
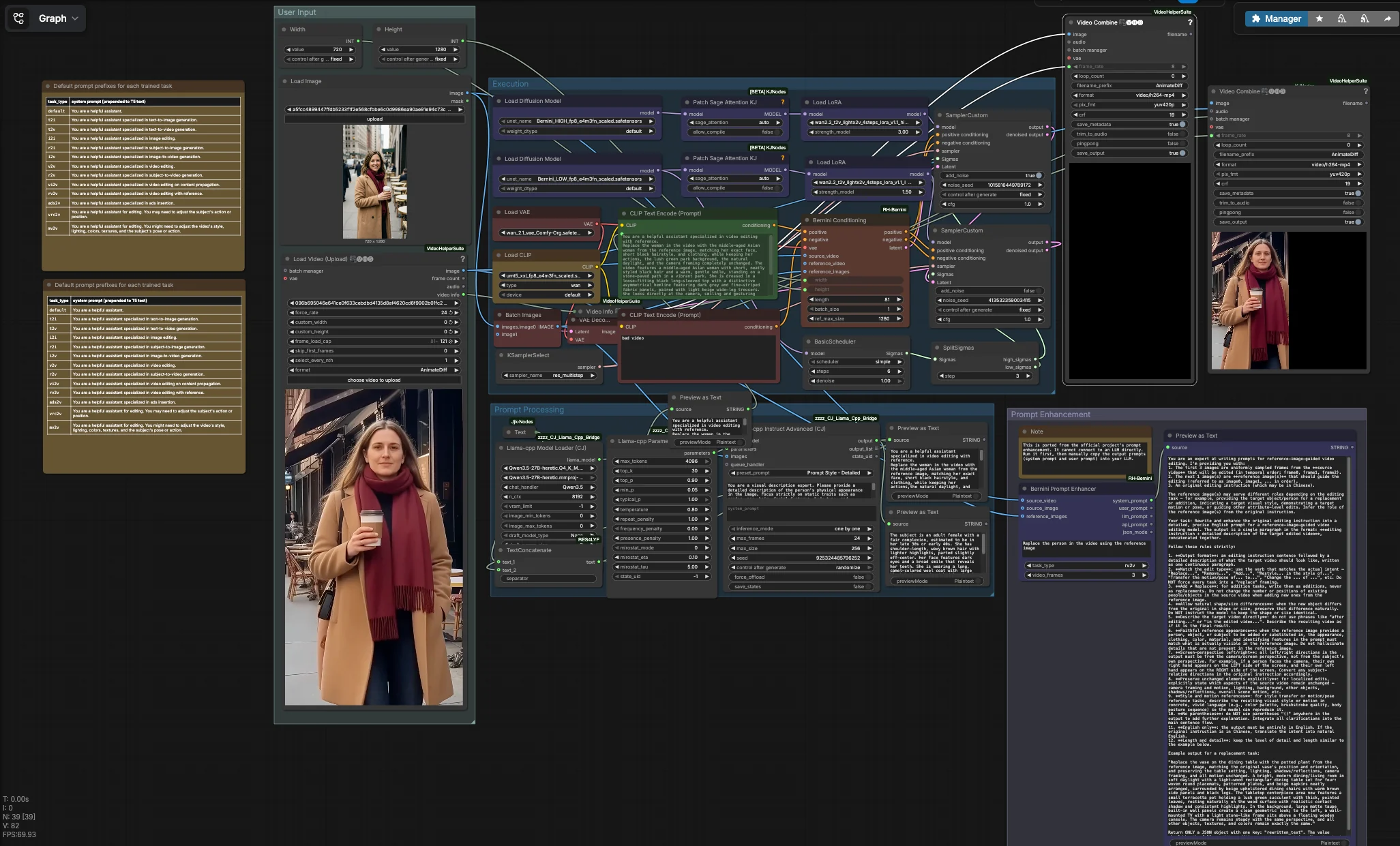
Fluxo de trabalho de geração e edição de vídeo multimodal Bernini#
Este fluxo de trabalho de geração e edição de vídeo multimodal Bernini é um pipeline ComfyUI pronto para uso para edição de vídeo com reconhecimento de identidade e transformação de vídeo para vídeo guiada por referência. Ele combina um vídeo de origem, uma ou mais imagens de referência e um prompt focado para preservar o movimento e o comportamento da câmera enquanto substitui ou reestiliza o sujeito. O fluxo de trabalho combina os backbones de difusão alta e baixa do Bernini com a codificação de texto estilo Wan, um VAE compatível com Bernini, LightX2V LoRAs e condicionamento específico do Bernini para que os resultados pareçam consistentes de quadro a quadro.
