
Animação Controlável em Vídeo AI: Fluxo de Trabalho WanVideo + TTM Motion Control para ComfyUI#
Este fluxo de trabalho por mickmumpitz traz a Animação Controlável em Vídeo AI para o ComfyUI usando uma abordagem guiada por movimento e sem treinamento. Ele combina a difusão de imagem para vídeo do WanVideo com orientação latente Time‑to‑Move (TTM) e máscaras sensíveis à região para que você possa direcionar como os sujeitos se movem enquanto preserva a identidade, textura e continuidade da cena.
Você pode começar de uma base de vídeo ou de dois quadros-chave, adicionar máscaras de região que focam o movimento onde você deseja, e conduzir trajetórias sem nenhum ajuste fino. O resultado é uma Animação Controlável em Vídeo AI precisa e repetível, adequada para tomadas direcionadas, sequenciamento de movimento de objetos e edições criativas personalizadas.
Modelos principais no fluxo de trabalho de Animação Controlável em Vídeo AI do Comfyui#
- Wan2.2 I2V A14B (ALTO/BAIXO). O modelo de difusão de imagem para vídeo principal que sintetiza movimento e coerência temporal a partir de prompts e referências visuais. Duas variantes equilibram fidelidade (ALTO) e agilidade (BAIXO) para diferentes intensidades de movimento. Os arquivos de modelo são hospedados nas coleções comunitárias WanVideo no Hugging Face, por exemplo, distribuições WanVideo de Kijai. Links: Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA. Um adaptador leve que aperta a consistência de estrutura e movimento ao compor Animação Controlável em Vídeo AI com Wan2.2. Ele ajuda a reter a geometria do sujeito sob pistas de movimento mais fortes. Link: Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE. O codificador automático de vídeo usado para codificar quadros em latentes e decodificar as saídas do amostrador de volta em imagens sem sacrificar detalhes. Link: Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- Codificador de texto UMT5‑XXL. Fornece embeddings de texto ricos para controle guiado por prompts juntamente com pistas de movimento. Links: google/umt5-xxl, Kijai/WanVideo_comfy – pesos do codificador
- Modelos Segment Anything para máscaras de vídeo. SAM3 e SAM2 criam e propagam máscaras de região através dos quadros, permitindo orientação dependente de região que agudiza a Animação Controlável em Vídeo AI onde é importante. Links: facebook/sam3, facebook/sam2
