
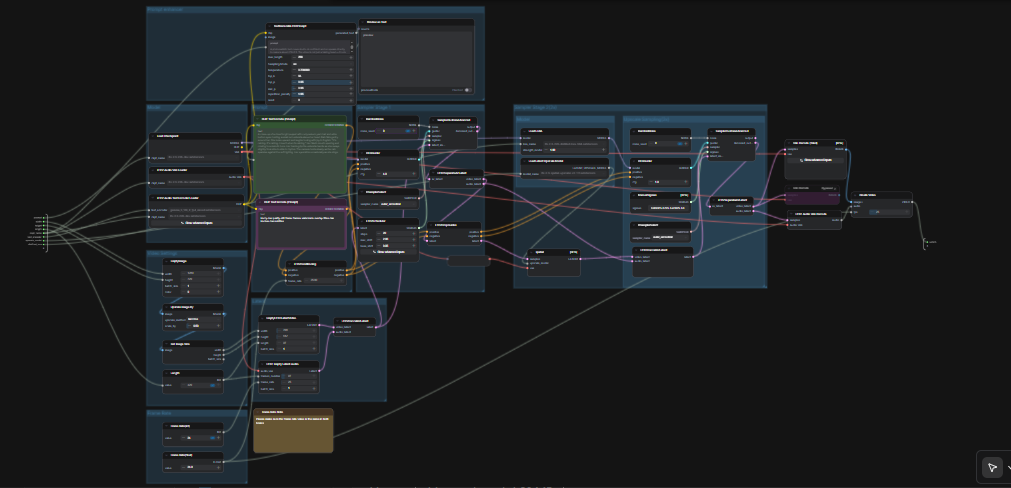
LTX 2.3 ComfyUI: 텍스트에서 비디오로, 깨끗한 오디오, 두 단계 샘플링 및 2× 공간 업스케일링#
이 LTX 2.3 ComfyUI 워크플로우는 짧은 프롬프트를 정교한 시네마틱 비디오로 변환하며, 동기화된 오디오를 제공합니다. Lightricks의 LTX‑2.3 모델을 중심으로 구축되어 높은 시각적 일관성, 안정적인 모션 및 방송 친화적인 출력을 구성합니다. 창작자, 편집자 및 기술 아티스트는 단일 프롬프트로 오디오가 포함된 MP4를 원스텝으로 생성할 수 있으며, 프롬프트 강화기, 두 단계 샘플링 및 2× 잠재 업스케일러가 포함된 간소화된 그래프를 사용합니다.
일반적인 텍스트‑비디오 설정과 비교하여 이 그래프는 장면 일관성과 프롬프트 충실성을 강조합니다. 기본 경로는 AV 잠재를 생성하고, 잠재 공간에서 상세도를 높이기 위해 업스케일한 후, 프레임과 오디오로 디코딩하여 공유 준비가 된 비디오 파일로 패키징합니다. 현대의 오픈 소스 비디오 모델을 탐색 중이라면, 이 LTX 2.3 ComfyUI 워크플로우는 제작 품질의 모션을 얻는 빠른 방법입니다.
Comfyui LTX 2.3 ComfyUI 워크플로우의 주요 모델#
- LTX‑2.3 22B (dev) 체크포인트 by Lightricks. 높은 일관성의 모션과 강한 장면 일관성을 생성하는 핵심 텍스트‑비디오 모델입니다. Hugging Face • GitHub
- Gemma 3 12B Instruct 텍스트 인코더 (FP4 혼합). 프롬프트 기반을 강화하고 풍부한 장면 세부 정보를 제공하는 강력한 언어 이해를 제공합니다. Hugging Face
- LTX‑2.3 Spatial Upscaler x2 1.0. 모션 일관성을 해치지 않고 공간 세부 사항을 선명하게 하는 잠재 공간 업스케일러입니다. Hugging Face
- LTX‑2.3 22B Distilled LoRA (384). 업스케일/정제 단계 동안 텍스처 충실도를 개선하고 스타일을 안정화하는 증류 어댑터입니다. Hugging Face
- LTX Audio VAE. 동일한 프롬프트에서 깨끗하고 동기화된 사운드 생성을 가능하게 하는 LTX‑2.3과 짝지어진 오디오 모듈입니다. Hugging Face
Comfyui LTX 2.3 ComfyUI 워크플로우 사용 방법#
그래프는 두 번의 조정된 패스를 실행합니다. 먼저 프롬프트로 작업 해상도에서 AV 잠재를 생성합니다. 그런 다음 2× 잠재 업스케일을 수행하고 증류된 LoRA와 두 번째 샘플링 패스를 수행한 후 프레임과 오디오로 디코딩하여 최종적으로 MP4로 합성합니다.
