
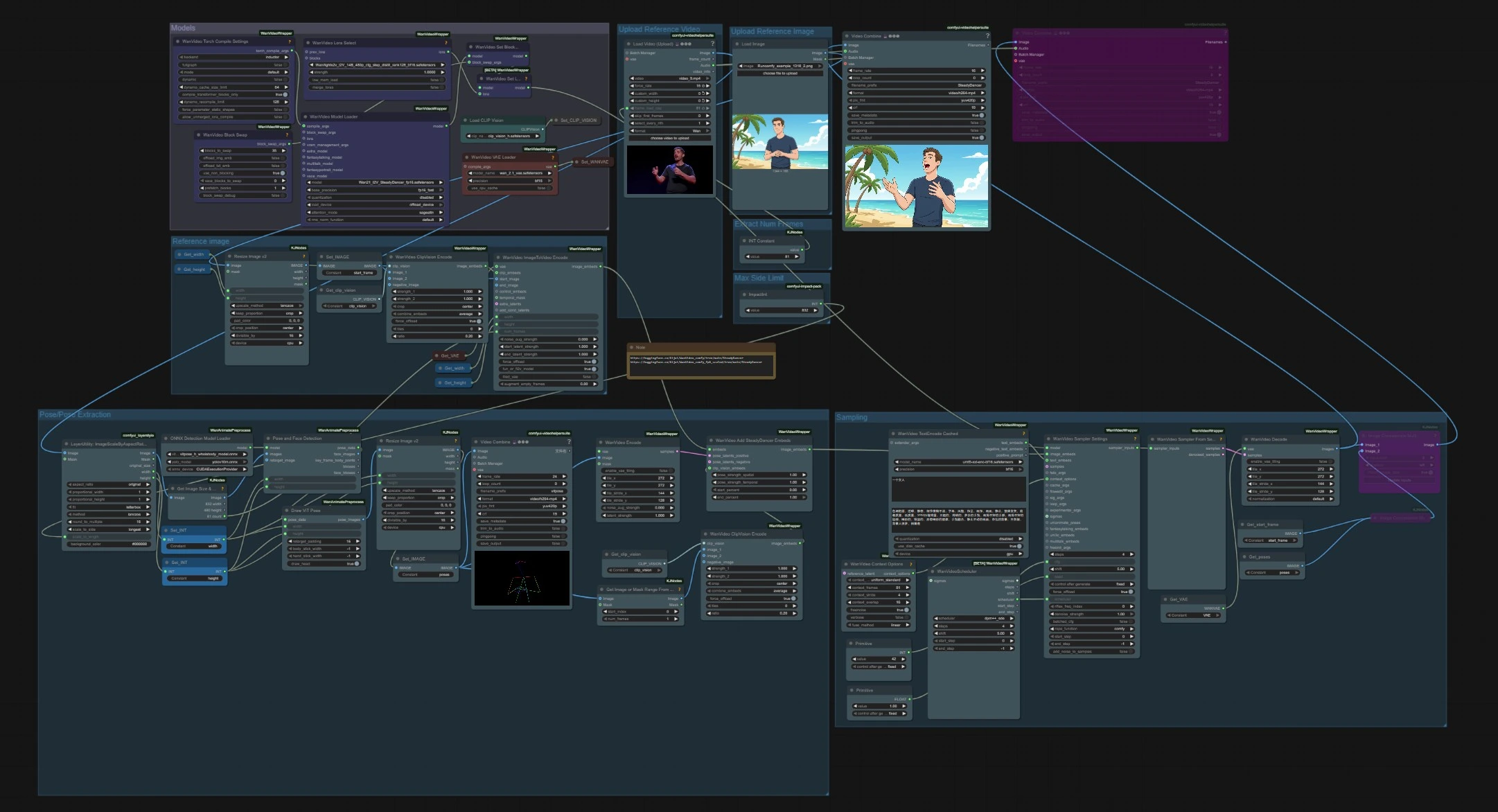
SteadyDancer 이미지-비디오 자세 애니메이션 워크플로우#
이 ComfyUI 워크플로우는 단일 참조 이미지를 별도의 자세 소스의 동작에 의해 구동되는 일관된 비디오로 변환합니다. SteadyDancer의 이미지-비디오 패러다임을 중심으로 구축되었으며, 첫 번째 프레임은 입력 이미지의 정체성과 외형을 유지하는 반면, 나머지 시퀀스는 목표 동작을 따릅니다. 이 그래프는 SteadyDancer 전용 임베드 및 자세 파이프라인을 통해 자세와 외형을 조화시켜 강한 시간적 일관성을 가진 부드럽고 현실적인 전신 움직임을 생성합니다.
