Prompt para definir o desempenho e o diálogo, defina a Duração do clipe e execute.
Modelos principais no workflow ComfyUI daVinci-MagiHuman#
- daVinci-MagiHuman (gerador de áudio-vídeo de fluxo único de 15B). Função: produz conjuntamente quadros de vídeo e fala a partir de texto enquanto mantém a consistência temporal e sincronia labial. Referências: GitHub, arXiv, Hugging Face.
- T5Gemma 9B encoder (UL2-adaptado). Função: codifica o Video Prompt em um condicionamento rico que orienta o movimento, a entrega e o estilo para o daVinci-MagiHuman. Referência: Hugging Face.
- Modelo de difusão Z-Image Turbo. Função: gera rapidamente um retrato fixo de alta qualidade a partir do Image Prompt para usar como identidade/referência para animação. Referências: Hugging Face (z_image_turbo), Hugging Face (z_image).
- Codificador de texto Qwen 3 4B para Z-Image Turbo. Função: analisa o Image Prompt para guiar a geração do retrato. Referência: Hugging Face file.
- Wan 2.2 VAE. Função: decodifica latentes de vídeo MagiHuman para quadros RGB com forte consistência temporal. Referências: GitHub, Hugging Face example model.
- Audio VAE (sd_audio). Função: decodifica latentes de áudio MagiHuman para uma forma de onda de fala para multiplexação com o vídeo final. Referência: pacote de nós personalizado para MagiHuman GitHub.
- RTX Video Super Resolution (opcional). Função: pós-amplia quadros decodificados para aumentar a nitidez percebida e reduzir artefatos de compressão antes da codificação final. Referência: ComfyUI wrapper GitHub.
Como usar o workflow ComfyUI daVinci-MagiHuman#
Fluxo geral: o grupo Z-Image Turbo cria um retrato de identidade a partir do seu Image Prompt. O grupo de Modelos MagiHuman carrega o checkpoint daVinci-MagiHuman, o VAE de vídeo e o VAE de áudio, e prepara o codificador de texto. O grupo de Text Prompt transforma seu Video Prompt em condicionamento. O grupo de Amostragem funde a imagem de referência e o prompt em latentes conjuntos de vídeo e áudio, então decodifica ambos. Finalmente, o estágio de Outputs multiplexa quadros com áudio em MP4, com uma versão ampliada opcional.
Entradas#
Use as caixas de texto Image Prompt e Video Prompt para descrever a aparência e o desempenho. O controle de Duração define o comprimento do clipe em segundos. Um carregador de áudio está presente para conveniência se você planeja experimentar variantes dirigidas por áudio, mas este modelo funciona em modo dirigido por texto por padrão.
ZImage Turbo#
Esta etapa renderiza um único retrato de referência a partir do Image Prompt usando o Z-Image Turbo UNet com o codificador de texto Qwen 3 4B e seu VAE incorporado. É otimizado para geração de identidade rápida e limpa com aparência cinematográfica. O resultado é visualizado e então encaminhado como a imagem de referência para animação. Se você já tiver uma foto de rosto, pode ignorar isso conectando sua imagem diretamente ao estágio de animação.
Modelos MagiHuman#
Aqui o gráfico carrega o checkpoint base ou destilado daVinci-MagiHuman junto com o VAE de vídeo Wan 2.2, o VAE de áudio e o codificador T5Gemma. Isso mantém a codificação de texto, latentes de vídeo e latentes de áudio alinhados para amostragem de fluxo único. Você pode trocar pesos se tiver alternativas disponíveis em seu ambiente.
Text Prompt#
Seu Video Prompt é codificado em condicionamento positivo e negativo. O texto positivo deve descrever a distância da câmera, pose, idioma, estilo de entrega e o conteúdo exato do diálogo. O texto negativo pode listar defeitos visuais ou de áudio a evitar. O codificador alimenta ambos os conjuntos de condicionamento no sampler para moldar o movimento, dinâmica labial e timbre.