- Qwen‑Image‑Edit 2509 (opcional). Uma fundação de edição de imagem e um LoRA relâmpago para limpeza rápida de quadros de início/fim ou remoção de objetos antes da animação. Links: QuantStack/Qwen‑Image‑Edit‑2509‑GGUF, lightx2v/Qwen‑Image‑Lightning, Comfy‑Org/Qwen‑Image_ComfyUI
- Orientação Time‑to‑Move (TTM). O fluxo de trabalho integra latentes TTM para injetar controle de trajetória de forma sem treinamento para Animação Controlável em Vídeo AI. Link: time‑to‑move/TTM
Como usar o fluxo de trabalho de Animação Controlável em Vídeo AI do Comfyui#
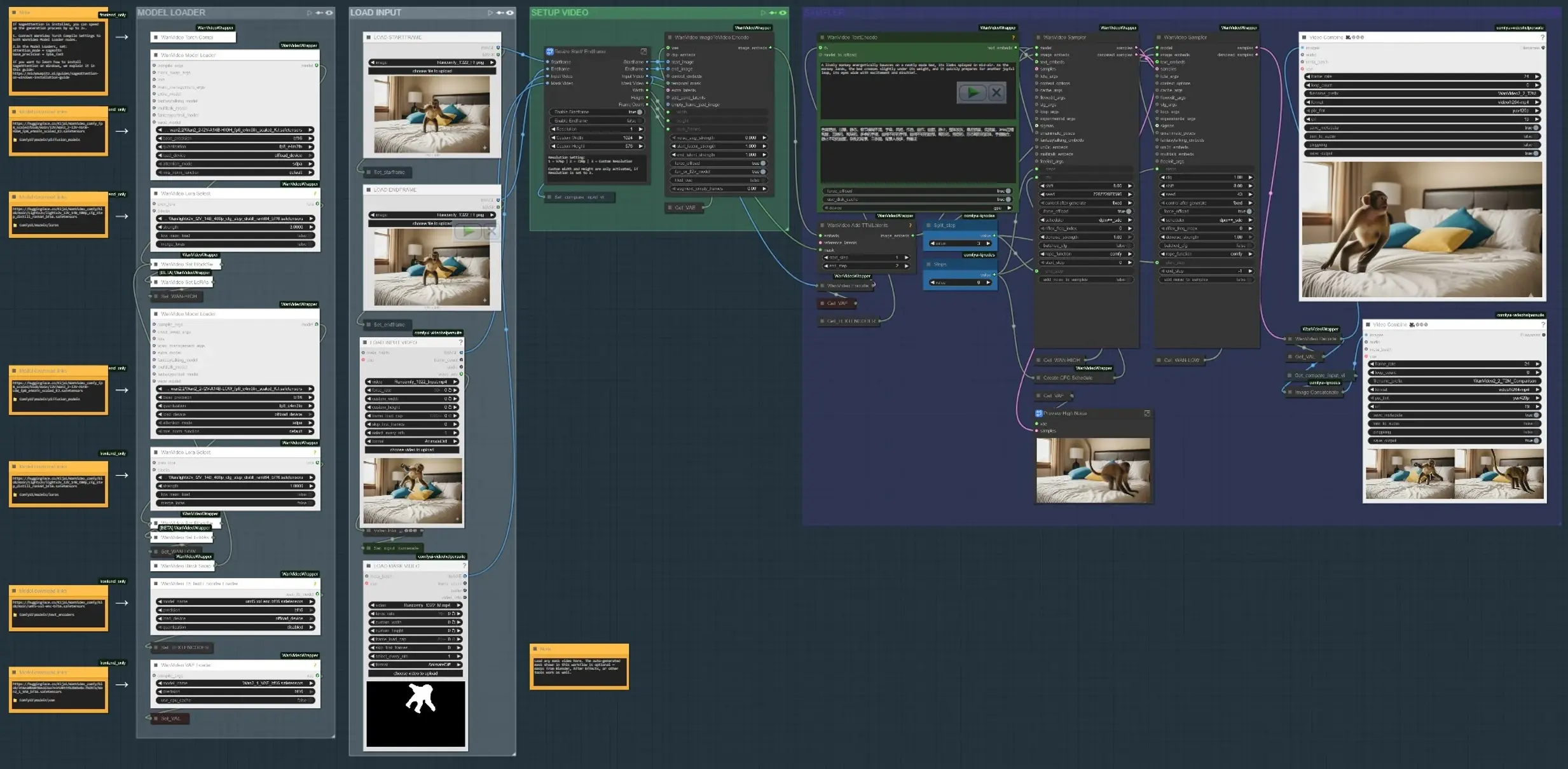
O fluxo de trabalho ocorre em quatro fases principais: carregar entradas, definir onde o movimento deve acontecer, codificar pistas de texto e movimento, e então sintetizar e pré-visualizar o resultado. Cada grupo abaixo mapeia para uma seção rotulada no gráfico.
- CARREGAR ENTRADA Use o grupo “CARREGAR VÍDEO DE ENTRADA” para trazer uma base ou clipe de referência, ou carregar quadros de início e fim se você estiver construindo movimento entre dois estados. O subgráfico “Redimensionar Quadro de Início/Fim” normaliza as dimensões e opcionalmente habilita a porta de entrada e saída. Um comparador lado a lado constrói uma saída que mostra a entrada versus o resultado para revisão rápida (
VHS_VideoCombine(#613)). - CARREGADOR DE MODELO O grupo “CARREGADOR DE MODELO” configura o Wan2.2 I2V (ALTO/BAIXO) e aplica o Lightx2v LoRA. Um caminho de troca de blocos mistura variantes para um bom equilíbrio entre fidelidade e movimento antes da amostragem. O Wan VAE é carregado uma vez e compartilhado entre codificação/decodificação. A codificação de texto usa UMT5‑XXL para forte condicionamento de prompts na Animação Controlável em Vídeo AI.
- MÁSCARA DE SUJEITO SAM3/SAM2 Em “MÁSCARA DE SUJEITO SAM3” ou “MÁSCARA DE SUJEITO SAM2”, clique em um quadro de referência, adicione pontos positivos e negativos, e propague máscaras através do clipe. Isso gera máscaras temporalmente consistentes que limitam edições de movimento ao sujeito ou região que você escolher, permitindo orientação dependente de região. Você também pode ignorar e carregar seu próprio vídeo de máscara; máscaras do Blender/After Effects funcionam bem quando você deseja controle desenhado por artista.