SteadyDancer는 인간 애니메이션, 춤 생성 및 캐릭터 또는 초상화를 생동감 있게 만드는 데 이상적입니다. 정지 이미지 하나와 동작 클립을 제공하면 ComfyUI 파이프라인이 자세 추출, 임베딩, 샘플링 및 디코딩을 처리하여 공유할 준비가 된 비디오를 제공합니다.
Comfyui SteadyDancer 워크플로우의 주요 모델#
- SteadyDancer. Condition‑Reconciliation Mechanism과 Synergistic Pose Modulation을 사용하는 정체성 보존 이미지-비디오 연구 모델입니다. 여기서는 핵심 I2V 방법으로 사용됩니다. GitHub
- Wan 2.1 I2V SteadyDancer 가중치. ComfyUI에 포팅된 체크포인트로 Wan 2.1 스택에서 SteadyDancer를 구현합니다. Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) 및 Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE. 파이프라인 내에서 잠재 인코딩 및 디코딩에 사용되는 비디오 VAE입니다. 위의 Hugging Face의 WanVideo 포트에 포함되어 있습니다.
- OpenCLIP CLIP ViT‑H/14. 참조 이미지에서 강력한 외형 임베딩을 추출하는 비전 인코더입니다. Hugging Face
- ViTPose‑H WholeBody (ONNX). 본체, 손, 얼굴에 사용되는 고품질 키포인트 모델로, 구동 자세 시퀀스를 유도합니다. GitHub
- YOLOv10 (ONNX). 다양한 비디오에서 포즈 추정 전에 사람 위치를 개선하는 탐지기입니다. GitHub
- umT5‑XXL 인코더. 참조 이미지와 함께 스타일 또는 장면 지침을 위한 선택적 텍스트 인코더입니다. Hugging Face
Comfyui SteadyDancer 워크플로우 사용 방법#
워크플로우에는 샘플링에서 만나는 두 개의 독립적인 입력이 있습니다: 정체성을 위한 참조 이미지와 동작을 위한 구동 비디오입니다. 모델은 초기에 한 번 로드되며, 자세는 구동 클립에서 추출되고 SteadyDancer 임베드는 생성 및 디코딩 전에 자세와 외형을 블렌딩합니다.
모델#
이 그룹은 그래프 전체에서 사용되는 핵심 가중치를 로드합니다. WanVideoModelLoader (#22)는 Wan 2.1 I2V SteadyDancer 체크포인트를 선택하고 주의 및 정밀도 설정을 처리합니다. WanVideoVAELoader (#38)는 비디오 VAE를 제공하고, CLIPVisionLoader (#59)는 CLIP ViT‑H 비전 백본을 준비합니다. 고급 사용자를 위한 메모리 동작 변경 또는 추가 가중치 부착을 위한 LoRA 선택 노드 및 BlockSwap 옵션이 있습니다.
참조 비디오 업로드#
VHS_LoadVideo (#75)를 사용하여 동작 소스를 가져옵니다. 이 노드는 프레임과 오디오를 읽고 목표 프레임 속도를 설정하거나 프레임 수를 제한할 수 있습니다. 클립은 춤이나 스포츠 동작과 같은 모든 인간 동작일 수 있습니다. 비디오 스트림은 비율 조정 및 자세 추출로 흐릅니다.
프레임 수 추출#
구동 비디오에서 로드되는 프레임 수를 제어하는 간단한 상수입니다. 이는 자세 추출과 생성된 SteadyDancer 출력의 길이를 제한합니다. 더 긴 시퀀스를 위해 증가시키거나 더 빠르게 반복하기 위해 줄이십시오.
