
Segment Anything V2, também conhecido como SAM2, é um modelo de IA revolucionário desenvolvido pela Meta AI que revoluciona a segmentação de objetos tanto em imagens quanto em vídeos.
O que é o Segment Anything V2 (SAM2)?#
Segment Anything V2 é um modelo de IA de ponta que permite a segmentação perfeita de objetos em imagens e vídeos. É o primeiro modelo unificado capaz de lidar com tarefas de segmentação de imagens e vídeos com precisão e eficiência excepcionais. O Segment Anything V2 (SAM2) baseia-se no sucesso de seu predecessor, o Segment Anything Model (SAM), estendendo suas capacidades de prompt para o domínio de vídeos.
Com o Segment Anything V2 (SAM2), os usuários podem selecionar um objeto em uma imagem ou quadro de vídeo usando vários métodos de entrada, como clique, caixa delimitadora ou máscara. O modelo então segmenta inteligentemente o objeto selecionado, permitindo a extração e manipulação precisas de elementos específicos dentro do conteúdo visual.
Destaques do Segment Anything V2 (SAM2)#
- Desempenho de Ponta: O SAM2 supera os modelos existentes no campo da segmentação de objetos tanto em imagens quanto em vídeos. Ele estabelece um novo padrão de precisão e exatidão, superando o desempenho de seu predecessor, SAM, em tarefas de segmentação de imagens.
- Modelo Unificado para Imagens e Vídeos: O SAM2 é o primeiro modelo a fornecer uma solução unificada para segmentar objetos em imagens e vídeos. Essa integração simplifica o fluxo de trabalho para artistas de IA, pois eles podem usar um único modelo para várias tarefas de segmentação.
- Capacidades Aprimoradas de Segmentação de Vídeo: O SAM2 se destaca na segmentação de objetos em vídeos, particularmente no rastreamento de partes de objetos. Ele supera os modelos de segmentação de vídeo existentes, oferecendo melhor precisão e consistência na segmentação de objetos ao longo dos quadros.
- Destaques da Segmentação A. Tempo de Interação Reduzido: Comparado aos métodos interativos de segmentação de vídeo existentes, o SAM2 requer menos tempo de interação dos usuários. Essa eficiência permite que os artistas de IA se concentrem mais em sua visão criativa e gastem menos tempo em tarefas de segmentação manual.
- Design Simples e Inferência Rápida: Apesar de suas capacidades avançadas, o SAM2 mantém um design arquitetônico simples e oferece velocidades rápidas de inferência. Isso garante que os artistas de IA possam integrar o SAM2 em seus fluxos de trabalho sem comprometer o desempenho ou a eficiência.
Como o Segment Anything V2 (SAM2) Funciona#
O SAM2 estende a capacidade de prompt do SAM para vídeos, introduzindo um módulo de memória por sessão que captura informações do objeto alvo, permitindo o rastreamento de objetos ao longo dos quadros, mesmo com desaparecimentos temporários. A arquitetura de streaming processa quadros de vídeo um de cada vez, comportando-se como o SAM para imagens quando o módulo de memória está vazio. Isso permite o processamento de vídeo em tempo real e a generalização natural das capacidades do SAM. O SAM2 também suporta correções interativas de previsão de máscara com base em prompts do usuário. O modelo utiliza uma arquitetura de transformador com memória de streaming e é treinado no conjunto de dados SA-V, o maior conjunto de dados de segmentação de vídeo coletado usando um motor de dados com modelo no loop que melhora tanto o modelo quanto os dados através da interação do usuário.
