
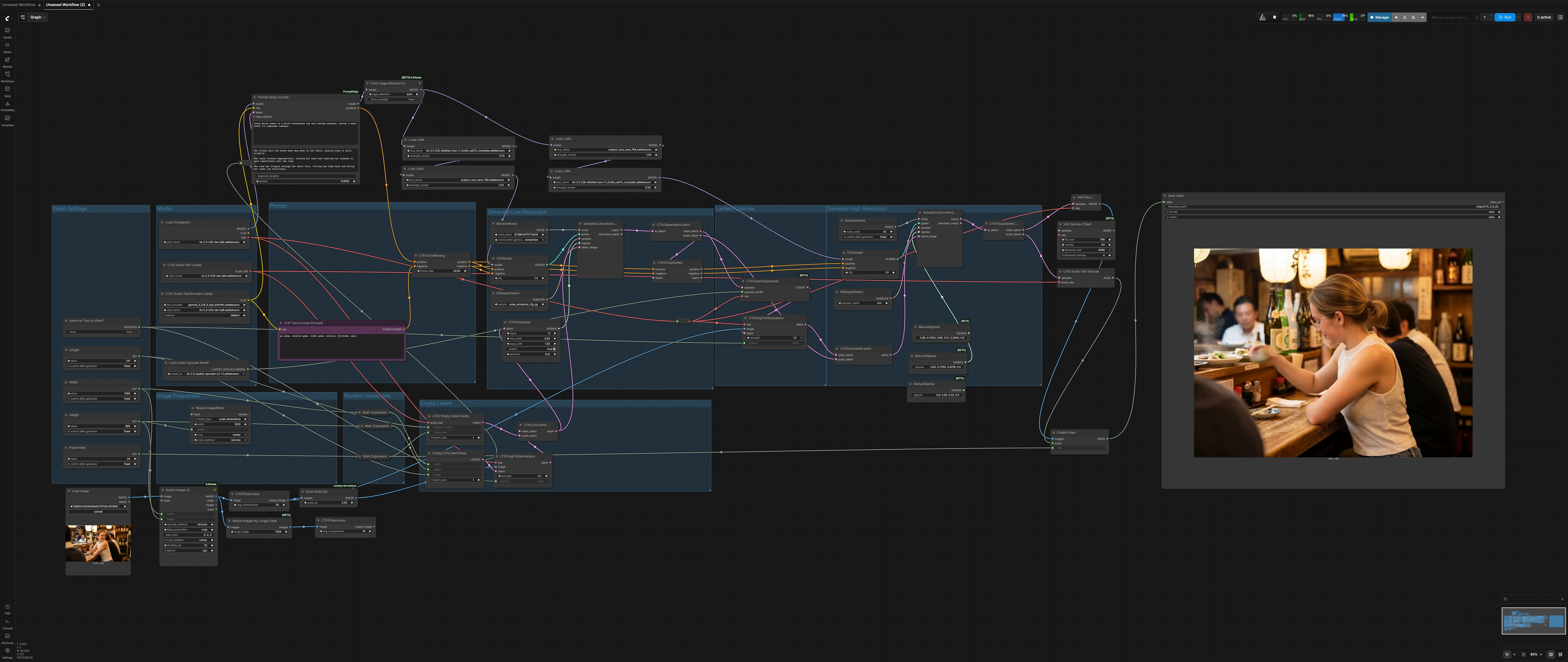
LTX 2.3 Sulphur 이미지에서 비디오로의 워크플로우: 제어 가능한 모션을 가진 시네마틱 이미지에서 비디오로#
이 LTX 2.3 Sulphur 이미지에서 비디오로의 워크플로우는 단일 정지 이미지를 자연스러운 미세 표현, 신뢰할 수 있는 캐릭터 움직임 및 안정적인 분위기 연속성을 갖춘 게시 준비가 완료된 시네마틱 샷으로 변환합니다. 카메라 느낌, 분위기 및 장면 역학을 제어하고 싶으면서 설정 세부 사항에 빠지지 않도록 하는 스토리텔링 샷을 위해 특별히 설계되었습니다.