프롬프트 강화기#
TextGenerateLTX2Prompt (#149) 노드는 평범한 언어를 모델 친화적인 프롬프트로 재작성하여 동작, 시각적 단서 및 오디오 큐를 포함합니다. 장면 설명을 제공하세요; 프레임이나 스타일에 대한 지침이 필요할 때는 선택적으로 참조 이미지를 연결할 수 있습니다. 생성된 텍스트는 긍정 인코더로 라우팅되며, 품질 중심의 부정 프롬프트는 아티팩트를 줄입니다. 이 균형은 LTX‑2.3 모델이 창의성을 과도하게 제한하지 않고 요약을 유지하는 데 도움을 줍니다.
모델#
CheckpointLoaderSimple (#146)은 LTX‑2.3 22B 체크포인트를 로드하고 모델과 VAE를 모두 노출합니다. LTXAVTextEncoderLoader (#147)은 워크플로우에서 긍정 및 부정 조건부를 위해 사용하는 Gemma 3 12B Instruct 텍스트 인코더를 불러옵니다. 다른 LTX 변형을 테스트하는 것이 아니라면 이 선택을 유지하세요. 나머지 그래프는 이 쌍을 위해 조정되었습니다.
비디오 설정#
해상도와 지속 시간은 가벼운 이미지 스캐폴드와 Length 컨트롤로 설정됩니다. 그래프는 이미지 크기를 읽고 작업 해상도로 스케일링하며, 그 값을 비디오 잠재 생성기로 전달합니다. LTX 모델은 스트라이드 제약이 있으므로 32‑스트라이드 패턴을 따르는 크기와 모델의 프레임 주기에 맞는 길이를 유지하세요. 그래프는 불법 값을 가장 가까운 유효 값으로 조정하지만, 유효한 크기를 선택하면 최상의 구성을 제공합니다.
프레임 레이트#
두 개의 작은 컨트롤이 조건부 및 최종 인코딩을 위한 FPS를 설정합니다: Frame Rate(int) (#141) 및 Frame Rate(float) (#140). 모션 타이밍 및 오디오 정렬이 파이프라인 전반에 걸쳐 일관되도록 동일하게 유지하세요. 부드러운 모션을 원하거나 소셜 형식을 대상으로 할 때 플랫폼 기본값을 맞추세요.
잠재#
EmptyLTXVLatentVideo (#121)은 비디오 잠재를 초기화하고 LTXVEmptyLatentAudio (#119)는 오디오를 동일하게 초기화합니다. LTXVConcatAVLatent (#122)는 텍스트 가이드가 두 모달리티를 함께 조정할 수 있도록 단일 AV 잠재로 병합합니다. LTXVConditioning (#120)은 긍정 및 부정 조건부를 부착하고, LTXVCropGuides (#115)는 잠재의 공간 레이아웃에 대한 지침을 조정하여 더 신뢰할 수 있는 프레이밍을 제공합니다.
샘플러 단계 1#
이 단계는 RandomNoise (#151), KSamplerSelect (#144), 및 LTX‑인식 LTXVScheduler (#112)와 CFGGuider (#139)를 사용하여 초기 AV 잠재를 생성합니다. 스케줄러는 시간적 안정성과 프롬프트 준수를 균형 있게 유지하기 위해 LTX에 맞춤화되었습니다. 더 많은 변화를 원한다면 노이즈 시드를 변경하세요; 스크립트에 대한 충실한 준수를 원한다면 시간적 일관성을 유지하는 샘플러를 선호하세요.
모델 (LoRA)#
LoraLoaderModelOnly (#143)은 정제 전에 LTX‑2.3 증류 LoRA를 적용합니다. 이 어댑터는 텍스처 마무리와 스타일 충실도를 미세하게 개선하여 모션 일관성을 잃지 않습니다. 피부, 직물 및 반사 하이라이트에서 가장 두드러집니다.