Como usar o Segment Anything V2 (SAM2) no ComfyUI#
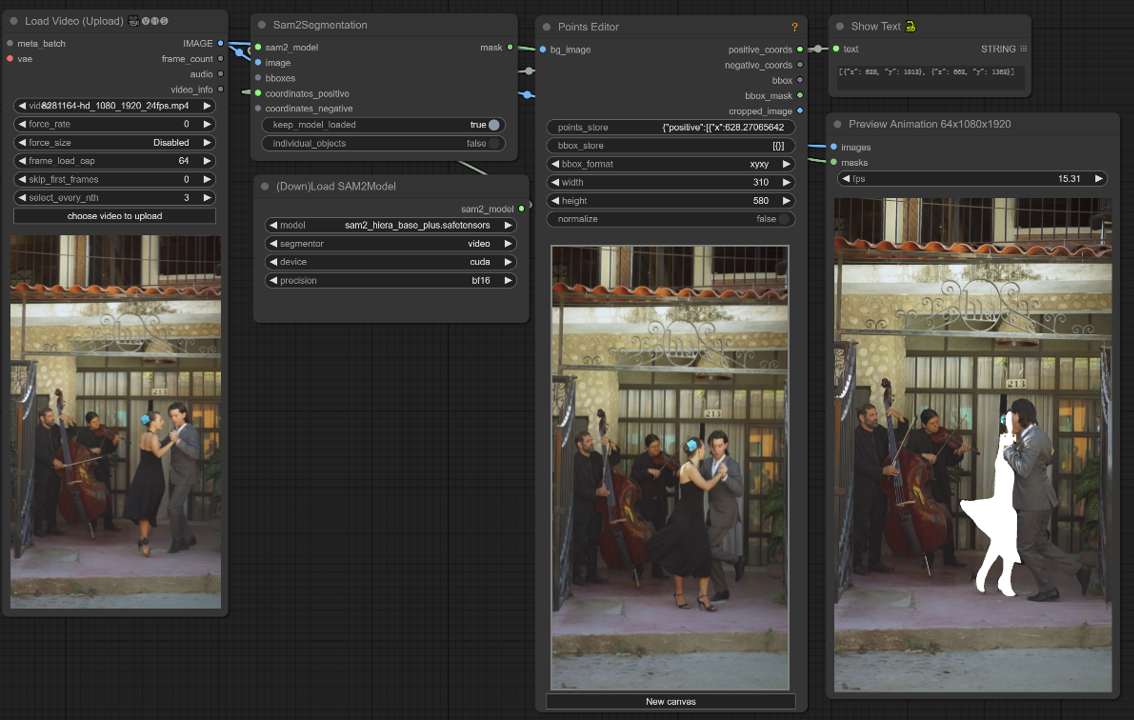
Este fluxo de trabalho do ComfyUI suporta a seleção de um objeto em um quadro de vídeo usando um clique/ponto.
1. Carregar Vídeo (Upload)#
Carregamento de Vídeo: Selecione e carregue o vídeo que deseja processar.

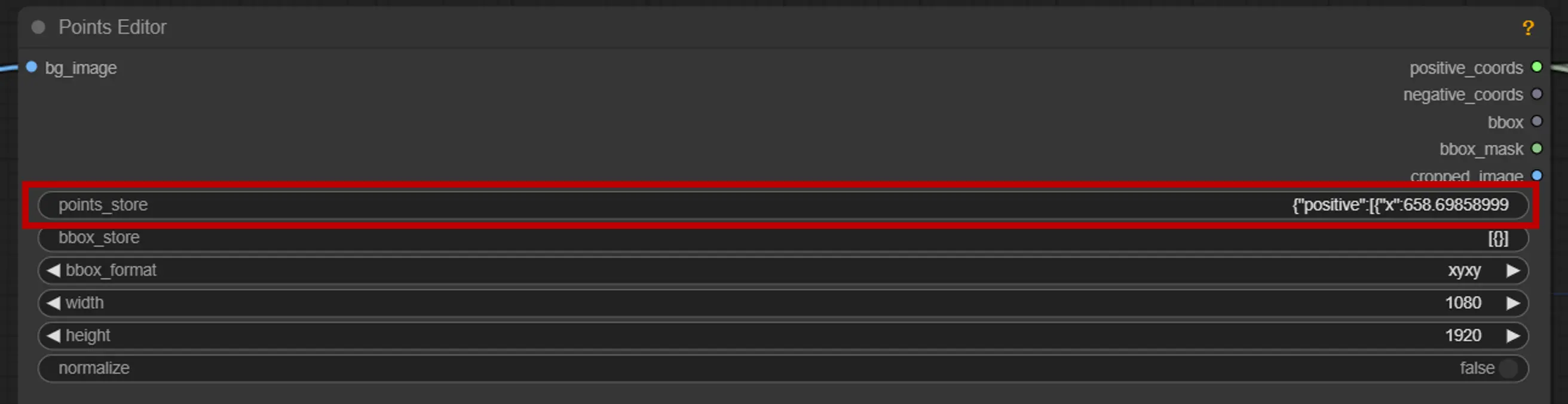
2. Editor de Pontos#
ponto chave: Coloque três pontos chave na tela—positive0, positive1 e negative0:
positive0 e positive1 marcam as regiões ou objetos que você deseja segmentar.
negative0 ajuda a excluir áreas indesejadas ou distrações.

points_store: Permite adicionar ou remover pontos conforme necessário para refinar o processo de segmentação.
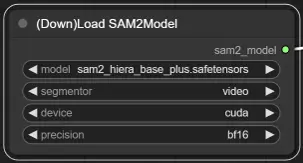
3. Seleção do Modelo SAM2#
Opções de Modelo: Escolha entre os modelos SAM2 disponíveis: tiny, small, large ou base_plus. Modelos maiores fornecem melhores resultados, mas requerem mais tempo de carregamento.
Para mais informações, por favor visite Kijai ComfyUI-segment-anything-2.

