
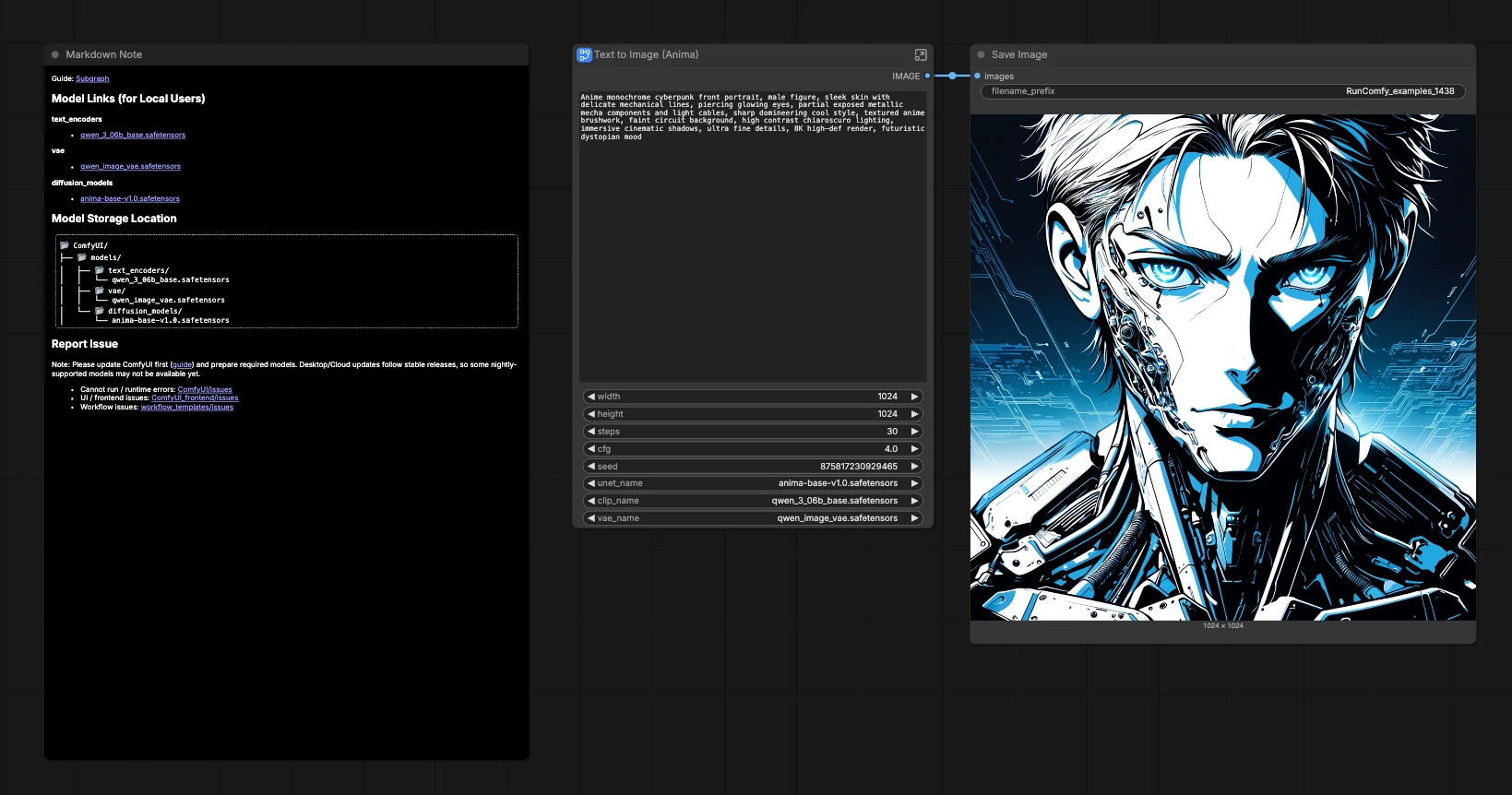






Anima Base v1 ComfyUI: fluxo de trabalho de texto para imagem de anime cyberpunk#
Este template é um fluxo de trabalho compacto e oficial do Anima Base v1 ComfyUI para gerar retratos de anime de alto contraste e ilustrações estilizadas a partir de um único prompt. Ele é ajustado para traços limpos, iluminação cinematográfica e vibrações cyberpunk, mantendo o gráfico mínimo para que você possa focar na criatividade em vez de na fiação.
Alimentado pela CircleStone Labs Anima Base v1.0 com codificação de texto Qwen e o Qwen Image VAE, o fluxo de trabalho expõe exatamente os controles que você precisa para iteração: prompt, configurações do sampler, resolução, seed e seleção de modelo. É um ponto de partida rápido para arte de personagem de anime, retratos cyberpunk e estudos de ilustração orientados por prompts.