업스케일 샘플링 (2×)#
LTXVLatentUpsampler (#130)는 로드된 LatentUpscaleModelLoader (#114) 및 기본 VAE를 사용하여 잠재 공간에서 2× 공간 업스케일을 수행합니다. 업스케일이 디코딩 전에 발생하기 때문에 시간적 부드러움을 유지하면서 세밀한 공간 세부 사항을 얻을 수 있습니다. 업스케일된 비디오 및 오디오 잠재는 LTXVConcatAVLatent (#129)와 함께 재결합되어 정제 패스를 수행합니다.
샘플러 단계 2 (2×)#
두 번째 패스는 RandomNoise (#127), KSamplerSelect (#145) 및 ManualSigmas 스케줄 (#113)과 CFGGuider (#116)를 사용하여 업스케일된 잠재를 정제합니다. 이 단계는 미세 세부 사항과 가장자리 선명도를 최종 조정하는 곳입니다. LoRA가 활성화되고 텍스처와 조명에 대해 구체적인 프롬프트일 때 가장 잘 작동합니다.
디코딩 및 출력#
LTXVSeparateAVLatent (#135)은 정제된 잠재를 분리하여 VAEDecodeTiled (#137)이 프레임을 재구성하는 동안 LTXVAudioVAEDecode (#138)는 오디오를 복원합니다. CreateVideo (#133)는 선택된 FPS에서 프레임과 오디오를 합성하고, 상위 수준의 SaveVideo 노드는 워크플로우의 비디오 폴더에 MP4를 작성합니다. 결과는 LTX 2.3 ComfyUI 파이프라인 내에서 완전히 생성된 깨끗하고 공유 준비가 된 파일입니다.
Comfyui LTX 2.3 ComfyUI 워크플로우의 주요 노드#
TextGenerateLTX2Prompt(#149): 모션, 시각적 속성 및 오디오를 포괄하는 구조화된 프롬프트로 간단한 설명을 변환합니다. 이야기의 비트나 페이싱을 조정할 때 여기에서 문구를 조정하세요; 일반적으로 샘플러 조정보다 큰 개선을 가져옵니다.LTXVScheduler(#112): 시간이 지남에 따라 노이즈가 제거되는 방식을 형성하는 LTX‑특정 스케줄러입니다. 선택한 샘플러와 신중하게 짝지어 시간적 안정성과 프롬프트 충실성을 균형 있게 유지하세요.LTXVLatentUpsampler(#130): 잠재 공간에서 직접 2× 공간 업스케일을 수행하여 모션 연속성을 유지하면서 선명한 세부 사항을 추가합니다. 디코딩 후 업스케일러에 의존하지 않고 더 선명한 결과를 원할 때 사용하세요.LoraLoaderModelOnly(#143): 정제를 위해 LTX‑2.3 증류 LoRA를 적용합니다. 스타일 제어를 더욱 강화하려면 영향력을 증가시키고, 기본 모델의 더 넓은 외관을 원한다면 줄이세요.CreateVideo(#133): 선택된 FPS에서 생성된 오디오와 디코딩된 프레임을 합성하여 타이밍과 립 싱크를 유지합니다. FPS를 변경하면 두 프레임 속도 제어를 일치시키세요.
선택적 추가#
- 프롬프트 팁: 시간 경과에 따른 동작, 주요 시각적 요소를 나열하고 기대하는 소리나 대화를 명시하세요. 명확하고 간결한 표현은 LTX‑2.3 인코더에 최상의 신호를 제공합니다.
- 크기 및 길이: 32‑스트라이드 크기 및 모델의 프레임 주기를 존중하는 길이를 선호하세요. 그래프는 근접 값을 자동으로 조정하지만, 유효한 입력은 구성을 개선하고 미세한 떨림을 줄입니다.
- 빠른 반복: 같은 프롬프트와 설정을 유지하면서 변형을 탐색하기 위해 실행 간
RandomNoise시드를 변경하세요. - 모델 스위칭: 기본값은 LTX‑2.3 22B와 Gemma 3 12B IT 및 2× 공간 업스케일러에 맞춰져 있습니다. 각 조건부 및 디코딩에 어떤 영향을 미치는지 이해하는 경우에만 모델을 교체하세요.
감사의 말#
이 워크플로우는 다음 작업과 리소스를 구현하고 기반으로 합니다. 우리는 Lightricks의 LTX-2.3 모델과 EyeForAILabs의 YouTube 튜토리얼에 대한 기여와 유지를 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: YouTube Channel from @eyeforailabs
참고: 참조된 모델, 데이터 세트 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이선스 및 조건에 따릅니다.