
ACE-Step 1.5XL Base texto para música: Fluxo de trabalho de prompt para música para ComfyUI#
Este fluxo de trabalho transforma descrições em linguagem natural em áudio finalizado usando a família de difusão ACE-Step 1.5XL Base. Ele combina o modelo base com seu ACE Step VAE e codificadores de texto Qwen duplos para manter os resultados firmemente no campo musical em vez de TTS ou fala. Se você deseja música AI orientada por prompt com estrutura, tempos e instrumentação previsíveis, este pipeline ACE-Step 1.5XL Base texto para música é uma configuração focada e mínima que leva você da ideia ao MP3 rapidamente.
Projetado para produtores, designers de som e criadores, o gráfico enfatiza a clareza: escolha modelos, defina uma duração, escreva um prompt musical, depois gere e salve. O fluxo de trabalho ACE-Step 1.5XL Base texto para música é compacto o suficiente para iteração rápida enquanto permanece expressivo para arranjos detalhados, tons e tempos.
Modelos principais no fluxo de trabalho Comfyui ACE-Step 1.5XL Base texto para música#
- ACE-Step 1.5 XL Base (bf16) modelo de difusão. A espinha dorsal generativa que elimina ruídos de latentes de áudio em frases e texturas musicais coerentes. Model file
- ACE Step 1.5 VAE. O autoencoder variacional emparelhado que codifica/decodifica entre espaço latente e domínio de forma de onda, preservando timbre e balanços de mixagem. Model file
- Qwen 4B ACE15 codificador de texto. Um grande codificador de texto adaptado para ACE que captura semânticas musicais ricas, estrutura e pistas de arranjo do prompt. Model file
- Qwen 0.6B ACE15 codificador de texto. Um codificador ACE adaptado mais leve que prioriza velocidade e eficiência de recursos enquanto mantém forte compreensão do prompt. Model file
Como usar o fluxo de trabalho Comfyui ACE-Step 1.5XL Base texto para música#
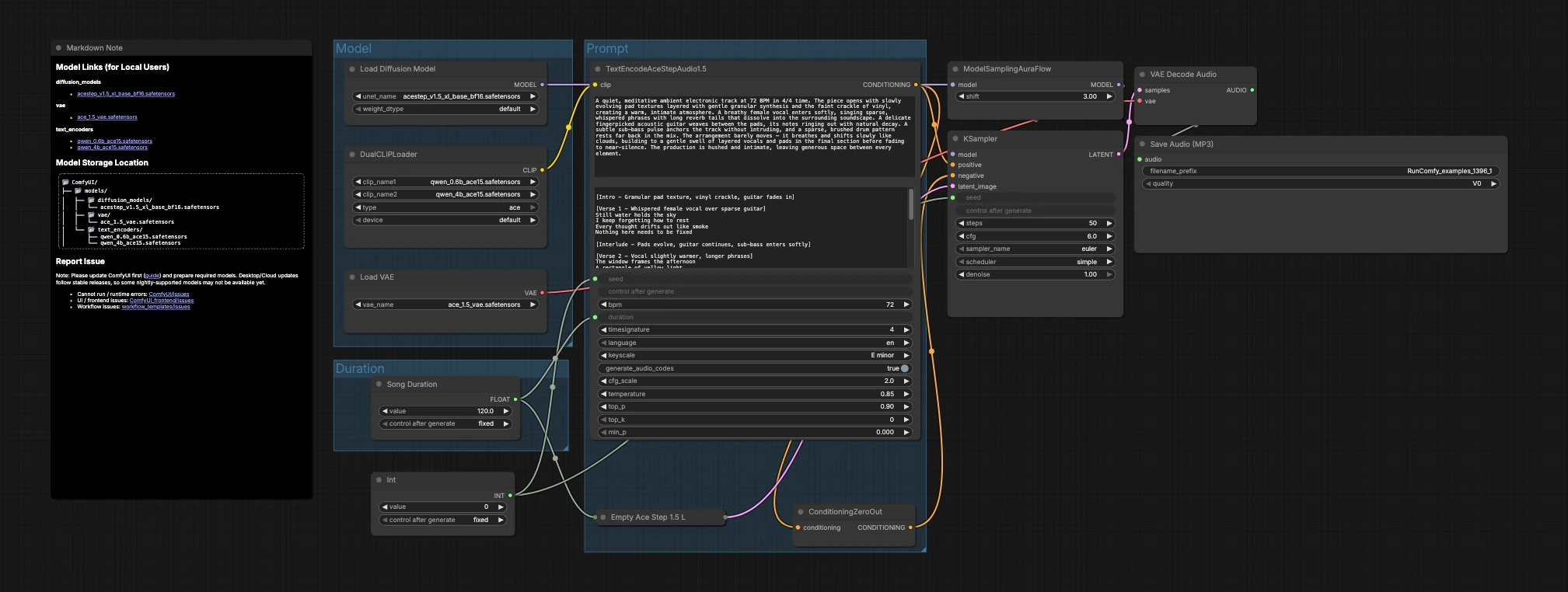
O gráfico está organizado em três grupos que fluem para geração e exportação: Modelo, Duração e Prompt. Você carrega os modelos, escolhe um comprimento alvo, descreve a música, então o sampler cria latentes que o VAE decodifica em áudio.