Construído para criadores e pesquisadores que avaliam o Bernini dentro do ComfyUI, o fluxo de trabalho se destaca na substituição de personagens, edições que preservam o movimento, imitação e geração de forma curta ciente da câmera. Ele exporta um MP4 editado mais uma comparação lado a lado opcional, facilitando a revisão do impacto do seu prompt e conjunto de referências. Ao longo deste README, o termo fluxo de trabalho de geração e edição de vídeo multimodal Bernini refere-se a este gráfico de ponta a ponta.
Modelos-chave no fluxo de trabalho de geração e edição de vídeo multimodal Bernini no ComfyUI#
- Família de modelos de difusão Bernini ByteDance (backbones ALTO e BAIXO). Fornece as redes principais de remoção de ruído usadas em um cronograma de duas etapas: o modelo ALTO lida com estrutura sob ruído mais forte, enquanto o modelo BAIXO refina detalhes e consistência temporal. Veja o hub do modelo para pesos de referência e notas: ByteDance/Bernini.
- Codificador de texto Wan (umT5-XXL). Um codificador T5 estilo Wan que transforma sua instrução em condicionamento para Bernini; exposto no ComfyUI através de uma interface compatível com CLIP. Ativos adequados para ComfyUI estão disponíveis aqui: Kijai/WanVideo_comfy_fp8_scaled.
- VAE Wan 2.1. Realiza decodificação latente para transformar latentes sem ruído em quadros de vídeo com fidelidade de cor que corresponde ao treinamento Wan/Bernini. Um VAE pronto para ComfyUI está incluído no mesmo pacote de ativos: Kijai/WanVideo_comfy_fp8_scaled.
- Par de LoRA LightX2V (high_noise e low_noise). Adaptadores leves que direcionam o Bernini para um movimento estável enquanto preservam a identidade de referência entre os quadros. Os pesos LoRA FP8 fornecidos estão alinhados com a amostragem de duas etapas usada neste fluxo de trabalho e são empacotados com os ativos Bernini acima: Kijai/WanVideo_comfy_fp8_scaled.
Como usar o fluxo de trabalho de geração e edição de vídeo multimodal Bernini no ComfyUI#
Este fluxo de trabalho possui quatro grupos coordenados. Você fornece um vídeo de origem e uma ou mais imagens de referência, molda o texto de instrução, então o grupo de Execução executa uma passagem Bernini em duas fases que decodifica para quadros e monta seu vídeo de saída. Uma utilidade paralela pode gerar prompts de sistema e de usuário estruturados para escrita de prompt assistida por LLM.
Entrada do Usuário#
Carregue seu vídeo de origem com VHS_LoadVideo (#90). O nó lê o clipe e expõe seus metadados para que a renderização final herde a taxa de quadros original, o que ajuda a preservar a sensação de movimento. Adicione uma ou mais referências de identidade com LoadImage (#31); rostos frontais, bem iluminados e com expressões neutras funcionam melhor. Defina o tamanho alvo usando Width (#109) e Height (#110), idealmente correspondendo à proporção de aspecto da fonte para evitar esticamento. Um prompt negativo padrão é codificado por CLIPTextEncode (#4) para suprimir artefatos comuns em vídeo de baixa qualidade; você pode refiná-lo se necessário.