최대 측면 제한#
LayerUtility: ImageScaleByAspectRatio V2 (#146)는 모델의 스트라이드 및 메모리 예산에 맞도록 비율을 유지하면서 프레임을 스케일링합니다. GPU 및 원하는 세부 수준에 적합한 긴 측면 제한을 설정하십시오. 스케일링된 프레임은 다운스트림 탐지 노드에서 사용되며 출력 크기의 참조로 사용됩니다.
자세/자세 추출#
스케일링된 프레임에서 인물 탐지 및 자세 추정이 실행됩니다. PoseAndFaceDetection (#89)은 YOLOv10 및 ViTPose‑H를 사용하여 사람과 키포인트를 강력하게 찾습니다. DrawViTPose (#88)는 동작의 깔끔한 스틱 피규어 표현을 렌더링하고 ImageResizeKJv2 (#77)는 생성 캔버스와 맞추기 위해 결과 자세 이미지를 크기 조정합니다. WanVideoEncode (#72)는 자세 이미지를 잠재로 변환하여 SteadyDancer가 외형 신호와 싸우지 않고 동작을 조절할 수 있게 합니다.
참조 이미지 업로드#
SteadyDancer가 애니메이션화할 정체성 이미지를 로드합니다. 이미지에는 움직이려는 주제가 명확하게 표시되어야 합니다. 가장 충실한 전송을 위해 구동 비디오와 대략 일치하는 자세와 카메라 각도를 사용하십시오. 프레임은 임베딩을 위한 참조 이미지 그룹으로 전달됩니다.
참조 이미지#
정지 이미지는 ImageResizeKJv2 (#68)로 크기 조정되고 Set_IMAGE (#96)를 통해 시작 프레임으로 등록됩니다. WanVideoClipVisionEncode (#65)는 정체성, 의상, 대략적인 레이아웃을 보존하는 CLIP ViT‑H 임베딩을 추출합니다. WanVideoImageToVideoEncode (#63)는 시작 프레임과 함께 너비, 높이 및 프레임 수를 패킹하여 SteadyDancer의 I2V 조건을 준비합니다.
샘플링#
이곳에서 외형과 동작이 만나 비디오를 생성합니다. WanVideoAddSteadyDancerEmbeds (#71)는 WanVideoImageToVideoEncode로부터 이미지 조건을 받고 포즈 잠재 및 CLIP‑비전 참조와 함께 보강하여 SteadyDancer의 조건 조화를 가능하게 합니다. 시간적 일관성을 위해 WanVideoContextOptions (#87)에서 컨텍스트 윈도우 및 중첩을 설정합니다. 선택적으로 WanVideoTextEncodeCached (#92)는 스타일 지침을 위한 umT5 텍스트 지침을 추가합니다. WanVideoSamplerSettings (#119) 및 WanVideoSamplerFromSettings (#129)은 Wan 2.1 모델에서 실제 디노이징 단계를 실행한 후 WanVideoDecode (#28)가 잠재를 다시 RGB 프레임으로 변환합니다. 최종 비디오는 VHS_VideoCombine (#141, #83)으로 저장됩니다.
Comfyui SteadyDancer 워크플로우의 주요 노드#
WanVideoAddSteadyDancerEmbeds (#71)#
이 노드는 그래프의 SteadyDancer의 핵심입니다. 이미지 조건을 포즈 잠재 및 CLIP‑비전 신호와 융합하여 첫 번째 프레임이 정체성을 고정하고 동작이 자연스럽게 펼쳐지도록 합니다. pose_strength_spatial을 조정하여 사지가 감지된 골격을 얼마나 밀접하게 따르는지를 제어하고 pose_strength_temporal을 통해 시간이 지남에 따라 동작의 부드러움을 조절합니다. 더 자연스러운 인트로와 아웃트로를 위해 시퀀스 내 포즈 제어가 적용되는 위치를 제한하려면 start_percent 및 end_percent를 사용하십시오.