Modelo#
Este grupo carrega os ativos principais. UNETLoader (#104) seleciona o ponto de verificação de difusão ACE-Step 1.5 XL Base, e VAELoader (#106) carrega o ACE Step 1.5 VAE correspondente para que a qualidade de decodificação esteja alinhada com o treinamento. DualCLIPLoader (#105) traz ambos os codificadores Qwen ACE15; o fluxo de trabalho os usa em conjunto para que prompts de texto ricos se traduzam em condicionamento musical forte.
Duração#
Aqui você decide a duração da peça. Song Duration (#99) define o comprimento alvo em segundos e o encaminha para que a tela latente e o condicionamento de texto concordem. PrimitiveInt (#109) fornece uma semente, permitindo que você bloqueie resultados exatos para reprodutibilidade ou varie para explorar alternativas.
Prompt#
Aqui a linguagem se torna música. Escreva sua descrição em TextEncodeAceStepAudio1.5 (#94), incluindo metadados musicais úteis como tempo (BPM), compasso, tonalidade, instrumentação, arranjo, presença vocal e notas de mixagem. O nó emite o condicionamento positivo; ConditioningZeroOut (#47) fornece um caminho negativo neutro para que a geração se concentre em sua descrição. EmptyAceStep1.5LatentAudio (#98) inicializa uma linha do tempo de áudio latente para a duração escolhida. ModelSamplingAuraFlow (#78) adapta o modelo base a um agendador adequado para áudio ACE-Step. KSampler (#3) combina modelo, condicionamento, latente e semente para gerar o latente da música. VAEDecodeAudio (#18) converte o latente de volta para forma de onda, e SaveAudioMP3 (#107) grava o resultado em um arquivo MP3 pronto para compartilhar.
Nós principais no fluxo de trabalho Comfyui ACE-Step 1.5XL Base texto para música#
TextEncodeAceStepAudio1.5 (#94)#
Transforma seu prompt em condicionamento que o modelo de difusão pode seguir. Aceita detalhes musicais como tempo, assinatura de tempo, tonalidade, notas de arranjo, instrumentação, idioma e intenção vocal opcional. Para melhores resultados, seja concreto sobre gênero, sensação e colocação na mixagem, e mantenha pistas estruturais concisas para que o modelo possa manter a coerência ao longo da duração solicitada.
EmptyAceStep1.5LatentAudio (#98)#
Cria a “tela” de áudio latente para a peça. Combine seus segundos com o que você definiu em Song Duration (#99) e referenciado no codificador de texto para evitar truncamento ou preenchimento indesejado. Telas mais longas convidam a um desenvolvimento mais gradual, enquanto as mais curtas são adequadas para loops, pistas e stingers.
ModelSamplingAuraFlow (#78)#
Configura a estratégia de amostragem adaptada para áudio ACE-Step. Use como fornecido para resultados estáveis; ajuste apenas se tiver uma preferência específica de agendador, pois ele interage com a contagem de etapas e orientação em KSampler (#3).
KSampler (#3)#
Realiza a remoção de ruído que transforma o condicionamento em latentes de áudio. As alavancas principais aqui são o tipo de sampler, contagem de etapas e semente. Aumente as etapas para refinar detalhes ao custo de tempo, e mantenha a semente fixa ao comparar prompts para que você possa atribuir mudanças ao texto em vez de aleatoriedade.
DualCLIPLoader (#105)#
Carrega ambos os codificadores de texto Qwen ACE15. Se você tem acesso a ambos, comece com o codificador 4B ativo para uma compreensão mais rica da linguagem; mude para a variante 0.6B quando precisar de iterações mais rápidas ou menor uso de memória. Mantenha a escolha do codificador consistente entre tomadas ao avaliar edições sutis de prompts.
ConditioningZeroOut (#47)#
Fornece um caminho negativo neutro. Se você quiser suprimir artefatos específicos ou desviar de conteúdo falado, pode substituir isso por um nó de prompt negativo real; caso contrário, o negativo zerado mantém a geração de texto para música ACE-Step 1.5XL Base focada em sua descrição positiva.
Extras opcionais#
- Comece prompts com uma receita compacta: gênero + humor + tempo + compasso + tonalidade + instrumentação + arranjo + notas de mixagem.
- Use verbos e papéis musicais explícitos (lead, pad, bass, percussion) para que o modelo aloque espaço na mixagem e evite conteúdo semelhante a fala.
- Fixe a semente ao testar prompts A/B, depois varie a semente para explorar performances alternativas de uma ideia vencedora.
- Mantenha a duração alinhada entre
Song Duration(#99),TextEncodeAceStepAudio1.5(#94) eEmptyAceStep1.5LatentAudio(#98) para fraseado previsível. - Escolha Qwen 4B para compreensão de prompt mais rica ou 0.6B para velocidade; mantenha sua escolha constante enquanto itera para tornar as comparações justas.
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos imensamente à Comfy.org pelo fluxo de trabalho audio_ace_step1_5_xl_base, à Comfy-Org pelo modelo de difusão ACE Step 1.5 XL Base e ACE Step 1.5 VAE, e à equipe Qwen pelos codificadores de texto 0.6B e 4B ACE15 por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Comfy.org/Página de origem do fluxo de trabalho
- Documentos / Notas de Lançamento: página de fluxo de trabalho audio_ace_step1_5_xl_base
- Comfy-Org/Modelo de difusão ACE Step 1.5 XL Base
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Qwen 0.6B ACE15 codificador de texto
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Qwen 4B ACE15 codificador de texto
- Hugging Face: qwen_4b_ace15.safetensors
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.
