
Wan2.2 S2V: ComfyUI에서 단일 이미지로부터 소리-비디오 생성#
Wan2.2 S2V는 하나의 참조 이미지와 오디오 클립을 동기화된 비디오로 변환하는 소리-비디오 워크플로우입니다. Wan 2.2 모델 패밀리를 기반으로 구축되었으며, 소리나 음성을 따라가는 표현력 있는 움직임, 립싱크, 장면 역학을 원하는 창작자들을 위해 설계되었습니다. Wan2.2 S2V를 사용하여 말하는 아바타, 음악 기반 루프, 손으로 애니메이션을 만드는 것 없이도 빠른 이야기 비트를 생성할 수 있습니다.
이 ComfyUI 그래프는 오디오 기능을 텍스트 프롬프트 및 정지 이미지와 결합하여 짧은 클립을 생성한 후, 원본 오디오와 프레임을 혼합합니다. 결과는 참조 이미지의 모습을 유지하면서 오디오가 타이밍과 표현을 주도하도록 하는 컴팩트하고 신뢰할 수 있는 파이프라인입니다.
Comfyui Wan2.2 S2V 워크플로우의 주요 모델#
- Wan 2.2 S2V UNet (14B, bf16). 오디오 기능, 텍스트 조건, 참조 이미지를 융합하여 비디오 잠재변수를 생성하는 핵심 생성기.
- Wan VAE (wan_2.1_vae). 잠재 공간과 픽셀 공간 간의 인코딩/디코딩을 통해 Wan2.2 S2V 렌더에서 세부 사항과 색상 충실도를 유지합니다.
- UMT5-XXL 텍스트 인코더. 스타일과 콘텐츠에 대한 프롬프트 조건을 제공합니다; 기본 모델 카드를 참조하세요: google/umt5-xxl.
- Wav2Vec2 대형 오디오 인코더. 소리 조건 생성에 대한 강력한 음성과 리듬 기능을 추출합니다; 아키타이프 카드 참조: facebook/wav2vec2-large-960h.
Comfyui Wan2.2 S2V 워크플로우 사용 방법#
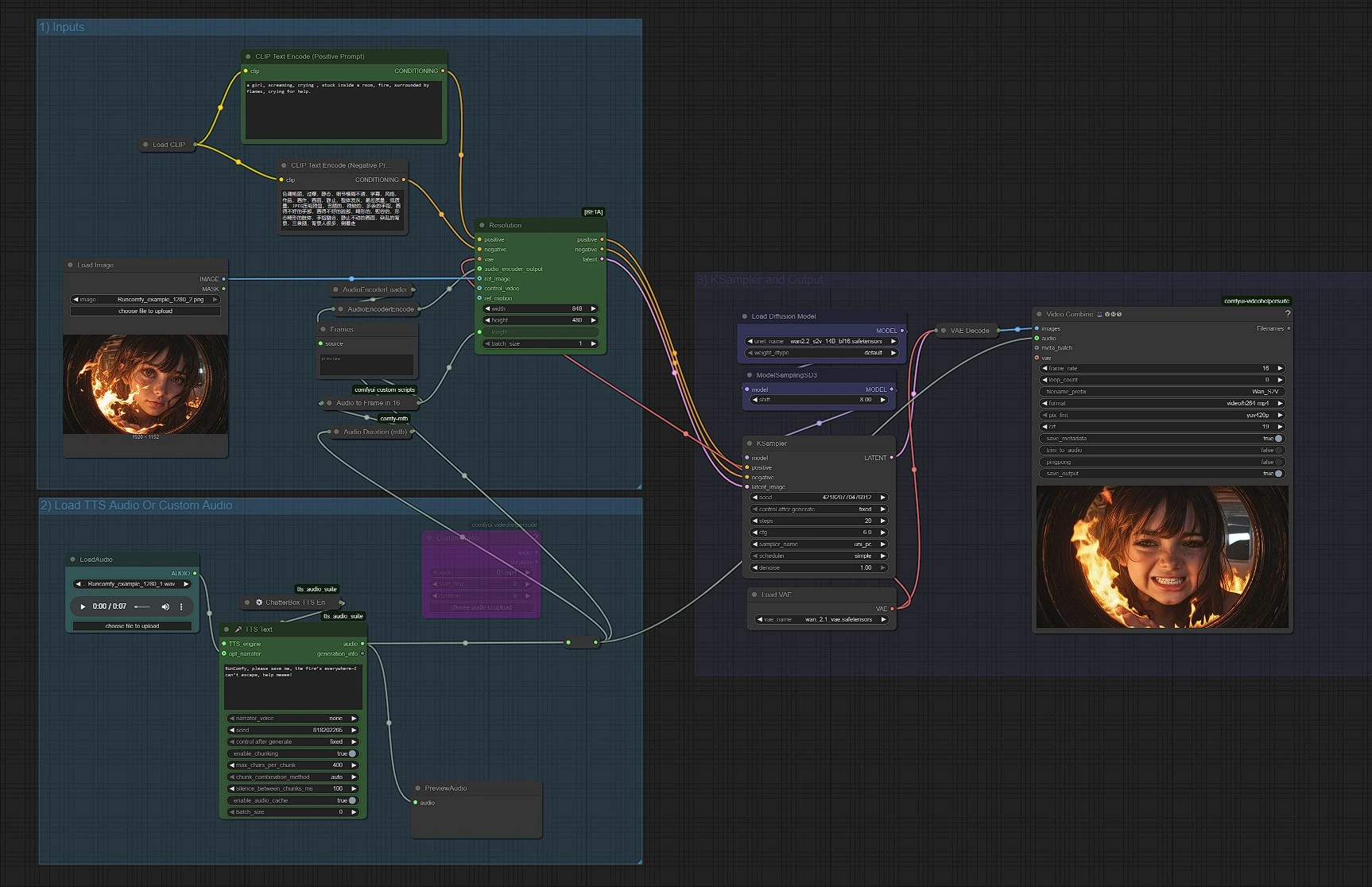
워크플로우는 세 가지 그룹으로 구성되어 있습니다. 처음부터 끝까지 실행하거나 각 단계를 필요에 따라 조정할 수 있습니다.
1) 입력#
