
ComfyUI를 위한 Wan 2.1 Ditto 비디오 리스타일 워크플로우#
이 워크플로우는 Wan 2.1 Ditto를 적용하여 입력 비디오를 재스타일링하면서 장면 구조와 모션을 유지합니다. 시네마틱, 예술적 또는 실험적인 룩을 강력한 시간적 일관성과 함께 원하는 편집자와 창작자에게 설계되었습니다. 클립을 로드하고 타겟 룩을 설명하면 Wan 2.1 Ditto가 깨끗한 스타일의 렌더링과 빠른 검토를 위한 선택적 나란히 비교를 생성합니다.
그래프는 Wan 2.1 텍스트-비디오 백본을 Ditto의 스타일 전송과 모델 레벨에서 결합하여 프레임별 필터가 아닌 프레임 전반에 걸쳐 변화가 일관되게 발생하도록 합니다. 일반적인 사용 사례에는 애니메이션 변환, 픽셀 아트, 클레이메이션, 수채화, 스팀펑크 또는 시뮬레이션-실제 편집이 포함됩니다. 이미 Wan으로 콘텐츠를 생성하는 경우, 이 Wan 2.1 Ditto 워크플로우는 믿을 수 있는 깜빡임 없는 비디오 스타일링을 위해 파이프라인에 직접 통합됩니다.
Comfyui Wan 2.1 Ditto 워크플로우의 주요 모델#
- Wan2.1-T2V-14B 텍스트-비디오 모델. 텍스트와 시각적 조건을 제공하여 시간적으로 일관된 모션을 합성하는 생성 백본 역할을 합니다.
- Wan 2.1 VAE. 비디오 잠재 변수를 인코딩하고 디코딩하여 샘플러가 압축 공간에서 작동하고 전체 해상도 프레임을 신뢰성 있게 재구성할 수 있도록 합니다.
- mT5-XXL 텍스트 인코더. 프롬프트를 장면 콘텐츠와 스타일을 조정하는 풍부한 언어 임베딩으로 변환합니다. mT5에 대한 배경 정보는 Xue et al.의 논문 mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer를 참조하십시오.
- Wan 2.1을 위한 Ditto 스타일화 모델. 강력한 시간적 일관성을 가진 견고한 글로벌 리스타일링을 제공합니다. Ditto 접근 방식과 모델 파일은 여기에서 문서화되어 있습니다: EzioBy/Ditto.
- Wan 2.1 14B를 위한 선택적 LoRA. 기본 모델을 재교육하지 않고 스타일 또는 동작 변화를 가볍게 추가합니다. Hu et al., 2021의 LoRA 방법을 따릅니다.
Comfyui Wan 2.1 Ditto 워크플로우 사용 방법#
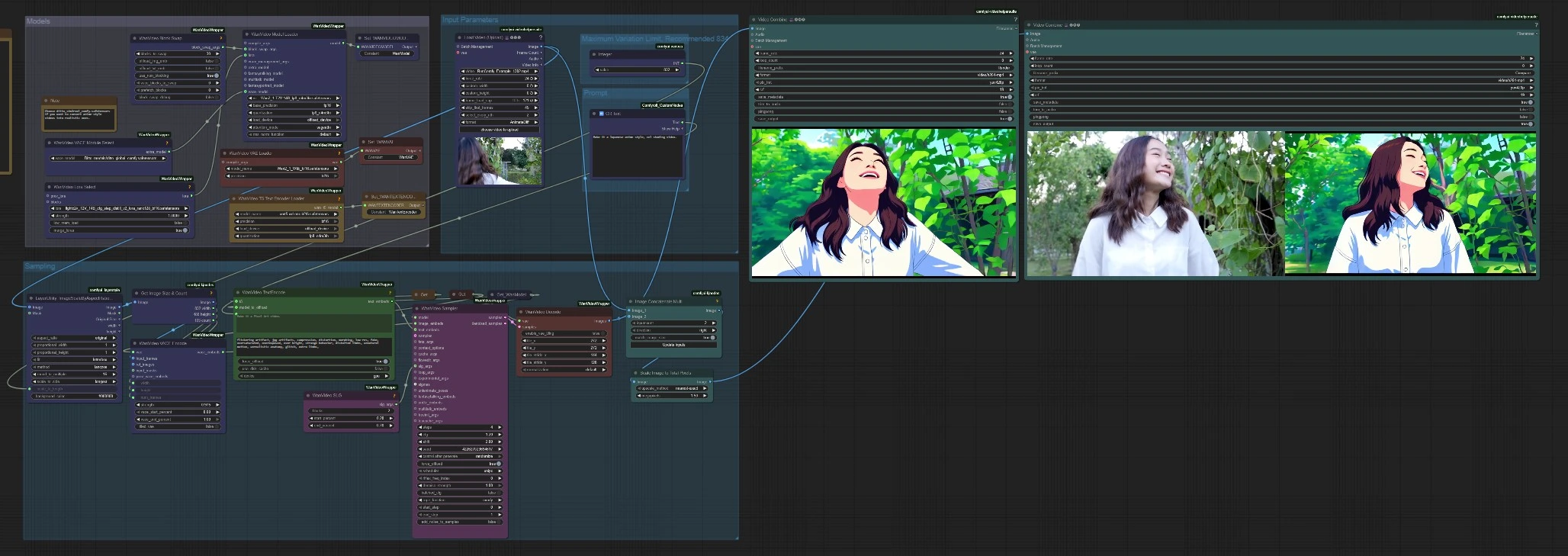
워크플로우는 네 단계로 실행됩니다: 모델 로드, 입력 비디오 준비, 텍스트 및 시각적 인코딩, 샘플링 및 내보내기. 그룹은 순서대로 작동하여 스타일화된 렌더링과 선택적 나란히 비교를 생성합니다.