PoseAndFaceDetection (#89)#
구동 비디오에서 YOLOv10 감지 및 ViTPose‑H 키포인트 추정을 실행합니다. 작은 사지나 얼굴이 누락된 경우, 업스트림에서 입력 해상도를 늘리거나 가려짐이 적고 조명이 깨끗한 영상을 선택하십시오. 여러 사람이 있는 경우, 대상 주제를 프레임에서 가장 크게 유지하여 탐지기 및 자세 헤드가 안정적으로 유지되도록 합니다.
VHS_LoadVideo (#75)#
사용할 동작 소스의 일부를 제어합니다. 더 긴 출력을 위해 프레임 캡을 늘리거나 빠르게 프로토타이핑하려면 줄이십시오. force_rate 입력은 생성 속도와 자세 간격을 정렬하여 원본 클립의 FPS가 비정상적일 때 스터터를 줄이는 데 도움이 될 수 있습니다.
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
비율을 유지하면서 선택한 긴 측면 제한 내에서 프레임을 유지하고 나눌 수 있는 크기로 버킷화합니다. 여기서 스케일을 생성 캔버스와 일치시켜 SteadyDancer가 업샘플링하거나 과도하게 자르지 않도록 하십시오. 부드러운 결과나 가장자리 아티팩트가 보이면 모델의 기본 훈련 스케일에 더 가까운 긴 측면으로 가져와 깨끗한 디코드를 얻으십시오.
WanVideoSamplerSettings (#119)#
Wan 2.1 샘플러의 디노이징 계획을 정의합니다. scheduler 및 steps는 전반적인 품질 대비 속도를 설정하며, cfg는 이미지와 프롬프트에 대한 충실도와 다양성 간의 균형을 맞춥니다. seed는 재현성을 잠그고, denoise_strength는 참조 이미지의 외형에 더 가깝게 유지하려 할 때 낮출 수 있습니다.
WanVideoModelLoader (#22)#
Wan 2.1 I2V SteadyDancer 체크포인트를 로드하고 정밀도, 주의 구현 및 장치 배치를 처리합니다. 안정성을 위해 구성된 상태로 두십시오. 고급 사용자는 I2V LoRA를 부착하여 동작 동작을 변경하거나 실험할 때 계산 비용을 줄일 수 있습니다.
선택적 추가 기능#
- 명확하고 조명이 잘 된 참조 이미지를 선택하십시오. 구동 비디오의 카메라와 비슷한 전면 또는 약간 각진 뷰가 SteadyDancer가 정체성을 더 신뢰할 수 있게 보존하도록 합니다.
- 단일 두드러진 주제와 최소한의 가려짐이 있는 동작 클립을 선호하십시오. 바쁜 배경이나 빠른 컷은 자세의 안정성을 감소시킵니다.
- 손과 발이 흔들리는 경우
WanVideoAddSteadyDancerEmbeds에서 자세 시간 강도를 약간 증가시키거나 비디오 FPS를 높여 자세를 밀집시키십시오. - 더 긴 장면의 경우, 겹치는 컨텍스트로 세그먼트로 처리하고 출력을 연결하십시오. 이렇게 하면 메모리 사용이 합리적이고 시간적 연속성이 유지됩니다.
- 내장된 미리보기 모자이크를 사용하여 설정을 조정하는 동안 생성된 프레임을 시작 프레임 및 자세 시퀀스와 비교하십시오.
이 SteadyDancer 워크플로우는 하나의 정지 이미지에서 정체성을 첫 번째 프레임부터 보존하는 충실한 자세 기반 비디오로의 실용적인 엔드 투 엔드 경로를 제공합니다.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 이를 기반으로 구축되었습니다. 우리는 MCG-NJU에게 SteadyDancer에 대한 기여와 유지 관리에 대해 감사드립니다. 공식 세부 사항은 아래에 연결된 원본 문서 및 리포지토리를 참조하십시오.
리소스#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
참고: 참조된 모델, 데이터셋 및 코드는 저자 및 유지 관리자가 제공한 해당 라이선스 및 조건에 따라 사용됩니다.