워크플로우는 LTX-2.3을 중심으로 두 단계의 확산 파이프라인을 실행합니다: 모션과 타이밍을 설정하기 위한 저해상도 패스, 최종 디테일을 위한 잠재적인 업스케일 및 고해상도 정제 패스가 뒤따릅니다. Sulphur 스타일 LoRA는 외관과 피부 톤을 조정하고, 프롬프트 세분화는 샷 전반에 걸쳐 비트의 진화를 지원합니다. 필요에 따라 클래식 이미지에서 비디오로 또는 순수 텍스트에서 비디오로 전환하는 단일 스위치를 전환하십시오.
Comfyui LTX 2.3 Sulphur 이미지에서 비디오로의 워크플로우의 주요 모델#
- Lightricks LTX-2.3-22B dev FP8. 메모리 사용을 실용적으로 유지하면서 생성 및 디코딩을 주도하는 기본 비디오 확산 체크포인트. Model card
- LTX-2.3 Spatial Upscaler x2. 패스 간에 모션을 보존하면서 공간 충실도를 추가하기 위해 사용되는 잠재적 초고해상도 모델. Model page
- Gemma 3 12B instruction-tuned text encoder packaged for LTX-2. 글로벌 및 세그먼트 프롬프트에 대한 풍부하고 근거 있는 조건을 가능하게 합니다. Repository
- Sulphur 스타일 LoRA 및 LTX-2.3 증류된 LoRA 1.1. 프롬프트 제어를 유지하면서 얼굴 현실감과 시네마틱 톤을 안정화하는 페어링된 LoRA.
Comfyui LTX 2.3 Sulphur 이미지에서 비디오로의 워크플로우 사용 방법#
전체 흐름: 샷 크기와 길이를 설정하고, 정지 이미지를 준비하고, 글로벌 프롬프트 및 선택적 로컬 프롬프트 비트를 정의한 후 렌더링하십시오. 저해상도 단계는 모션과 타이밍을 구축하고, 잠재적 업스케일러는 디테일을 높이며, 고해상도 단계는 텍스처와 조명을 마무리하고 MP4로 디코딩합니다.
비디오 설정#
목표 Width, Height, Length (프레임) 및 Frame Rate를 선택하십시오. 차원은 일반적인 확산 그리드 크기로 나누어져 아티팩트를 피할 수 있도록 설정됩니다. 단일 불리언, Switch to Text to Video? (#28)은 정지 이미지가 삽입되거나 우회되는지 제어합니다. 특히 얼굴과 손의 깨끗한 구도를 위해 입력 이미지와 일치하는 가로세로 비율을 유지하십시오.
이미지 전처리#
소스 정지 이미지는 로드되고, 크기가 조정되고, ImageResizeKJv2 (#75) 및 LTXVPreprocess (#76)를 사용하여 확산 준비를 위해 가볍게 압축됩니다. 확장된 버전은 안정적인 모션 시딩을 위한 저해상도 패스로 제공되며, 더 높은 디테일 버전은 고해상도 패스에 제공됩니다. 이 섹션을 사용하여 생성 전에 구도와 여백을 맞추십시오. 여기에서의 미세한 사전 자르기 조정은 더 일관된 눈 선과 배경 연속성에 도움이 됩니다.
빈 잠재적#
EmptyLTXVLatentVideo (#21) 및 LTXVEmptyLatentAudio (#33)는 샷 설정을 사용하여 동기화된 비디오 및 오디오 잠재적을 구성합니다. LTXVConcatAVLatent (#32)에 의해 통합되어 다운스트림 노드가 정제할 타임라인 골조를 설정합니다. 오디오 브랜치는 최종 MP4가 어디서나 안정적으로 재생되도록 무음의 유효한 트랙을 생성합니다. 이러한 잠재적은 또한 프롬프트 세그먼트를 고정하여 모션 변경이 예상되는 위치에 도달하게 합니다.
프롬프트#
PromptRelayEncode (#80)에 샷 설명을 작성하십시오. 전체 외관을 위한 간결한 글로벌 프롬프트를 사용한 후, | 문자로 구분된 비트별 라인을 로컬 프롬프트로 추가하여 클립 전반에 걸쳐 마이크로 액션을 발전시킵니다. LTXAVTextEncoderLoader (#5)의 LTX 텍스트 인코더는 의미를 처리하고, CLIPTextEncode (#41)는 강력한 현실주의 지향의 네거티브 프롬프트를 제공합니다. LTXVConditioning (#31)은 긍정적 및 부정적 조건을 혼합하고 프레임 속도와 동기화합니다.