모델#
이 그룹은 Wan 2.1 Ditto에 필요한 모든 것을 준비합니다. 기본 백본은 WanVideoModelLoader (#130)로 로드되고 WanVideoVAELoader (#60) 및 LoadWanVideoT5TextEncoder (#80)와 쌍을 이룹니다. Ditto 구성 요소는 WanVideoVACEModelSelect (#128)로 선택되어 백본을 전용 Ditto 스타일화 가중치로 지정합니다. 강력한 변형이 필요하면 WanVideoLoraSelect (#122)로 LoRA를 부착할 수 있습니다. 메모리 관리를 위한 WanVideoBlockSwap (#68)이 있어 제한된 VRAM에서 더 큰 모델을 부드럽게 실행할 수 있습니다.
입력 매개변수#
소스 클립을 VHS_LoadVideo (#101)로 로드합니다. 그런 다음 프레임은 LayerUtility: ImageScaleByAspectRatio V2 (#76)를 사용하여 일관된 기하학을 위해 크기가 조정되며, 이는 단순한 정수 입력 JWInteger (#89)로 제어되는 긴면 해상도를 목표로 합니다. GetImageSizeAndCount (#65)는 준비된 프레임을 읽고 너비, 높이 및 프레임 수를 다운스트림 노드로 전달하여 Wan 2.1 Ditto가 올바른 공간 크기와 지속 시간을 샘플링하도록 합니다. 프롬프트를 자체 필드에서 작성하기를 원하는 경우 작은 프롬프트 도우미 CR Text (#104)가 포함되어 있습니다. "최대 변동 제한"이라는 제목의 그룹은 일관된 결과와 안정적인 메모리 사용을 위해 긴면 픽셀 목표를 실용적인 범위 내로 유지하도록 상기시켜 줍니다.
샘플링#
조건화는 두 개의 병렬 레인에서 발생합니다. WanVideoTextEncode (#111)는 프롬프트를 의도와 스타일을 정의하는 텍스트 임베딩으로 변환합니다. WanVideoVACEEncode (#126)는 편집을 위해 구조와 모션을 유지하는 시각적 임베딩으로 준비된 비디오를 인코딩합니다. 선택적 가이드 모듈 WanVideoSLG (#129)는 모델이 스타일과 콘텐츠를 디노이징 경로를 통해 균형 잡는 방식을 제어합니다. 그런 다음 WanVideoSampler (#119)는 Wan 2.1 백본을 Ditto, 텍스트 임베딩 및 시각적 임베딩과 융합하여 스타일화된 잠재 변수를 생성합니다. 마지막으로 WanVideoDecode (#87)는 잠재 변수에서 프레임을 재구성하여 Wan 2.1 Ditto로 알려진 시간적 일관성이 있는 스타일화된 시퀀스를 생성합니다.
출력 및 비교#
기본 내보내기는 VHS_VideoCombine (#95)를 사용하여 선택한 프레임 속도로 Wan 2.1 Ditto 렌더링을 저장합니다. 빠른 검토를 위해 그래프는 ImageConcatMulti (#94)를 사용하여 원본 및 스타일화된 프레임을 결합하고, ImageScaleToTotalPixels (#133)로 비교 크기를 조정하고, VHS_VideoCombine (#100)을 통해 나란히 영화를 작성합니다. 보통 두 개의 비디오를 출력 폴더에서 받게 됩니다: 깨끗한 스타일의 렌더링과 이해 관계자가 승인하거나 더 빨리 반복할 수 있도록 돕는 비교 클립.
프롬프트 아이디어#
짧고 명확한 프롬프트로 시작하고 반복할 수 있습니다. Wan 2.1 Ditto와 잘 어울리는 예:
- 일본 애니메이션 스타일, 셀 셰이딩 비디오로 만드세요.
- 픽셀 아트 비디오로 만드세요.
- 연필 스케치 스타일 비디오로 만드세요.
- 클레이메이션 비디오로 만드세요.
- 수채화 스타일 비디오로 만드세요.
- 기어, 파이프 및 황동 세부 사항이 있는 스팀펑크 스타일로 만드세요.
- 네온과 미래적 임플란트가 있는 사이버펑크 스타일로 만드세요.
- 우키요에 스타일 비디오로 만드세요.