- PREPARAÇÃO DE QUADRO DE INÍCIO/FIM (opcional) Os grupos “QUADRO DE INÍCIO – REMOÇÃO QWEN” e “QUADRO DE FIM – REMOÇÃO QWEN” fornecem uma passagem de limpeza opcional em quadros específicos usando Qwen‑Image‑Edit. Use-os para remover aparelhamento, bastões ou artefatos da base que poderiam poluir as pistas de movimento. O recorte e preenchimento costura a edição de volta na imagem completa para uma base limpa.
- CODIFICAR TEXTO + MOVIMENTO Os prompts são codificados com UMT5‑XXL em
WanVideoTextEncode(#605). As imagens de quadro de início/fim são transformadas em latentes de vídeo emWanVideoImageToVideoEncode(#89). Latentes de movimento TTM e uma máscara temporal opcional são mesclados viaWanVideoAddTTMLatents(#104) para que o amostrador receba pistas semânticas (texto) e de trajetória, central para a Animação Controlável em Vídeo AI. - AMOSTRADOR E PRÉ-VISUALIZAÇÃO O amostrador Wan (
WanVideoSampler(#27) eWanVideoSampler(#90)) remove ruído dos latentes usando um conjunto de relógios duplo: um caminho governa dinâmicas globais enquanto o outro preserva a aparência local. Passos e uma agenda CFG configurável moldam a intensidade do movimento versus a fidelidade. O resultado é decodificado em quadros e salvo como um vídeo; uma saída de comparação ajuda a avaliar se sua Animação Controlável em Vídeo AI corresponde ao briefing.
Nós principais no fluxo de trabalho de Animação Controlável em Vídeo AI do Comfyui#
WanVideoImageToVideoEncode(#89) Codifica imagens de quadro de início/fim em latentes de vídeo que semeiam a síntese de movimento. Ajuste apenas ao mudar a resolução base ou contagem de quadros; mantenha-os alinhados com sua entrada para evitar esticar. Se você usar um vídeo de máscara, assegure-se de que suas dimensões correspondam ao tamanho do latente codificado.WanVideoAddTTMLatents(#104) Funde latentes de movimento TTM e máscaras temporais na corrente de controle. Alterne a entrada da máscara para restringir o movimento ao seu sujeito; deixando-a vazia aplica movimento globalmente. Use isso quando quiser Animação Controlável em Vídeo AI específica de trajetória sem afetar o fundo.SAM3VideoSegmentation(#687) Colete alguns pontos positivos e negativos, escolha um quadro de trilha, e então propague através do clipe. Use a saída de visualização para validar a deriva da máscara antes da amostragem. Para fluxos de trabalho sensíveis à privacidade ou offline, mude para o grupo SAM2 que não requer bloqueio de modelo.WanVideoSampler(#27) O removedor de ruído que equilibra movimento e identidade. Combine “Passos” com a lista de agenda CFG para aumentar ou relaxar a força do movimento; força excessiva pode superar a aparência, enquanto pouca força subentrega movimento. Quando as máscaras estão ativas, o amostrador concentra atualizações dentro da região, melhorando a estabilidade para Animação Controlável em Vídeo AI.
Extras opcionais#
- Para iterações rápidas, comece com o modelo LOW Wan2.2, ajuste o movimento com o TTM, e depois troque para o HIGH para a passagem final para recuperar a textura.
- Use vídeos de máscara desenhados por artistas para silhuetas complexas; o carregador aceita máscaras externas e as redimensionará para corresponder.
- Os interruptores “quadro de início/fim” permitem bloquear visualmente o primeiro ou último quadro, útil para transições contínuas em edições mais longas.
- Se disponível em seu ambiente, habilitar atenção otimizada (por exemplo, SageAttention) pode acelerar significativamente a amostragem.
- Combine a taxa de quadros de saída com a fonte no nó de combinação para evitar diferenças de tempo percebidas em Animação Controlável em Vídeo AI.
Este fluxo de trabalho oferece controle de movimento sensível à região e sem treinamento, combinando prompts de texto, latentes TTM e segmentação robusta. Com algumas entradas direcionadas, você pode dirigir Animação Controlável em Vídeo AI sofisticada e pronta para produção enquanto mantém os sujeitos no modelo e as cenas coerentes.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos sinceramente a Mickmumpitz, que é o criador da Animação Controlável em Vídeo AI para o tutorial/post, e a equipe time-to-move por TTM por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e repositórios vinculados abaixo.
Recursos#
- Patreon/Animação Controlável em Vídeo AI
- Documentos / Notas de Lançamento: Mickmumpitz Patreon post
- time-to-move/TTM
- GitHub: time-to-move/TTM
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.