모델#
CheckpointLoaderSimple (#44)은 LTX-2.3 베이스를 로드합니다. PathchSageAttentionKJ (#67)는 큰 이미지를 위한 주의를 최적화합니다. 짧은 LoRA 체인은 각 샘플링 단계 전에 Sulphur 스타일과 증류된 안정성 LoRA를 적용합니다. 이 디자인은 프롬프트 반응성과 외관 일관성을 균형 있게 유지하여 패스 간에 캐릭터 정체성과 조명이 일관되게 유지됩니다.
저해상도 생성#
이 첫 번째 확산 패스는 모션을 설정합니다. LTXVImgToVideoInplace (#22)는 준비된 정지 이미지를 타임라인에 삽입합니다; Switch to Text to Video?가 활성화된 경우, bypass 입력은 이미지 삽입을 깔끔하게 비활성화하여 순수 T2V를 위해 이미지 삽입을 비활성화합니다. LTXVScheduler (#47)는 모션 진폭과 시간적 부드러움을 제어하기 위해 시그마 스케줄을 형성합니다. CFGGuider (#42) 및 KSamplerSelect (#17)에 의해 구동되는 SamplerCustomAdvanced (#9)는 일관된 저해상도 A/V 잠재적을 합성합니다. 그런 다음 LTXVSeparateAVLatent (#35)는 비디오 및 오디오 경로를 분리하고 LTXVCropGuides (#10)에 구도 인식을 위한 프레임 정보를 전달합니다.
잠재적 업스케일#
LTXVLatentUpsampler (#13)는 LTX-2.3 Spatial Upscaler와 함께 잠재적 공간에서 공간적 디테일을 높이면서 첫 번째 패스에서 학습된 모션을 보존합니다. 여기서 업스케일링은 타이밍을 재발명하지 않으면서 흔히 두 번째 패스 재생성에서 발생하는 플리커를 줄입니다. 그것은 최종 정제 단계에 더 날카롭고 모션 일관된 잠재적을 전달합니다.
고해상도 생성#
정제된 단계는 LTXVConcatAVLatent (#3)를 통해 업스케일된 비디오 잠재적과 오디오 잠재적을 다시 결합합니다. CFGGuider (#8) 및 KSamplerSelect (#6)는 튜닝된 시그마 스케줄을 사용하여 SamplerCustomAdvanced (#36)에서 빠르고 디테일 지향적인 샘플러를 조종합니다. 이미지 삽입을 활성화 상태로 두었다면, 두 번째 LTXVImgToVideoInplace (#14)는 모델이 고해상도에서 정지를 준수하도록 도와주면서 이미 설정된 모션을 잃지 않도록 도와줍니다. 결과는 자연스러운 눈과 입의 역동성을 가진 안정적이고 시네마틱한 시퀀스입니다.
출력#
VAEDecode (#68)는 최종 비디오 잠재적을 프레임으로 변환하고, LTXVAudioVAEDecode (#23)는 무음 오디오 트랙을 재구성합니다. CreateVideo (#38)는 선택한 프레임 속도에서 프레임과 오디오를 믹싱하고, SaveVideo (#45)는 즉시 검토 및 공유할 수 있는 H.264 MP4를 작성합니다. 각 샷에 대해 설명적인 파일 이름 접두사를 사용하여 반복을 정리하십시오.
숫자 변환#
작은 유틸리티 블록은 잠재적 구성의 반 스케일 크기를 계산하여 VRAM과 속도를 관리합니다. 일반적으로 이를 조정할 필요는 없지만, 업스트림 너비와 높이가 모든 것을 일관되게 구동하도록 보장합니다. 기본 해상도를 변경하면 자동으로 적응합니다.