- 르네상스 아트 스타일 비디오로 만드세요.
- 반 고흐의 그림으로 만드세요.
- LEGO 스타일로 변환하세요.
- 지브리 스타일로 변환하세요.
- 3D 치비 스타일로 변환하세요.
- 종이 자르기 스타일로 변환하세요.
Comfyui Wan 2.1 Ditto 워크플로우의 주요 노드#
WanVideoVACEModelSelect (#128) 스타일화를 위해 사용할 Ditto 가중치를 선택합니다. 기본 글로벌 Ditto 모델은 대부분의 영상에 균형 잡힌 선택입니다. 목표가 애니메이션-실제 변환이라면, 노드 노트에서 참조된 시뮬레이션-실제 Ditto 변형을 선택하십시오. Ditto 변형을 전환하면 다른 설정을 건드리지 않고 리스타일의 특성이 변경됩니다.
WanVideoVACEEncode (#126) 입력 프레임에서 시각적 조건을 구축합니다. 주요 컨트롤은 width, height, num_frames이며, 이는 준비된 비디오와 일치해야 최상의 결과를 얻을 수 있습니다. strength를 사용하여 Ditto 스타일이 편집에 어떻게 영향을 미치는지를 조정하고, vace_start_percent 및 vace_end_percent를 사용하여 확산 경로 전반에 걸쳐 조건이 적용되는 시점을 제한합니다. 매우 큰 해상도에서는 메모리 압력을 줄이기 위해 tiled_vae를 활성화하십시오.
WanVideoTextEncode (#111) mT5-XXL 인코더를 통해 긍정적 및 부정적 프롬프트를 인코딩하여 스타일과 콘텐츠를 안내합니다. 긍정적 프롬프트는 간결하고 설명적으로 유지하고, 부정적 프롬프트를 사용하여 깜빡임이나 과포화와 같은 아티팩트를 억제하십시오. force_offload 및 device 옵션을 사용하여 큰 모델을 실행할 때 메모리 대신 속도를 교환할 수 있습니다.
WanVideoSampler (#119) Wan 2.1 백본을 Ditto 스타일화와 함께 실행하여 최종 잠재 변수를 생성합니다. 가장 영향력 있는 설정은 steps, cfg, scheduler, seed입니다. 원래 구조를 더 많이 보존하고 싶을 때는 denoise_strength를 사용하고, slg_args를 연결하여 콘텐츠 충실도와 스타일 강도를 균형 있게 유지하십시오. 세부 사항을 개선하려면 단계나 가이던스를 증가시키되, 시간 비용이 있을 수 있습니다.
ImageScaleByAspectRatio V2 (#76) 조건화 전에 모든 프레임의 안정적인 대상 크기를 설정합니다. 독립형 정수로 긴면 대상을 조정하여 작고 빠른 미리보기를 테스트하고 최종 렌더링을 위해 해상도를 늘릴 수 있습니다. A/B 비교를 의미 있게 만들기 위해 반복 간에 스케일을 일관되게 유지하십시오.
VHS_LoadVideo (#101) 및 VHS_VideoCombine (#95, #100) 이 노드는 디코딩 및 인코딩을 처리합니다. 타이밍이 중요한 경우 소스와 프레임 속도를 일치시키십시오. 탐색 중에 비교 작가는 유용하며, 최종 내보내기에서는 스타일화된 결과만 원할 경우 비활성화할 수 있습니다.
선택적 추가 기능#
- 애니메이션-실제 편집을 위해 샘플링 전에
WanVideoVACEModelSelect에서 시뮬레이션-실제 Ditto 변형을 선택하십시오. - "수채화 스타일로 만들어주세요"와 같은 짧은 프롬프트로 시작하고 1 또는 2개의 설명자로 정제하십시오. 긴 목록은 스타일 강도를 희석하는 경향이 있습니다.
- 강한 룩을 밀어낼 때 깜빡임, 압축 아티팩트 및 과도한 밝은 하이라이트를 줄이기 위해 부정적 프롬프트를 사용하십시오.
- 반복 간에 긴면 해상도를 일관되게 유지하여 결과를 안정화하고 시드를 재현 가능하게 만드십시오.
- VRAM이 부족할 때는 모델 오프로드 및 타일링 옵션을 활성화하거나 전체 크기로 렌더링하기 전에 긴면 값을 작게 미리보기하십시오.
이 Wan 2.1 Ditto 워크플로우는 깨끗한 프롬프트, 일관된 모션, 즉각적인 검토 또는 전달 준비가 된 출력을 통해 고품질 비디오 리스타일링을 예측 가능하고 빠르게 만듭니다.
감사의 말#
이 워크플로우는 다음 작업 및 리소스를 구현하고 기반으로 합니다. 우리는 그들의 기여와 유지 관리를 위해 EzioBy에게 감사드립니다. 권위 있는 세부 사항은 아래 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- EzioBy/Wan 2.1 Ditto Source
- GitHub: EzioBy/Ditto
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 각각의 라이선스 및 약관에 따릅니다.