Modelos principais no fluxo de trabalho Anima Base v1 ComfyUI#
- Modelo de difusão CircleStone Labs Anima Base v1.0. O núcleo UNet que sintetiza imagens latentes com traços de anime nítidos, sombreado de alto contraste e detalhes estilizados. Ele fornece o pré-requisito visual que faz os retratos cyberpunk e a arte de personagens se destacarem. Model card
- Codificador de texto base Qwen3 0.6B. Traduz seu prompt de texto em embeddings que o modelo de difusão entende, melhorando a fidelidade do assunto e o controle de estilo para prompts de anime. Distribuído com o pacote Anima como qwen_3_06b_base.safetensors. Files
- Qwen Image VAE. Decodifica o latente final em uma imagem de resolução total enquanto preserva o contraste e a resposta de cor do Anima. Enviado como qwen_image_vae.safetensors. Files
Como usar o fluxo de trabalho Anima Base v1 ComfyUI#
O fluxo de trabalho é executado em uma única passagem: seu prompt é codificado, uma imagem latente é amostrada, então decodificada para pixels e salva. Três grupos organizam a experiência para que você possa se mover rapidamente da ideia ao resultado.
Modelo#
Use este grupo para escolher o modelo de difusão Anima Base v1.0, o codificador de texto Qwen e o Qwen Image VAE. Manter esses três alinhados mantém a aparência e o contraste pretendidos do Anima. Você pode trocar qualquer um deles para experimentação, mas misturar ativos não-Anima mudará cores, texturas e renderização de bordas. Se você planeja comparar variantes, mantenha o seed fixo para que as diferenças reflitam a escolha do modelo e não o ruído aleatório.
Tamanho da Imagem#
Defina a largura e a altura para a tela latente. Molduras quadradas são adequadas para retratos e facilitam o julgamento da iluminação e do estilo, enquanto proporções verticais como 3:4 ou 4:5 enfatizam os personagens. Tamanhos maiores melhoram os detalhes, mas aumentam o uso de memória e o tempo de amostragem. Comece modesto, encontre uma aparência que você ame, depois aumente para finais.
Prompt#
Insira sua descrição criativa no prompt positivo. Para anime cyberpunk, combine assunto + estilo + iluminação, por exemplo: "retrato de anime cyberpunk estilizado, acentos de neon, metal reflexivo, luz de borda cinematográfica." O prompt negativo interno está pré-preenchido com supressores de qualidade comuns para reduzir artefatos e bordas borradas, enquanto o campo de texto exposto mantém o prompt criativo principal fácil de editar.
Amostragem e saída#
Nos bastidores, o sampler gera a imagem latente usando seus steps, cfg e seed. Mais passos adicionam refinamento, enquanto cfg equilibra a aderência ao prompt contra o pré-requisito artístico do modelo. O VAE decodifica o latente para RGB, e a imagem é salva com um nome base para que você possa rastrear iterações enquanto explora variações.
Nós principais no fluxo de trabalho Anima Base v1 ComfyUI#
KSampler(#19). O motor que transforma seu condicionamento em uma imagem latente. Aumentestepspara traços mais intrincados e microdetalhes; ajustecfgmais baixo para resultados mais livres e orientados por humor ou mais alto para seguir o prompt de forma mais rigorosa; traveseedpara reproduzir uma composição enquanto você altera a redação ou configurações.CLIP Text Encode (Positive Prompt)(#11). Converte seu texto em embeddings para o modelo. Frases concisas e descritivas tendem a produzir as bordas de anime mais limpas. Misture termos de assunto, meio e iluminação, depois itere trocando uma única palavra por execução para aprender o que impulsiona a aparência.CLIP Text Encode (Negative Prompt)(#12). Afasta o sampler de traços indesejados. Mantenha os filtros de qualidade incluídos e adicione exclusões específicas de alvo como "baixo contraste", "pele suavizada demais" ou "flare de lente" quando necessário.EmptyLatentImage(#28). Define o tamanho da tela. Use quadrado para bustos de personagens, verticais altos para fotos de corpo inteiro ou molduras mais largas para contexto ambiental. Se você mudar a proporção durante o projeto, espere que a composição se reorganize mesmo com o mesmo seed.UNETLoader(#44). Carrega os pesos de difusão Anima Base v1.0. Este nó é a maneira mais rápida de testar variantes de modelo compatíveis enquanto mantém tudo o mais constante.VAELoader(#15). Seleciona o Qwen Image VAE. Permanecer com o VAE emparelhado preserva o contraste e o mapeamento de cores do Anima; trocar VAEs mudará sutilmente tons e suavidade de bordas.
Extras opcionais#
- Comece com prompts curtos, depois adicione um modificador de cada vez para aprender como o Anima Base v1 ComfyUI responde.
- Mantenha
seedfixo enquanto ajusta prompts ecfg, depois mude para explorar novas composições. - Para sombreamento gráfico de anime nítido, favoreça termos de iluminação claros como "luz de borda dura" ou "chiaroscuro profundo."
- Use proporções verticais para retratos de personagens e quadrado para avatares ou miniaturas sociais para reduzir surpresas de corte.
- Se você vir banding ou cores lavadas, tente um pequeno ajuste no
cfgou refine a redação do prompt para direcionar o contraste. - Nomeie iterações em
SaveImagecom um prefixo de projeto para que os lotes sejam classificados de forma limpa ao comparar resultados.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos ao Comfy Org pelo template de fluxo de trabalho de Texto para Imagem e à CircleStone Labs pelo Anima e Anima Base v1.0 (Diffusers). Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Comfy Org/Anima Base v1 Texto para Imagem
- GitHub: Comfy-Org
- Docs / Notas de Lançamento: Comfy workflow source
- CircleStone Labs/Anima
- Hugging Face: circlestone-labs/Anima
- CircleStone Labs/Anima Base v1.0 (Diffusers)
- Hugging Face: circlestone-labs/Anima-Base-v1.0-Diffusers
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.