이 그룹은 Wan의 텍스트, 이미지, VAE 구성 요소를 로드하고 프롬프트를 준비합니다. 스타일과 품질을 조정하기 위해 CLIPLoader (#38)와 CLIPTextEncode (#6)로 긍정적 프롬프트를, CLIPTextEncode (#7)로 부정적 프롬프트를 사용하세요. 참조 이미지는 LoadImage (#52)로 로드하며, 이는 Wan2.2 S2V의 정체성, 구도, 팔레트를 고정합니다. 긍정적 프롬프트는 설명적이지만 간결하게 유지하여 오디오가 움직임을 제어할 수 있도록 합니다. VAE (VAELoader (#39)) 및 모델 로더 (UNETLoader (#37))는 미리 연결되어 있으며 일반적으로 그대로 둡니다.
2) TTS 오디오 또는 사용자 지정 오디오 로드#
오디오를 제공하는 방법을 선택하세요. 빠른 테스트를 위해 UnifiedTTSTextNode (#71)로 음성을 생성하고 PreviewAudio (#65)로 미리보기하세요. 자신의 음악이나 대화를 사용하려면 로컬 파일의 경우 LoadAudio (#78)를, 업로드의 경우 VHS_LoadAudioUpload (#87)를 사용하세요; 둘 다 Reroute (#88)를 통해 다운스트림 노드가 단일 오디오 소스를 보도록 합니다. 지속 시간은 Audio Duration (mtb) (#68)에 의해 측정된 후 MathExpression|pysssss (#67)로 프레임 수로 변환됩니다, "Audio to Frame in 16 FPS"로 레이블이 붙어 있습니다. 오디오 기능은 AudioEncoderLoader (#57)와 AudioEncoderEncode (#56)에 의해 생성되며, 이들은 함께 Wan2.2 S2V 노드에 AUDIO_ENCODER_OUTPUT을 공급합니다.
3) KSampler 및 출력#
WanSoundImageToVideo (#55)는 Wan2.2 S2V의 핵심입니다. 이 노드는 프롬프트, VAE, 오디오 기능, 참조 이미지, length 정수(프레임)를 사용하여 조건부 잠재 시퀀스를 방출합니다. 해당 잠재 시퀀스는 KSampler (#3)로 전달되며, 샘플러 설정은 오디오 주도 타이밍을 존중하면서 전체적인 일관성과 세부 사항을 좌우합니다. 샘플링된 잠재는 VAEDecode (#8)에 의해 프레임으로 디코딩된 후 VHS_VideoCombine (#66)이 비디오를 조립하고 원본 오디오와 혼합하여 MP4를 생성합니다. ModelSamplingSD3 (#54)는 Wan 백본에 대한 올바른 샘플러 패밀리를 설정하는 데 사용됩니다.