Comfyui LTX 2.3 Sulphur 이미지에서 비디오로의 워크플로우의 주요 노드#
PromptRelayEncode(#80). 타임라인에 맞춰 글로벌 프롬프트와 비트별 로컬 프롬프트를 중앙 집중화합니다. 샷 전반에 걸쳐 미세한 표현과 작은 카메라 공개를 스크립트하는 데 사용하십시오. 로컬 프롬프트를 짧고 구체적으로 유지하여 글로벌 외관과 싸우지 않고 보완하도록 하십시오.LTXVImgToVideoInplace(#22, #14). 저해상도 및 고해상도 잠재적에 정지 이미지를 삽입합니다. 참조 프레임에 단단히 맞추기를 원할 때strength를 증가시키고, 더 많은 자유를 위해 이를 줄이십시오.bypass입력은 Text-to-Video 스위치에 연결되어 있어 T2V 실행 시 이미지 삽입을 깔끔하게 비활성화할 수 있습니다.LTXVScheduler(#47). 저해상도 패스 동안 노이즈 레벨이 어떻게 진화하는지를 제어하여 모션 강도와 부드러움에 직접적인 영향을 미칩니다. 과도하게 활동적인 샷을 억제하거나 정적일 때 미세한 밀어내기를 추가하는 데 사용하십시오. 여기에서의 조정은 얼굴, 머리카락 및 손으로 들고 있는 것 같은 카메라 에너지에서 가장 눈에 띕니다.LTXVLatentUpsampler(#13). LTX의 공간 업스케일러를 사용하여 x2 잠재적 업스케일링을 수행하여 첫 번째 패스에서 학습된 모션 큐를 보존합니다. 여기에서 업스케일링을 사용하여 고해상도 정제 전에 선명한 질감과 가장자리 정의를 추가하면서 타이밍을 다시 조정하지 않습니다.CFGGuider(#42, #8). 모델이 프롬프트를 따르는 정도와 학습된 사전과의 균형을 맞춥니다. 얼굴이 떠다니거나 스타일이 약해지면 가이던스를 올리고, 디테일이 과도하게 강요되거나 플라스틱처럼 보이면 줄이십시오. 현실성을 유지하기 위해 네거티브 프롬프트를 빠르게 살펴보면서 변경 사항을 조정하십시오.KSamplerSelect(#17, #6). 단계별 샘플링 알고리즘을 선택할 수 있게 합니다. 저해상도 패스에 대해 강력하고 표현력 있는 샘플러를 선호하고, 마무리 패스에 대해 빠르고 디테일 친화적인 옵션을 선택하십시오. 외관을 비교할 때 반복 간 일관성을 유지하십시오.
선택적 추가 기능#
- 의도적인 카메라 동작을 위해, 일관된 측면 푸시가 필요할 때 LTX 가족의 Dolly-Left와 같은 카메라 제어 LoRA를 LoRA 로더 체인에 추가할 수 있습니다. Model page
- 잠재적 작업의 잘못된 정렬을 방지하고 VRAM 효율성을 유지하기 위해 너비와 높이를 32로 나누어 떨어지도록 유지하십시오.
- 로컬 프롬프트에서 짧고 활동적인 동사를 사용하여 비트를 안무하십시오. 예를 들어, 그립을 조이고, 고개를 돌리고, 미소를 부드럽게 합니다.
- 매우 높은 출력 크기를 목표로 할 경우,
VAEDecode를VAEDecodeTiled(#43)로 교체하여 메모리를 더 효율적으로 사용하여 프레임을 디코딩하십시오. - 얼굴이 가장 중요한 경우, 샘플러 또는 해상도를 변경하기 전에 프롬프트 텍스트와
CFGGuider만 조정하여 반복하십시오. 이는 비교를 의미 있게 유지하고 LTX 2.3 Sulphur 이미지에서 비디오로의 워크플로우에 대한 최상의 워딩을 드러냅니다.
감사의 말씀#
이 워크플로우는 다음 작업 및 리소스를 구현하고 발전시킵니다. 우리는 워크플로우 참조에 대한 RunningHub, LTX 2.3 가족(모델, 공간 업스케일러 및 카메라 제어 LoRA)을 위한 Lightricks, LTX 텍스트 인코더를 위한 Comfy-Org의 기여와 유지 관리를 감사하게 생각합니다. 권위 있는 세부 사항에 대해서는 아래 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- RunningHub/RunningHub 워크플로우 참조
- 문서 / 릴리스 노트: runninghub.ai post
- Lightricks/LTX 2.3 모델 소스
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX 2.3 공간 업스케일러 소스
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX 카메라 제어 LoRA 소스
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/LTX 텍스트 인코더 소스
- Hugging Face: Comfy-Org/ltx-2
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이선스 및 조건에 따릅니다.