Processamento de Prompt#
Se você deseja que a instrução corresponda precisamente à identidade de referência, o gráfico pode resumir traços estáticos de suas imagens de referência usando um LLM local. llama_cpp_model_loader (#93) e llama_cpp_instruct_adv (#92) analisam imagens agrupadas por BatchImagesNode (#74) e retornam uma descrição concisa de atributos imutáveis como cabelo, idade e roupa. Essa descrição é concatenada com sua diretiva de tarefa de JjkText (#104) via TextConcatenate (#102). O resultado flui para CLIPTextEncode (#3), que se torna o condicionamento positivo para Bernini. Nós de visualização mostram o texto composto para que você possa iterar rapidamente antes de executar as etapas pesadas.
Aprimoramento de Prompt#
BerniniPromptEnhancer (#60) gera prompts "sistema" e "usuário" estruturados adaptados ao tipo de tarefa selecionado e entradas. Execute-o para obter instruções mais fortes que você pode colar em seu LLM para uma expansão de prompt mais rica; por design, ele não está conectado ao gráfico principal. Esta utilidade vem do pacote de nós personalizados Bernini: ComfyUI-RH-Bernini. Trate-o como uma ferramenta de pré-escrita para padronizar a linguagem que funciona bem com o condicionamento do Bernini.
Execução#
O caminho principal começa carregando os UNets HIGH e LOW do Bernini e anexando LightX2V LoRAs para cada etapa. BerniniConditioning (#34) funde suas codificações positivas e negativas, VAE, quadros de vídeo de origem e imagens de referência para construir um condicionamento específico do Bernini e um latente inicial alinhado à sua resolução e contagem de quadros. Um BasicScheduler (#18) cria o cronograma de remoção de ruído, então SplitSigmas (#17) o divide em intervalos HIGH e LOW. O amostrador HIGH SamplerCustom (#19) estabelece estrutura e identidade sob ruído mais forte, passando seu latente para o amostrador LOW SamplerCustom (#15) para detalhes e polimento temporal. KSamplerSelect (#27) escolhe o algoritmo de amostrador, VAEDecode (#16) transforma o latente final em quadros, e VHS_VideoCombine (#87) renderiza um MP4 que herda a taxa de quadros da fonte. Em paralelo, ImageConcanate (#97) e um segundo VHS_VideoCombine (#96) produzem uma comparação lado a lado para verificações rápidas de qualidade. I/O de vídeo e montagem são fornecidos pela Video Helper Suite: ComfyUI-VideoHelperSuite.
Nós-chave no fluxo de trabalho de geração e edição de vídeo multimodal Bernini no ComfyUI#
BerniniConditioning (#34) Constrói condicionamento nativo do Bernini combinando suas codificações de texto, VAE, vídeo de origem e imagens de referência. Também prepara o volume latente inicial e lida com dimensionamento espacial e temporal. Ajuste width e height para corresponder à sua resolução alvo e use length para controlar o número de quadros gerados. Se o sujeito de referência for pequeno na imagem, aumente ref_max_size para que o modelo perceba melhor os detalhes da identidade. Este nó faz parte do pacote personalizado do Bernini: ComfyUI-RH-Bernini.
LoraLoaderModelOnly (#11) Aplica o LightX2V high_noise LoRA ao backbone ALTO. Aumentar sua strength_model aumenta a aderência à referência na etapa estrutural, útil quando a silhueta ou características grosseiras do sujeito não correspondem ao vídeo de origem. Reduza-o se a edição se tornar muito rígida ou suprimir o movimento natural. Use em conjunto com o LoRA da etapa BAIXA para equilibrar fidelidade e fluidez.
LoraLoaderModelOnly (#29) Aplica o LightX2V low_noise LoRA ao backbone BAIXO. Este LoRA refina texturas como cabelo, pele e roupa enquanto mantém o movimento definido pela etapa ALTA. Se os detalhes da identidade se desviarem entre os quadros, aumente ligeiramente a força; se as texturas ficarem muito nítidas ou parecerem superajustadas, reduza-a. Junto com o LoRA da etapa ALTA, forma um par complementar.