Amostragem#
O sampler constrói uma sequência latente inicial a partir da imagem de referência e da Duração solicitada, então realiza a remoção de ruído com daVinci-MagiHuman para produzir latentes sincronizados de vídeo e áudio. Um utilitário converte Duração em segundos inteiros para agendamento estável. Quando a amostragem é concluída, os latentes de vídeo vão para o decodificador de vídeo e os latentes de áudio vão para o decodificador de áudio.
Decodificar, volume e exportar#
Latentes de vídeo são decodificados com o VAE Wan 2.2 para quadros de imagem. Latentes de áudio são decodificados para fala, então normalizados para um volume amigável de transmissão para que o MP4 final seja reproduzido de forma consistente em todos os dispositivos. Duas exportações são produzidas: uma renderização base e uma renderização ampliada opcional usando RTX Video Super Resolution. Ambas são multiplexadas para MP4 com áudio e salvas com prefixos de nome de arquivo claros.
Nós principais no workflow ComfyUI daVinci-MagiHuman#
MagiHuman_LATENTS(#13)
Constrói a tela latente conjunta para vídeo e áudio opcional, levando a imagem de referência e o comprimento do clipe. Ajuste seconds para definir a duração e certifique-se de que sua imagem de referência esteja bem enquadrada para o movimento que você descreve. Maior resolução base ajuda na fidelidade facial, mas também aumenta o VRAM e o tempo de decodificação.
MagiHuman_SM_ENCODER(#95)
Codifica o Video Prompt em condicionamento positivo e negativo para o sampler. Coloque a linha falada exata entre aspas e nomeie o idioma para melhorar o fechamento labial e o tempo. Use o campo negativo para suprimir artefatos como "subtitles", "static" ou "room echo".
MagiHuman_SM_KSampler(#9)
Executa a remoção de ruído daVinci-MagiHuman para co-gerar latentes de vídeo e fala. O seed controla a reprodutibilidade, enquanto steps e o agendamento interno trocam velocidade por detalhes e estabilidade de movimento. Para variação sem perder identidade, mude seed ou reformule levemente a parte de desempenho do seu prompt.
MagiHuman_EN_DECO_VIDEO(#5)
Decodifica latentes de vídeo com o VAE Wan 2.2 em quadros RGB para exportação ou ampliação. Use este caminho para a renderização mais rápida de ponta a ponta; clipes longos ou resoluções mais altas aumentarão linearmente o tempo de decodificação.
MagiHuman_DECO_AUDIO(#6)
Decodifica latentes de áudio para forma de onda e os envia por normalização de volume para reprodução uniforme. Se mais tarde você mudar para geração dirigida por áudio, roteie seu áudio externo para o construtor de latentes e mantenha este caminho de decodificação para a multiplexação final.
RTXVideoSuperResolution(#93)
Pós-amplificador opcional que afia bordas e reduz o ringing. Use força moderada para melhorar a clareza sem introduzir cintilação temporal.
Extras opcionais#
- Padrão de prompting para sincronia labial confiável: inclua uma tag de locutor e idioma além de uma linha entre aspas, por exemplo, Dialogue: <Presenter, English>: "Welcome to the show." Adicione uma breve nota sobre entrega, tamanho do plano e estabilidade da câmera.
- Mantenha o retrato de referência como um close médio com a cabeça totalmente dentro do quadro. Cortes apertados deixam pouco espaço para dinâmica de mandíbula e bochecha.
- Se precisar de sincronização mais estrita, reduza ou estenda seu roteiro para corresponder à Duração escolhida. Sentenças muito longas em clipes muito curtos podem forçar articulação não natural.
- Este modelo funciona em modo apenas de prompt. Para testes dirigidos por áudio, conecte um arquivo de áudio externo à entrada de áudio em
MagiHuman_LATENTS(#13) e ajuste seu Video Prompt para descrever expressão em vez de conteúdo falado.
Agradecimentos#
Este workflow implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos a daVinci-MagiHuman pelo daVinci-MagiHuman Workflow Source por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e repositórios vinculados abaixo.
Recursos#
- daVinci-MagiHuman/Workflow Source
- Docs / Release Notes: daVinci-MagiHuman Workflow Source
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.