Comfyui Wan2.2 S2V 워크플로우의 주요 노드#
WanSoundImageToVideo (#55)#
단일 이미지에서 오디오 동기화된 움직임을 구동합니다. ref_image를 애니메이션화하려는 초상화 또는 장면으로 설정하고, 인코더에서 audio_encoder_output을 연결하며, 프레임으로 length를 제공합니다. 더 긴 클립을 위해 length를 늘리거나 더 짧은 미리보기를 위해 줄이세요. 다른 곳에서 FPS를 변경하면 타이밍이 동기화되도록 프레임 값을 업데이트하세요.
AudioEncoderLoader (#57) 및 AudioEncoderEncode (#56)#
음성이나 음악을 Wan이 따를 수 있는 기능으로 변환하는 Wav2Vec2 기반 인코더를 로드하고 실행합니다. 립싱크를 위해 깨끗한 음성을 사용하거나 리듬감 있는 움직임을 위한 퍼커시브/비트 중심의 오디오를 사용하세요. 입력 언어나 도메인이 다를 경우, 호환 가능한 Wav2Vec2 체크포인트로 교체하여 정렬을 개선하세요.
CLIPTextEncode (#6) 및 CLIPTextEncode (#7)#
UMT5/CLIP 조건을 위한 긍정적 및 부정적 프롬프트 인코더. 긍정적 프롬프트는 주제, 스타일, 샷 용어에 집중하여 간결하게 유지하세요; 부정적 프롬프트를 사용하여 원치 않는 아티팩트를 피하세요. 지나치게 강력한 프롬프트는 오디오와 충돌할 수 있으므로, 가벼운 지침을 선호하고 Wan2.2 S2V에 움직임을 맡기세요.
KSampler (#3)#
Wan2.2 S2V 노드에 의해 생성된 잠재 시퀀스를 샘플링합니다. 샘플러 유형과 단계를 조정하여 속도를 충실도로 교환하세요; 동일한 오디오로 재현 가능한 타이밍을 원할 경우 고정된 시드를 유지하세요. 움직임이 너무 경직되거나 시끄럽게 느껴진다면, 여기에서의 작은 변화가 시간적 안정성을 눈에 띄게 개선할 수 있습니다.
VHS_VideoCombine (#66)#
최종 비디오를 생성하고 오디오를 첨부합니다. frame_rate를 의도한 FPS에 맞추고 클립 길이가 length 프레임과 일치하는지 확인하세요. 컨테이너, 픽셀 포맷, 품질 제어가 빠른 내보내기를 위해 노출되어 있으며, 편집기에서 후처리할 계획이 있을 경우 더 높은 품질을 사용하세요.
선택적 추가#
- 신원 드리프트와 잘림을 최소화하기 위해 대상 가로세로 비율에서 잘 조명된 정면 참조 이미지로 시작하세요.
- 립싱크를 위해, 입이 가려지지 않도록 하고 깨끗한 내레이션을 사용하세요; 강한 트랜지언트가 있는 음악은 비트 기반 움직임에 잘 맞습니다.
- 기본 FPS 변환은 16 fps를 가정합니다; FPS를 변경하면 "Audio to Frame in 16 FPS"의 수학을 업데이트하여 프레임이 오디오 지속 시간과 일치하도록 하세요.
- 오디오 미리보기 및 VHS 라이브 미리보기를 사용하여 빠르게 반복한 후, 타이밍이 마음에 들면 품질을 높이세요.
- 더 긴 클립은 계산 및 VRAM을 확장합니다; 정적을 잘라내거나 긴 스크립트를 짧은 장면으로 분할하여 Wan2.2 S2V로 다중 샷 비디오를 생성할 때 사용하세요.
감사의 글#
이 워크플로우는 다음의 작업 및 리소스를 구현하고 구축합니다. 우리는 Wan-Video에 대해 Wan2.2 (S2V 추론 코드 포함), Wan-AI에 대해 Wan2.2-S2V-14B, 그리고 Gao et al. (2025)에 대해 Wan-S2V: 오디오 기반 시네마틱 비디오 생성에 대한 기여와 유지에 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- Wan-Video/Wan2.2 S2V 데모
- GitHub: Wan-Video/Wan2.2
- Hugging Face: Wan-AI/Wan2.2-S2V-14B
- arXiv: Wan-S2V: 오디오 기반 시네마틱 비디오 생성
- Docs / Release Notes: Wan2.2 S2V 데모
참고: 참조된 모델, 데이터셋, 코드의 사용은 해당 저자 및 유지 관리자가 제공한 각각의 라이센스 및 조건에 따릅니다.