SplitSigmas (#17) Divide o cronograma de remoção de ruído em intervalos ALTO e BAIXO. Mover a divisão mais cedo resulta em edições mais suaves que mantêm mais do vídeo original, enquanto movê-la mais tarde concede à etapa ALTA mais influência para substituições mais fortes. Ajuste a divisão quando você mudar prompts ou forças de LoRA para que ambas as etapas permaneçam equilibradas. Este controle é especialmente útil para edições que preservam o movimento e a câmera.
KSamplerSelect (#27) Seleciona o algoritmo de amostrador usado por ambas as etapas de remoção de ruído. Alguns amostradores favorecem a estabilidade e suavidade temporal, enquanto outros enfatizam detalhes ou velocidade. Se você notar cintilação, experimente um amostrador conhecido por consistência; se precisar de nitidez extra, experimente um algoritmo que injete mais variância. Mantenha a mesma escolha para ambas as etapas para manter um comportamento previsível.
VHS_VideoCombine (#87) Codifica quadros decodificados em um MP4 final enquanto herda a taxa de quadros relatada por VHS_VideoInfo para que a velocidade de reprodução corresponda ao clipe de origem. Use controles de nome de arquivo para organizar execuções e habilite a salvaguarda de metadados se você planeja auditar configurações. Uma segunda instância (#96) gera uma renderização lado a lado para comparação visual rápida. Fornecido por ComfyUI-VideoHelperSuite.
Extras opcionais#
- Para tarefas críticas de identidade, forneça duas ou três imagens de referência de alta qualidade mostrando cabelo, iluminação e expressão consistentes. Use a entrada em lote para alimentá-las juntas.
- Mantenha a proporção de aspecto alvo próxima ao vídeo de origem. Grandes discrepâncias podem esticar rostos e desestabilizar o movimento.
- Se o fundo ou a câmera se desviarem, fortaleça a linguagem em sua instrução que bloqueia a posição da câmera e a cena, e reforce com um prompt negativo conciso.
- Use a exportação lado a lado ao ajustar forças de LoRA ou a divisão de sigma. Isso reduz o tempo de iteração, tornando as diferenças óbvias.
- Para testes mais rápidos, limite o número de quadros que você carrega, depois aumente quando estiver satisfeito com a correspondência de identidade e qualidade de movimento.
Este fluxo de trabalho de geração e edição de vídeo multimodal Bernini foi projetado para ser editado com segurança: comece com os padrões, itere na instrução e referências, depois ajuste finamente as forças de LoRA e a divisão de sigma para seu sujeito e cena.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos sinceramente à ByteDance pelo Bernini, RH-RunningHub pelo ComfyUI-RH-Bernini e Kosinkadink pelo ComfyUI-VideoHelperSuite por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- RunningHub/Bernini Multimodal Video Generation and Editing (ComfyUI Workflow)
- Documentos / Notas de Lançamento: Referência do fluxo de trabalho RunningHub
- RunComfy/Cloud Save workflow
- Documentos / Notas de Lançamento: Fluxo de trabalho RunComfy Cloud Save
- ByteDance/Bernini-R
- GitHub: bytedance/Bernini
- Hugging Face: ByteDance/Bernini-R
- arXiv: arXiv:2605.22344
- Documentos / Notas de Lançamento: Fonte do modelo Bernini ByteDance
- Kijai/WanVideo_comfy_fp8_scaled (Ativos Bernini)
- Hugging Face: Kijai/WanVideo_comfy_fp8_scaled
- Documentos / Notas de Lançamento: Ativos do modelo fp8 Bernini ComfyUI Kijai
- RH-RunningHub/ComfyUI-RH-Bernini
- GitHub: RH-RunningHub/ComfyUI-RH-Bernini
- Documentos / Notas de Lançamento: Nós personalizados Bernini RunComfy
- Kosinkadink/ComfyUI-VideoHelperSuite
- GitHub: Kosinkadink/ComfyUI-VideoHelperSuite
- Documentos / Notas de Lançamento: Pacote de Ajuda de Vídeo ComfyUI
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.

